 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUMEM: Unified Memory Extraction and Management Framework for Generalizable Memory
Feb 11, 2026Self-evolving memory serves as the trainable parameters for Large Language Models (LLMs)-based agents, where extraction (distilling insights from experience) and management (updating the memory bank) must be tightly coordinated. Existing methods predominately optimize memory management while treating memory extraction as a static process, resulting in poor generalization, where agents accumulate instance-specific noise rather than robust memories. To address this, we propose Unified Memory Extraction and Management (UMEM), a self-evolving agent framework that jointly optimizes a Large Language Model to simultaneous extract and manage memories. To mitigate overfitting to specific instances, we introduce Semantic Neighborhood Modeling and optimize the model with a neighborhood-level marginal utility reward via GRPO. This approach ensures memory generalizability by evaluating memory utility across clusters of semantically related queries. Extensive experiments across five benchmarks demonstrate that UMEM significantly outperforms highly competitive baselines, achieving up to a 10.67% improvement in multi-turn interactive tasks. Futhermore, UMEM maintains a monotonic growth curve during continuous evolution. Codes and models will be publicly released.
MUSE: Multi-Scale Dense Self-Distillation for Nucleus Detection and Classification
Nov 07, 2025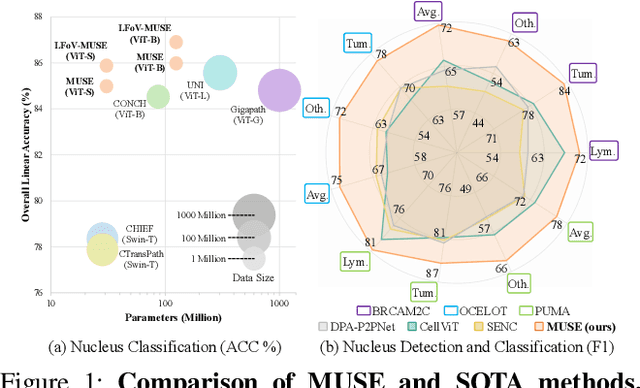
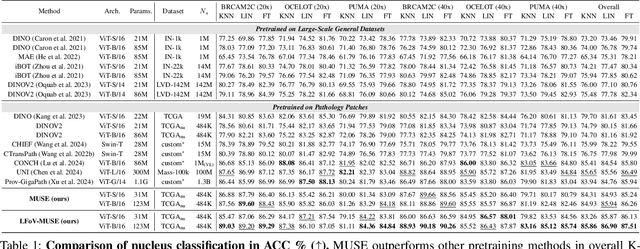
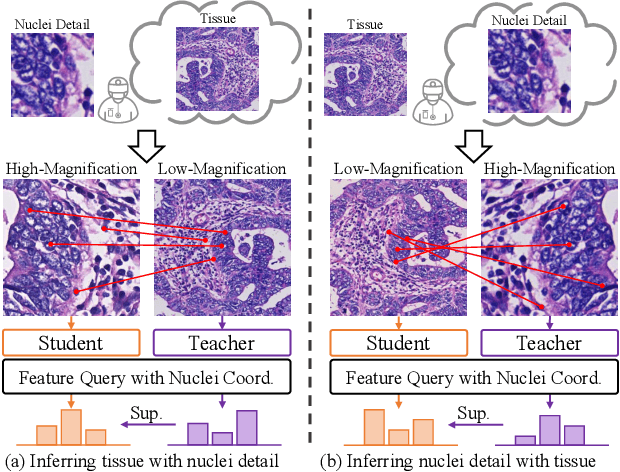
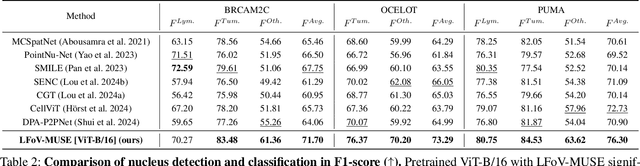
Nucleus detection and classification (NDC) in histopathology analysis is a fundamental task that underpins a wide range of high-level pathology applications. However, existing methods heavily rely on labor-intensive nucleus-level annotations and struggle to fully exploit large-scale unlabeled data for learning discriminative nucleus representations. In this work, we propose MUSE (MUlti-scale denSE self-distillation), a novel self-supervised learning method tailored for NDC. At its core is NuLo (Nucleus-based Local self-distillation), a coordinate-guided mechanism that enables flexible local self-distillation based on predicted nucleus positions. By removing the need for strict spatial alignment between augmented views, NuLo allows critical cross-scale alignment, thus unlocking the capacity of models for fine-grained nucleus-level representation. To support MUSE, we design a simple yet effective encoder-decoder architecture and a large field-of-view semi-supervised fine-tuning strategy that together maximize the value of unlabeled pathology images. Extensive experiments on three widely used benchmarks demonstrate that MUSE effectively addresses the core challenges of histopathological NDC. The resulting models not only surpass state-of-the-art supervised baselines but also outperform generic pathology foundation models.
HAMLET-FFD: Hierarchical Adaptive Multi-modal Learning Embeddings Transformation for Face Forgery Detection
Jul 28, 2025The rapid evolution of face manipulation techniques poses a critical challenge for face forgery detection: cross-domain generalization. Conventional methods, which rely on simple classification objectives, often fail to learn domain-invariant representations. We propose HAMLET-FFD, a cognitively inspired Hierarchical Adaptive Multi-modal Learning framework that tackles this challenge via bidirectional cross-modal reasoning. Building on contrastive vision-language models such as CLIP, HAMLET-FFD introduces a knowledge refinement loop that iteratively assesses authenticity by integrating visual evidence with conceptual cues, emulating expert forensic analysis. A key innovation is a bidirectional fusion mechanism in which textual authenticity embeddings guide the aggregation of hierarchical visual features, while modulated visual features refine text embeddings to generate image-adaptive prompts. This closed-loop process progressively aligns visual observations with semantic priors to enhance authenticity assessment. By design, HAMLET-FFD freezes all pretrained parameters, serving as an external plugin that preserves CLIP's original capabilities. Extensive experiments demonstrate its superior generalization to unseen manipulations across multiple benchmarks, and visual analyses reveal a division of labor among embeddings, with distinct representations specializing in fine-grained artifact recognition.
From Histopathology Images to Cell Clouds: Learning Slide Representations with Hierarchical Cell Transformer
Dec 21, 2024It is clinically crucial and potentially very beneficial to be able to analyze and model directly the spatial distributions of cells in histopathology whole slide images (WSI). However, most existing WSI datasets lack cell-level annotations, owing to the extremely high cost over giga-pixel images. Thus, it remains an open question whether deep learning models can directly and effectively analyze WSIs from the semantic aspect of cell distributions. In this work, we construct a large-scale WSI dataset with more than 5 billion cell-level annotations, termed WSI-Cell5B, and a novel hierarchical Cell Cloud Transformer (CCFormer) to tackle these challenges. WSI-Cell5B is based on 6,998 WSIs of 11 cancers from The Cancer Genome Atlas Program, and all WSIs are annotated per cell by coordinates and types. To the best of our knowledge, WSI-Cell5B is the first WSI-level large-scale dataset integrating cell-level annotations. On the other hand, CCFormer formulates the collection of cells in each WSI as a cell cloud and models cell spatial distribution. Specifically, Neighboring Information Embedding (NIE) is proposed to characterize the distribution of cells within the neighborhood of each cell, and a novel Hierarchical Spatial Perception (HSP) module is proposed to learn the spatial relationship among cells in a bottom-up manner. The clinical analysis indicates that WSI-Cell5B can be used to design clinical evaluation metrics based on counting cells that effectively assess the survival risk of patients. Extensive experiments on survival prediction and cancer staging show that learning from cell spatial distribution alone can already achieve state-of-the-art (SOTA) performance, i.e., CCFormer strongly outperforms other competing methods.
From Pixels to Gigapixels: Bridging Local Inductive Bias and Long-Range Dependencies with Pixel-Mamba
Dec 21, 2024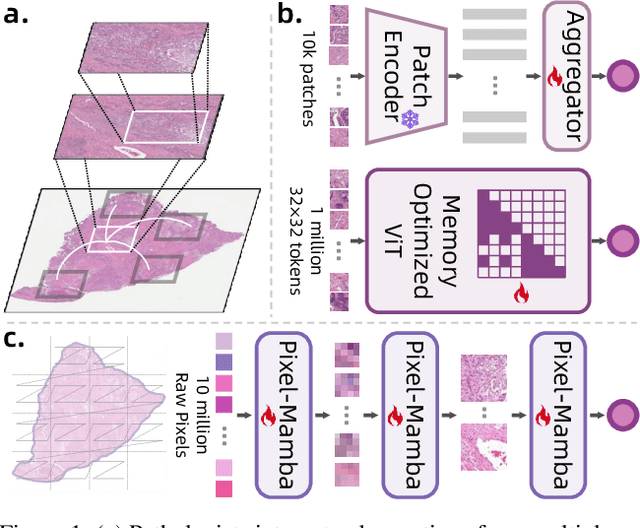
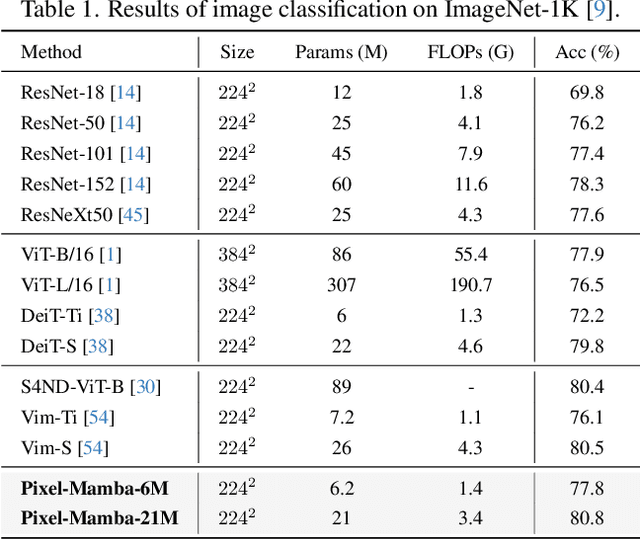
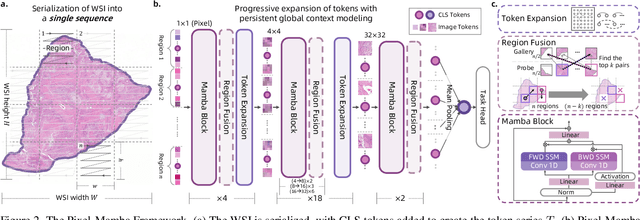
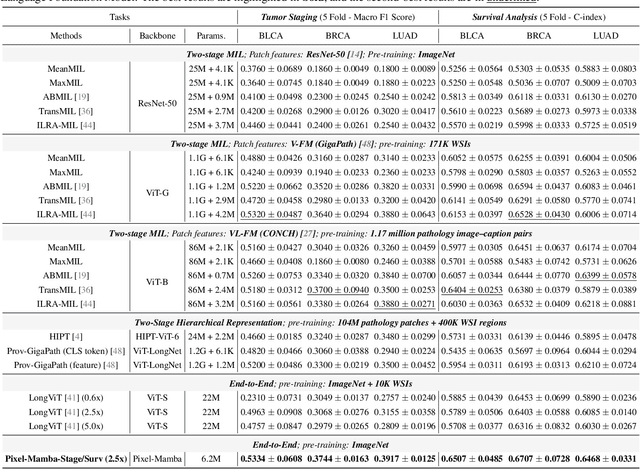
Histopathology plays a critical role in medical diagnostics, with whole slide images (WSIs) offering valuable insights that directly influence clinical decision-making. However, the large size and complexity of WSIs may pose significant challenges for deep learning models, in both computational efficiency and effective representation learning. In this work, we introduce Pixel-Mamba, a novel deep learning architecture designed to efficiently handle gigapixel WSIs. Pixel-Mamba leverages the Mamba module, a state-space model (SSM) with linear memory complexity, and incorporates local inductive biases through progressively expanding tokens, akin to convolutional neural networks. This enables Pixel-Mamba to hierarchically combine both local and global information while efficiently addressing computational challenges. Remarkably, Pixel-Mamba achieves or even surpasses the quantitative performance of state-of-the-art (SOTA) foundation models that were pretrained on millions of WSIs or WSI-text pairs, in a range of tumor staging and survival analysis tasks, {\bf even without requiring any pathology-specific pretraining}. Extensive experiments demonstrate the efficacy of Pixel-Mamba as a powerful and efficient framework for end-to-end WSI analysis.
End-to-end Multi-source Visual Prompt Tuning for Survival Analysis in Whole Slide Images
Sep 05, 2024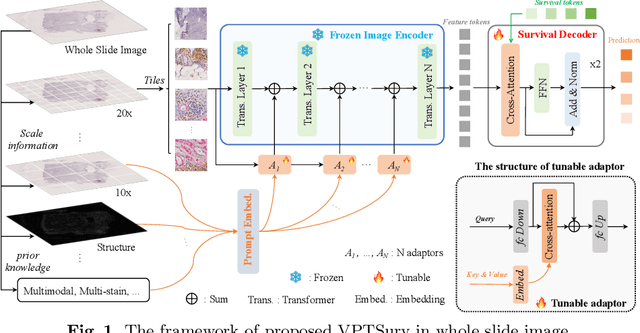
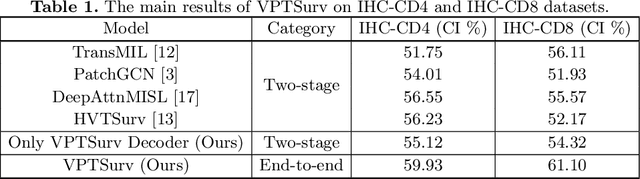
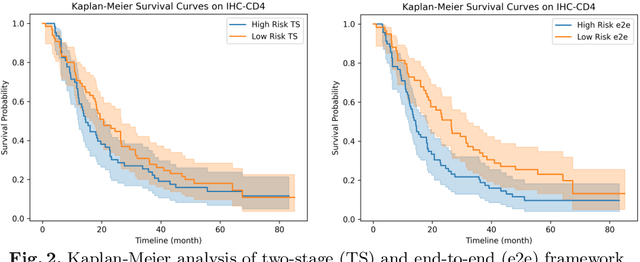

Survival analysis using pathology images poses a considerable challenge, as it requires the localization of relevant information from the multitude of tiles within whole slide images (WSIs). Current methods typically resort to a two-stage approach, where a pre-trained network extracts features from tiles, which are then used by survival models. This process, however, does not optimize the survival models in an end-to-end manner, and the pre-extracted features may not be ideally suited for survival prediction. To address this limitation, we present a novel end-to-end Visual Prompt Tuning framework for survival analysis, named VPTSurv. VPTSurv refines feature embeddings through an efficient encoder-decoder framework. The encoder remains fixed while the framework introduces tunable visual prompts and adaptors, thus permitting end-to-end training specifically for survival prediction by optimizing only the lightweight adaptors and the decoder. Moreover, the versatile VPTSurv framework accommodates multi-source information as prompts, thereby enriching the survival model. VPTSurv achieves substantial increases of 8.7% and 12.5% in the C-index on two immunohistochemical pathology image datasets. These significant improvements highlight the transformative potential of the end-to-end VPT framework over traditional two-stage methods.
FedBIAD: Communication-Efficient and Accuracy-Guaranteed Federated Learning with Bayesian Inference-Based Adaptive Dropout
Jul 14, 2023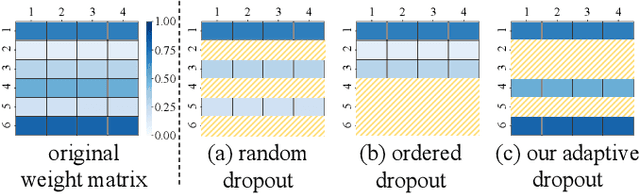

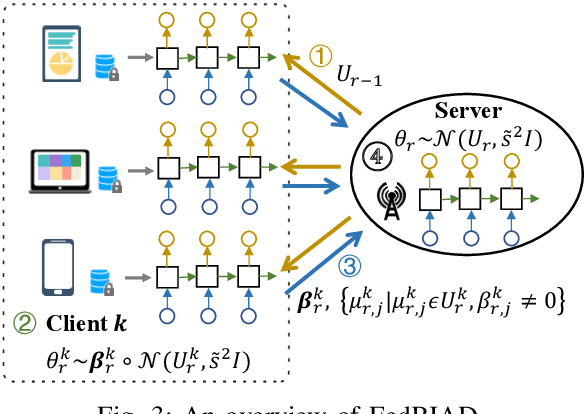

Federated Learning (FL) emerges as a distributed machine learning paradigm without end-user data transmission, effectively avoiding privacy leakage. Participating devices in FL are usually bandwidth-constrained, and the uplink is much slower than the downlink in wireless networks, which causes a severe uplink communication bottleneck. A prominent direction to alleviate this problem is federated dropout, which drops fractional weights of local models. However, existing federated dropout studies focus on random or ordered dropout and lack theoretical support, resulting in unguaranteed performance. In this paper, we propose Federated learning with Bayesian Inference-based Adaptive Dropout (FedBIAD), which regards weight rows of local models as probability distributions and adaptively drops partial weight rows based on importance indicators correlated with the trend of local training loss. By applying FedBIAD, each client adaptively selects a high-quality dropping pattern with accurate approximations and only transmits parameters of non-dropped weight rows to mitigate uplink costs while improving accuracy. Theoretical analysis demonstrates that the convergence rate of the average generalization error of FedBIAD is minimax optimal up to a squared logarithmic factor. Extensive experiments on image classification and next-word prediction show that compared with status quo approaches, FedBIAD provides 2x uplink reduction with an accuracy increase of up to 2.41% even on non-Independent and Identically Distributed (non-IID) data, which brings up to 72% decrease in training time.
A Latent Space Theory for Emergent Abilities in Large Language Models
Apr 24, 2023Languages are not created randomly but rather to communicate information. There is a strong association between languages and their underlying meanings, resulting in a sparse joint distribution that is heavily peaked according to their correlations. Moreover, these peak values happen to match with the marginal distribution of languages due to the sparsity. With the advent of LLMs trained on big data and large models, we can now precisely assess the marginal distribution of languages, providing a convenient means of exploring the sparse structures in the joint distribution for effective inferences. In this paper, we categorize languages as either unambiguous or {\epsilon}-ambiguous and present quantitative results to demonstrate that the emergent abilities of LLMs, such as language understanding, in-context learning, chain-of-thought prompting, and effective instruction fine-tuning, can all be attributed to Bayesian inference on the sparse joint distribution of languages.
Towards Robust k-Nearest-Neighbor Machine Translation
Oct 17, 2022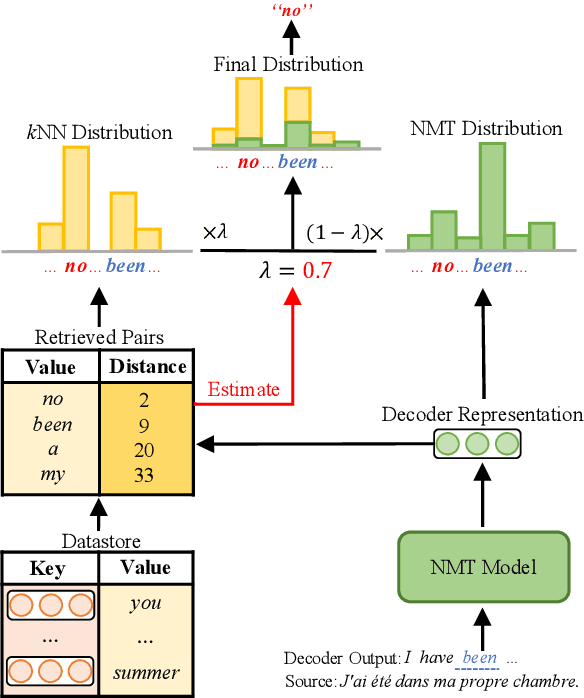
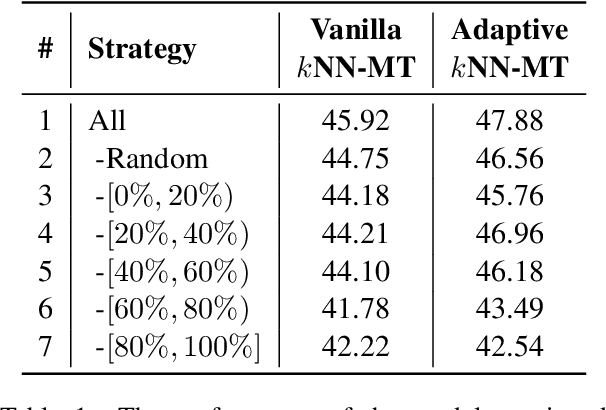
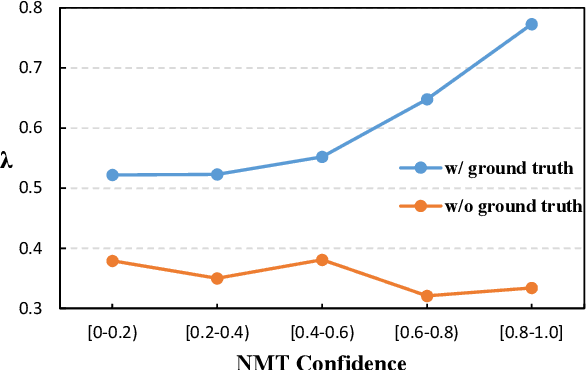
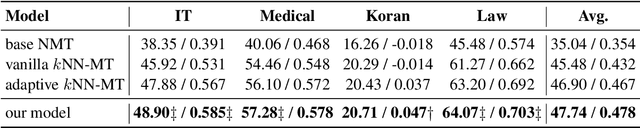
k-Nearest-Neighbor Machine Translation (kNN-MT) becomes an important research direction of NMT in recent years. Its main idea is to retrieve useful key-value pairs from an additional datastore to modify translations without updating the NMT model. However, the underlying retrieved noisy pairs will dramatically deteriorate the model performance. In this paper, we conduct a preliminary study and find that this problem results from not fully exploiting the prediction of the NMT model. To alleviate the impact of noise, we propose a confidence-enhanced kNN-MT model with robust training. Concretely, we introduce the NMT confidence to refine the modeling of two important components of kNN-MT: kNN distribution and the interpolation weight. Meanwhile we inject two types of perturbations into the retrieved pairs for robust training. Experimental results on four benchmark datasets demonstrate that our model not only achieves significant improvements over current kNN-MT models, but also exhibits better robustness. Our code is available at https://github.com/DeepLearnXMU/Robust-knn-mt.
DavarOCR: A Toolbox for OCR and Multi-Modal Document Understanding
Jul 14, 2022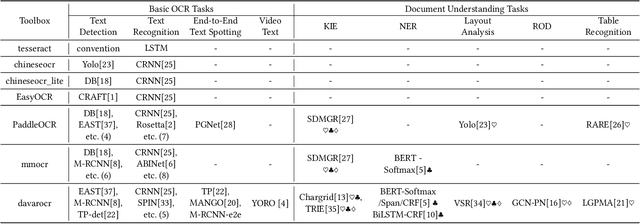


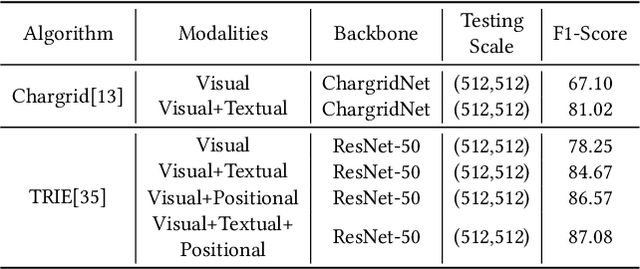
This paper presents DavarOCR, an open-source toolbox for OCR and document understanding tasks. DavarOCR currently implements 19 advanced algorithms, covering 9 different task forms. DavarOCR provides detailed usage instructions and the trained models for each algorithm. Compared with the previous opensource OCR toolbox, DavarOCR has relatively more complete support for the sub-tasks of the cutting-edge technology of document understanding. In order to promote the development and application of OCR technology in academia and industry, we pay more attention to the use of modules that different sub-domains of technology can share. DavarOCR is publicly released at https://github.com/hikopensource/Davar-Lab-OCR.