 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwitter Bot Detection Using Bidirectional Long Short-term Memory Neural Networks and Word Embeddings
Feb 03, 2020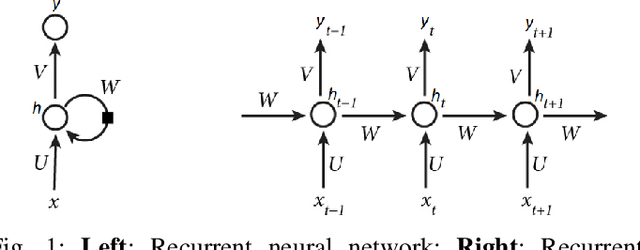
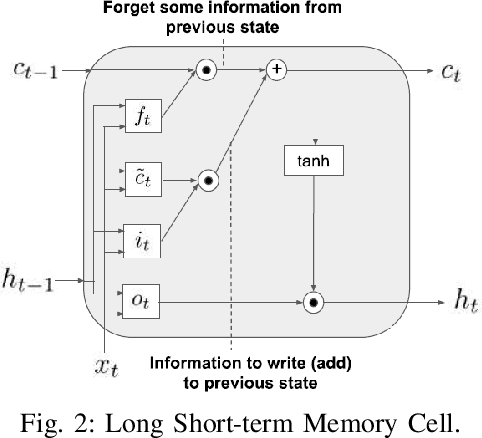
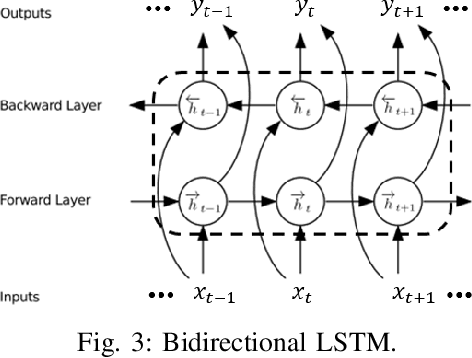
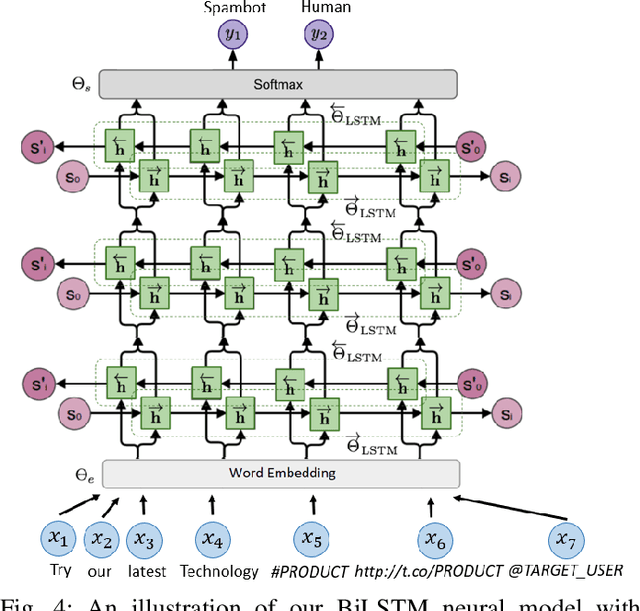
Twitter is a web application playing dual roles of online social networking and micro-blogging. The popularity and open structure of Twitter have attracted a large number of automated programs, known as bots. Legitimate bots generate a large amount of benign contextual content, i.e., tweets delivering news and updating feeds, while malicious bots spread spam or malicious contents. To assist human users in identifying who they are interacting with, this paper focuses on the classification of human and spambot accounts on Twitter, by employing recurrent neural networks, specifically bidirectional Long Short-term Memory (BiLSTM), to efficiently capture features across tweets. To the best of our knowledge, our work is the first that develops a recurrent neural model with word embeddings to distinguish Twitter bots from human accounts, that requires no prior knowledge or assumption about users' profiles, friendship networks, or historical behavior on the target account. Moreover, our model does not require any handcrafted features. The preliminary simulation results are very encouraging. Experiments on the cresci-2017 dataset show that our approach can achieve competitive performance compared with existing state-of-the-art bot detection systems.
Dual-FOFE-net Neural Models for Entity Linking with PageRank
Jul 30, 2019

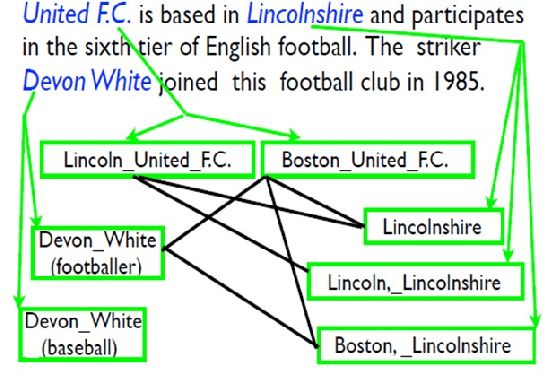
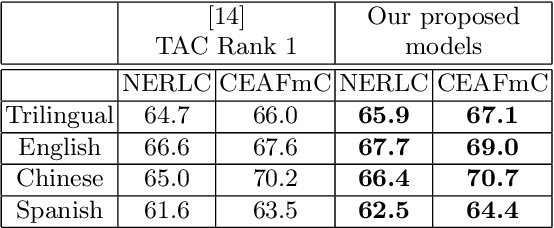
This paper presents a simple and computationally efficient approach for entity linking (EL), compared with recurrent neural networks (RNNs) or convolutional neural networks (CNNs), by making use of feedforward neural networks (FFNNs) and the recent dual fixed-size ordinally forgetting encoding (dual-FOFE) method to fully encode the sentence fragment and its left/right contexts into a fixed-size representation. Furthermore, in this work, we propose to incorporate PageRank based distillation in our candidate generation module. Our neural linking models consist of three parts: a PageRank based candidate generation module, a dual-FOFE-net neural ranking model and a simple NIL entity clustering system. Experimental results have shown that our proposed neural linking models achieved higher EL accuracy than state-of-the-art models on the TAC2016 task dataset over the baseline system, without requiring any in-house data or complicated handcrafted features. Moreover, it achieves a competitive accuracy on the TAC2017 task dataset.