 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Intra- and Cross-frame Topological Consistency Scheme for Semi-supervised Atherosclerotic Coronary Plaque Segmentation
Jan 14, 2025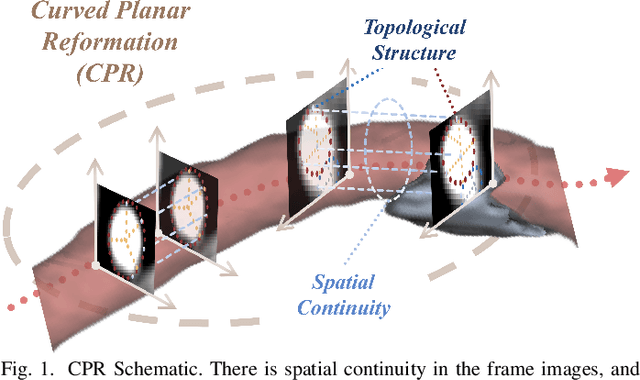
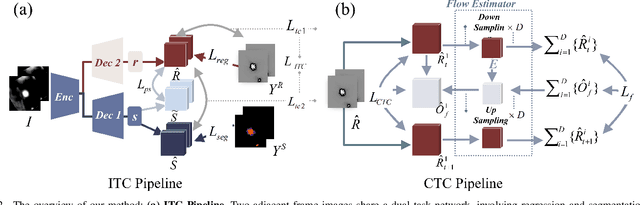
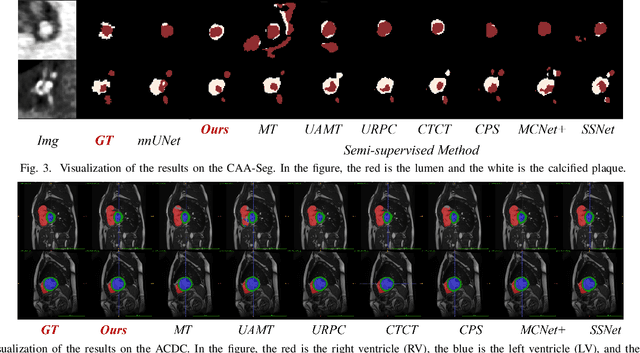
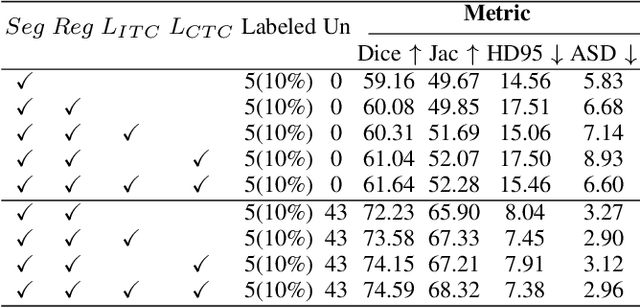
Enhancing the precision of segmenting coronary atherosclerotic plaques from CT Angiography (CTA) images is pivotal for advanced Coronary Atherosclerosis Analysis (CAA), which distinctively relies on the analysis of vessel cross-section images reconstructed via Curved Planar Reformation. This task presents significant challenges due to the indistinct boundaries and structures of plaques and blood vessels, leading to the inadequate performance of current deep learning models, compounded by the inherent difficulty in annotating such complex data. To address these issues, we propose a novel dual-consistency semi-supervised framework that integrates Intra-frame Topological Consistency (ITC) and Cross-frame Topological Consistency (CTC) to leverage labeled and unlabeled data. ITC employs a dual-task network for simultaneous segmentation mask and Skeleton-aware Distance Transform (SDT) prediction, achieving similar prediction of topology structure through consistency constraint without additional annotations. Meanwhile, CTC utilizes an unsupervised estimator for analyzing pixel flow between skeletons and boundaries of adjacent frames, ensuring spatial continuity. Experiments on two CTA datasets show that our method surpasses existing semi-supervised methods and approaches the performance of supervised methods on CAA. In addition, our method also performs better than other methods on the ACDC dataset, demonstrating its generalization.
HAUR: Human Annotation Understanding and Recognition Through Text-Heavy Images
Dec 24, 2024Vision Question Answering (VQA) tasks use images to convey critical information to answer text-based questions, which is one of the most common forms of question answering in real-world scenarios. Numerous vision-text models exist today and have performed well on certain VQA tasks. However, these models exhibit significant limitations in understanding human annotations on text-heavy images. To address this, we propose the Human Annotation Understanding and Recognition (HAUR) task. As part of this effort, we introduce the Human Annotation Understanding and Recognition-5 (HAUR-5) dataset, which encompasses five common types of human annotations. Additionally, we developed and trained our model, OCR-Mix. Through comprehensive cross-model comparisons, our results demonstrate that OCR-Mix outperforms other models in this task. Our dataset and model will be released soon .
Exploring Dynamic Selection of Branch Expansion Orders for Code Generation
Jun 01, 2021
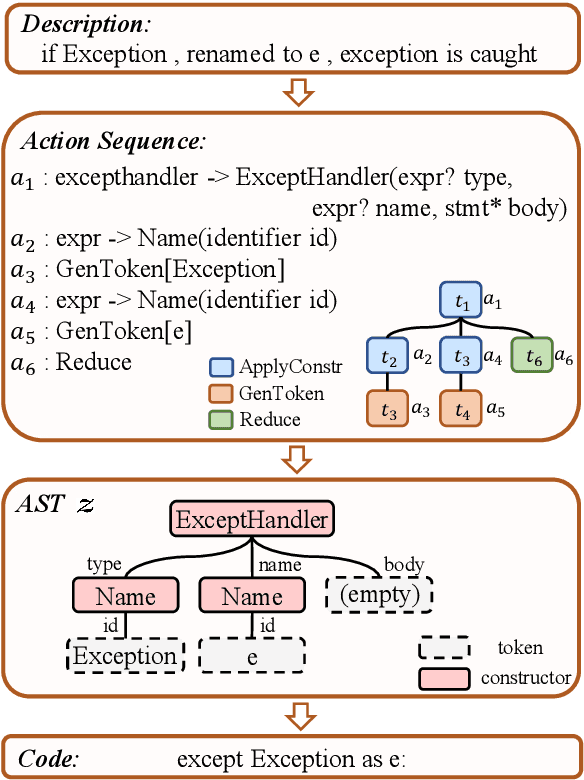
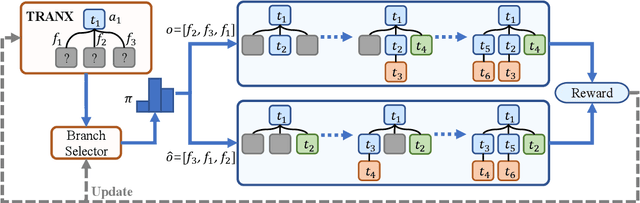
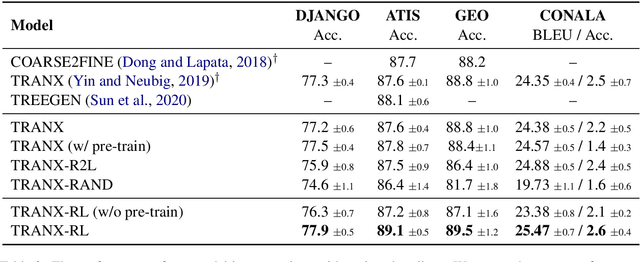
Due to the great potential in facilitating software development, code generation has attracted increasing attention recently. Generally, dominant models are Seq2Tree models, which convert the input natural language description into a sequence of tree-construction actions corresponding to the pre-order traversal of an Abstract Syntax Tree (AST). However, such a traversal order may not be suitable for handling all multi-branch nodes. In this paper, we propose to equip the Seq2Tree model with a context-based Branch Selector, which is able to dynamically determine optimal expansion orders of branches for multi-branch nodes. Particularly, since the selection of expansion orders is a non-differentiable multi-step operation, we optimize the selector through reinforcement learning, and formulate the reward function as the difference of model losses obtained through different expansion orders. Experimental results and in-depth analysis on several commonly-used datasets demonstrate the effectiveness and generality of our approach. We have released our code at https://github.com/DeepLearnXMU/CG-RL.