 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHERMES: A Holistic End-to-End Risk-Aware Multimodal Embodied System with Vision-Language Models for Long-Tail Autonomous Driving
Feb 01, 2026End-to-end autonomous driving models increasingly benefit from large vision--language models for semantic understanding, yet ensuring safe and accurate operation under long-tail conditions remains challenging. These challenges are particularly prominent in long-tail mixed-traffic scenarios, where autonomous vehicles must interact with heterogeneous road users, including human-driven vehicles and vulnerable road users, under complex and uncertain conditions. This paper proposes HERMES, a holistic risk-aware end-to-end multimodal driving framework designed to inject explicit long-tail risk cues into trajectory planning. HERMES employs a foundation-model-assisted annotation pipeline to produce structured Long-Tail Scene Context and Long-Tail Planning Context, capturing hazard-centric cues together with maneuver intent and safety preference, and uses these signals to guide end-to-end planning. HERMES further introduces a Tri-Modal Driving Module that fuses multi-view perception, historical motion cues, and semantic guidance, ensuring risk-aware accurate trajectory planning under long-tail scenarios. Experiments on the real-world long-tail dataset demonstrate that HERMES consistently outperforms representative end-to-end and VLM-driven baselines under long-tail mixed-traffic scenarios. Ablation studies verify the complementary contributions of key components.
Graph2Eval: Automatic Multimodal Task Generation for Agents via Knowledge Graphs
Oct 01, 2025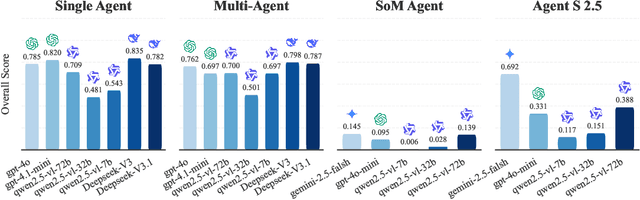
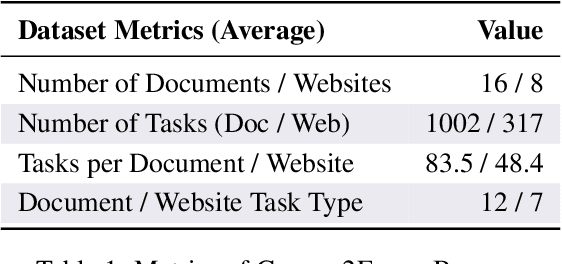
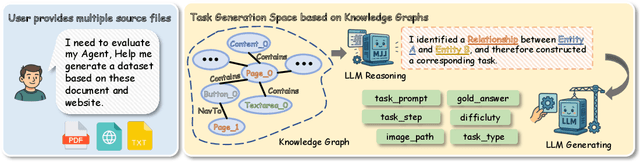
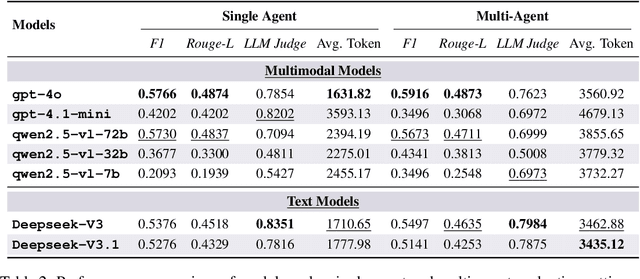
As multimodal LLM-driven agents continue to advance in autonomy and generalization, evaluation based on static datasets can no longer adequately assess their true capabilities in dynamic environments and diverse tasks. Existing LLM-based synthetic data methods are largely designed for LLM training and evaluation, and thus cannot be directly applied to agent tasks that require tool use and interactive capabilities. While recent studies have explored automatic agent task generation with LLMs, most efforts remain limited to text or image analysis, without systematically modeling multi-step interactions in web environments. To address these challenges, we propose Graph2Eval, a knowledge graph-based framework that automatically generates both multimodal document comprehension tasks and web interaction tasks, enabling comprehensive evaluation of agents' reasoning, collaboration, and interactive capabilities. In our approach, knowledge graphs constructed from multi-source external data serve as the task space, where we translate semantic relations into structured multimodal tasks using subgraph sampling, task templates, and meta-paths. A multi-stage filtering pipeline based on node reachability, LLM scoring, and similarity analysis is applied to guarantee the quality and executability of the generated tasks. Furthermore, Graph2Eval supports end-to-end evaluation of multiple agent types (Single-Agent, Multi-Agent, Web Agent) and measures reasoning, collaboration, and interaction capabilities. We instantiate the framework with Graph2Eval-Bench, a curated dataset of 1,319 tasks spanning document comprehension and web interaction scenarios. Experiments show that Graph2Eval efficiently generates tasks that differentiate agent and model performance, revealing gaps in reasoning, collaboration, and web interaction across different settings and offering a new perspective for agent evaluation.
Towards Adaptive ML Benchmarks: Web-Agent-Driven Construction, Domain Expansion, and Metric Optimization
Sep 11, 2025Recent advances in large language models (LLMs) have enabled the emergence of general-purpose agents for automating end-to-end machine learning (ML) workflows, including data analysis, feature engineering, model training, and competition solving. However, existing benchmarks remain limited in task coverage, domain diversity, difficulty modeling, and evaluation rigor, failing to capture the full capabilities of such agents in realistic settings. We present TAM Bench, a diverse, realistic, and structured benchmark for evaluating LLM-based agents on end-to-end ML tasks. TAM Bench features three key innovations: (1) A browser automation and LLM-based task acquisition system that automatically collects and structures ML challenges from platforms such as Kaggle, AIcrowd, and Biendata, spanning multiple task types and data modalities (e.g., tabular, text, image, graph, audio); (2) A leaderboard-driven difficulty modeling mechanism that estimates task complexity using participant counts and score dispersion, enabling scalable and objective task calibration; (3) A multi-dimensional evaluation framework incorporating performance, format compliance, constraint adherence, and task generalization. Based on 150 curated AutoML tasks, we construct three benchmark subsets of different sizes -- Lite, Medium, and Full -- designed for varying evaluation scenarios. The Lite version, with 18 tasks and balanced coverage across modalities and difficulty levels, serves as a practical testbed for daily benchmarking and comparative studies.
Toward Rich Video Human-Motion2D Generation
Jun 17, 2025

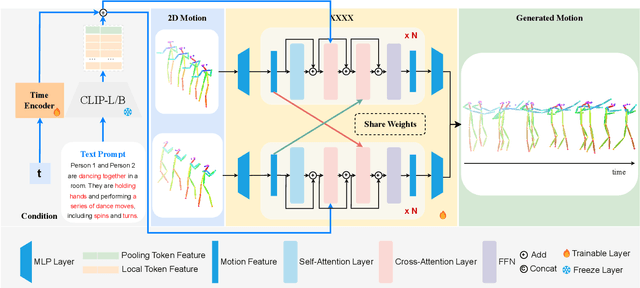

Generating realistic and controllable human motions, particularly those involving rich multi-character interactions, remains a significant challenge due to data scarcity and the complexities of modeling inter-personal dynamics. To address these limitations, we first introduce a new large-scale rich video human motion 2D dataset (Motion2D-Video-150K) comprising 150,000 video sequences. Motion2D-Video-150K features a balanced distribution of diverse single-character and, crucially, double-character interactive actions, each paired with detailed textual descriptions. Building upon this dataset, we propose a novel diffusion-based rich video human motion2D generation (RVHM2D) model. RVHM2D incorporates an enhanced textual conditioning mechanism utilizing either dual text encoders (CLIP-L/B) or T5-XXL with both global and local features. We devise a two-stage training strategy: the model is first trained with a standard diffusion objective, and then fine-tuned using reinforcement learning with an FID-based reward to further enhance motion realism and text alignment. Extensive experiments demonstrate that RVHM2D achieves leading performance on the Motion2D-Video-150K benchmark in generating both single and interactive double-character scenarios.
PowerAttention: Exponentially Scaling of Receptive Fields for Effective Sparse Attention
Mar 05, 2025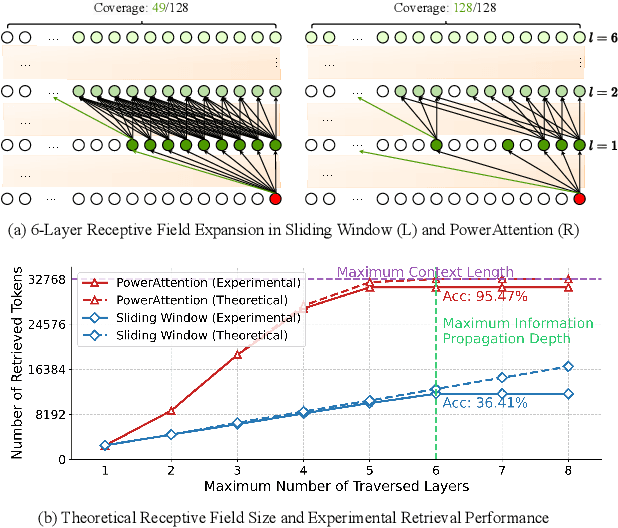
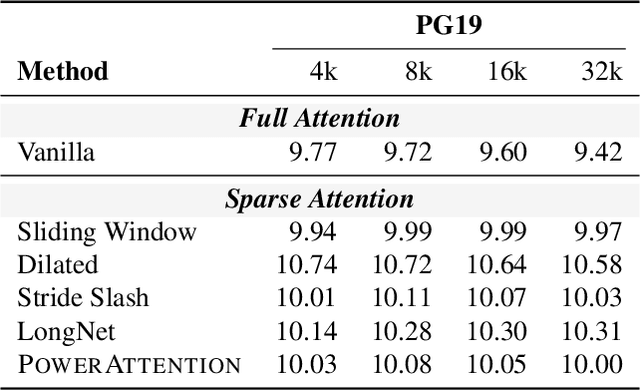
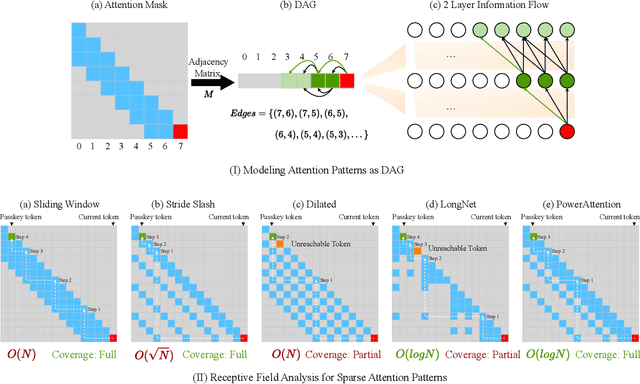
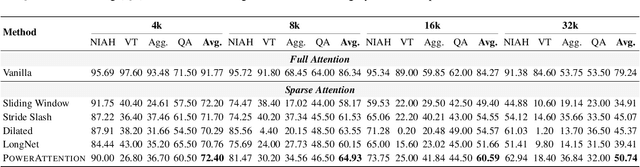
Large Language Models (LLMs) face efficiency bottlenecks due to the quadratic complexity of the attention mechanism when processing long contexts. Sparse attention methods offer a promising solution, but existing approaches often suffer from incomplete effective context and/or require complex implementation of pipeline. We present a comprehensive analysis of sparse attention for autoregressive LLMs from the respective of receptive field, recognize the suboptimal nature of existing methods for expanding the receptive field, and introduce PowerAttention, a novel sparse attention design that facilitates effective and complete context extension through the theoretical analysis. PowerAttention achieves exponential receptive field growth in $d$-layer LLMs, allowing each output token to attend to $2^d$ tokens, ensuring completeness and continuity of the receptive field. Experiments demonstrate that PowerAttention outperforms existing static sparse attention methods by $5\sim 40\%$, especially on tasks demanding long-range dependencies like Passkey Retrieval and RULER, while maintaining a comparable time complexity to sliding window attention. Efficiency evaluations further highlight PowerAttention's superior speedup in both prefilling and decoding phases compared with dynamic sparse attentions and full attention ($3.0\times$ faster on 128K context), making it a highly effective and user-friendly solution for processing long sequences in LLMs.
I-MCTS: Enhancing Agentic AutoML via Introspective Monte Carlo Tree Search
Feb 21, 2025



Recent advancements in large language models (LLMs) have shown remarkable potential in automating machine learning tasks. However, existing LLM-based agents often struggle with low-diversity and suboptimal code generation. While recent work has introduced Monte Carlo Tree Search (MCTS) to address these issues, limitations persist in the quality and diversity of thoughts generated, as well as in the scalar value feedback mechanisms used for node selection. In this study, we introduce Introspective Monte Carlo Tree Search (I-MCTS), a novel approach that iteratively expands tree nodes through an introspective process that meticulously analyzes solutions and results from parent and sibling nodes. This facilitates a continuous refinement of the node in the search tree, thereby enhancing the overall decision-making process. Furthermore, we integrate a Large Language Model (LLM)-based value model to facilitate direct evaluation of each node's solution prior to conducting comprehensive computational rollouts. A hybrid rewarding mechanism is implemented to seamlessly transition the Q-value from LLM-estimated scores to actual performance scores. This allows higher-quality nodes to be traversed earlier. Applied to the various ML tasks, our approach demonstrates a 6% absolute improvement in performance compared to the strong open-source AutoML agents, showcasing its effectiveness in enhancing agentic AutoML systems. Resource available at https://github.com/jokieleung/I-MCTS
MultiLingPoT: Enhancing Mathematical Reasoning with Multilingual Program Fine-tuning
Dec 17, 2024



Program-of-Thought (PoT), which aims to use programming language instead of natural language as an intermediate step in reasoning, is an important way for LLMs to solve mathematical problems. Since different programming languages excel in different areas, it is natural to use the most suitable language for solving specific problems. However, current PoT research only focuses on single language PoT, ignoring the differences between different programming languages. Therefore, this paper proposes an multilingual program reasoning method, MultiLingPoT. This method allows the model to answer questions using multiple programming languages by fine-tuning on multilingual data. Additionally, prior and posterior hybrid methods are used to help the model select the most suitable language for each problem. Our experimental results show that the training of MultiLingPoT improves each program's mathematical reasoning by about 2.5\%. Moreover, with proper mixing, the performance of MultiLingPoT can be further improved, achieving a 6\% increase compared to the single-language PoT with the data augmentation.Resources of this paper can be found at https://github.com/Nianqi-Li/MultiLingPoT.
QUILL: Quotation Generation Enhancement of Large Language Models
Nov 06, 2024



While Large language models (LLMs) have become excellent writing assistants, they still struggle with quotation generation. This is because they either hallucinate when providing factual quotations or fail to provide quotes that exceed human expectations. To bridge the gap, we systematically study how to evaluate and improve LLMs' performance in quotation generation tasks. We first establish a holistic and automatic evaluation system for quotation generation task, which consists of five criteria each with corresponding automatic metric. To improve the LLMs' quotation generation abilities, we construct a bilingual knowledge base that is broad in scope and rich in dimensions, containing up to 32,022 quotes. Moreover, guided by our critiria, we further design a quotation-specific metric to rerank the retrieved quotations from the knowledge base. Extensive experiments show that our metrics strongly correlate with human preferences. Existing LLMs struggle to generate desired quotes, but our quotation knowledge base and reranking metric help narrow this gap. Our dataset and code are publicly available at https://github.com/GraceXiaoo/QUILL.
SEGMENT+: Long Text Processing with Short-Context Language Models
Oct 09, 2024



There is a growing interest in expanding the input capacity of language models (LMs) across various domains. However, simply increasing the context window does not guarantee robust performance across diverse long-input processing tasks, such as understanding extensive documents and extracting detailed information from lengthy and noisy data. In response, we introduce SEGMENT+, a general framework that enables LMs to handle extended inputs within limited context windows efficiently. SEGMENT+ utilizes structured notes and a filtering module to manage information flow, resulting in a system that is both controllable and interpretable. Our extensive experiments across various model sizes, focusing on long-document question-answering and Needle-in-a-Haystack tasks, demonstrate the effectiveness of SEGMENT+ in improving performance.
Teaching Large Language Models to Express Knowledge Boundary from Their Own Signals
Jun 16, 2024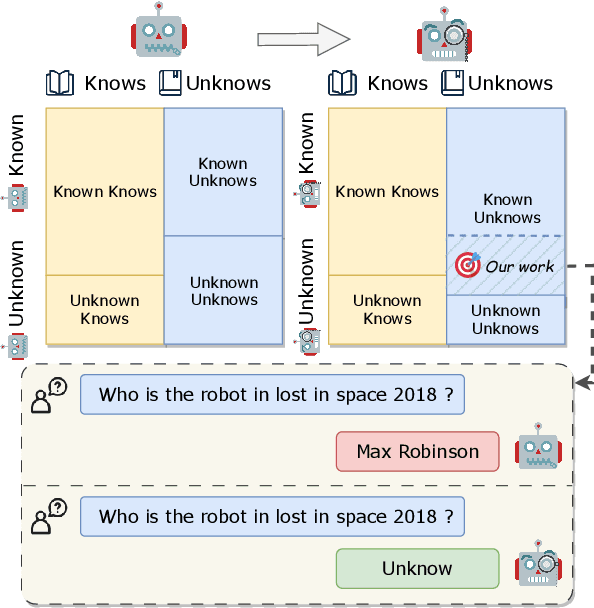
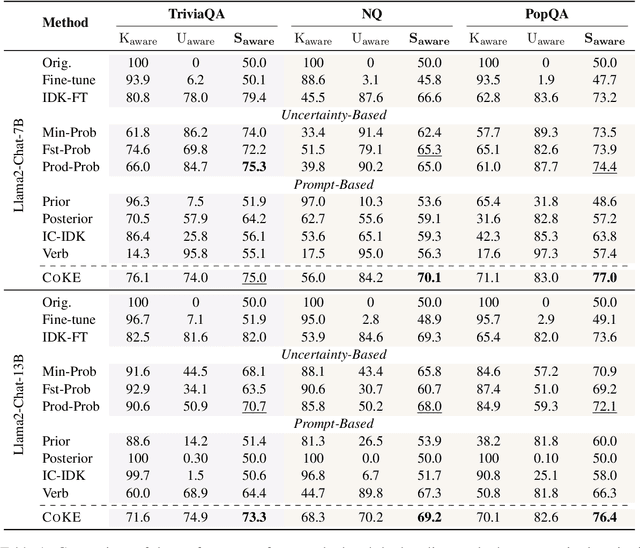
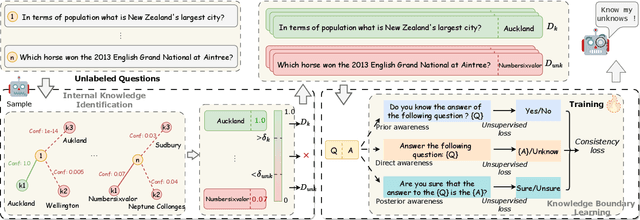
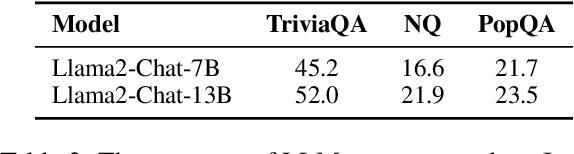
Large language models (LLMs) have achieved great success, but their occasional content fabrication, or hallucination, limits their practical application. Hallucination arises because LLMs struggle to admit ignorance due to inadequate training on knowledge boundaries. We call it a limitation of LLMs that they can not accurately express their knowledge boundary, answering questions they know while admitting ignorance to questions they do not know. In this paper, we aim to teach LLMs to recognize and express their knowledge boundary, so they can reduce hallucinations caused by fabricating when they do not know. We propose CoKE, which first probes LLMs' knowledge boundary via internal confidence given a set of questions, and then leverages the probing results to elicit the expression of the knowledge boundary. Extensive experiments show CoKE helps LLMs express knowledge boundaries, answering known questions while declining unknown ones, significantly improving in-domain and out-of-domain performance.