 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuadVerse: An Integrated Framework Aligning Visual-Physical Reality for Quadruped Simulation
Jun 05, 2026Simulation is central to robot learning, yet the sim-to-real gap remains a major bottleneck.Existing approaches often tackle visual or dynamic gaps separately, overlooking how these individual mismatches accumulate and propagate throughout the robot's state evolution.In this paper, we introduce QuadVerse, an integrated framework that uses reconstructed scenes as a calibration substrate for aligning visual perception, physical interaction, and actuator dynamics.From captured RGB videos, we reconstruct geometry-constrained 3D Gaussian Splatting (3DGS) scenes that support batched photorealistic ego-view rendering and collision-ready semantic mesh extraction. The meshes further enable contact calibration by initializing spatially varying friction priors and refining them through trajectory-based posterior search.To address remaining actuator discrepancies, QuadVerse trains a residual dynamics compensator by replaying real-world trajectories on the contact-calibrated terrain, reducing the entanglement between terrain-induced contact errors and actuator non-idealities.Experiments show that QuadVerse improves reconstruction quality and locomotion tracking over relevant baselines.Leveraging this foundation, we demonstrate robust zero-shot visual-navigation policy deployment without task-specific real-world rollouts.
UniLab: A Heterogeneous Architecture for Robot RL Beyond GPU-Dominant Paradigms
Jun 02, 2026Simulation-based RL for contemporary robot control is increasingly organized around GPU-resident simulation: physics, rollout collection, and learning are placed on a single GPU-centric execution path. This paradigm has greatly improved training speed, but it has also encouraged a default assumption that efficient training requires physics to reside on the GPU. We revisit this assumption. Our view is that, in simulation-dominated robot control, the essential question is not which processor runs physics, but whether simulation throughput, policy learning, and runtime synchronization form an efficient end-to-end loop. We present UniLab, a heterogeneous CPU-simulation / GPU-learning architecture that decouples CPU-parallel simulation from GPU policy updates through a unified runtime for data movement, buffering, and synchronization. UniLab is implemented as a complete and extensible training system using MuJoCoUni and MotrixSim CPU-batched physics backends, supporting PPO, FastSAC, FlashSAC, and APPO. On representative simulation-based robot control tasks, UniLab improves end-to-end training efficiency by 3--10$\times$ under the same hardware configuration, while reducing dependence on the NVIDIA CUDA-based software stack and supporting cross-platform execution on the Apple macOS platform and the AMD ROCm and Intel XPU accelerator backends. These results show that GPU simulation is an effective path to efficient training, but not a necessary one, broadening the practical system choices available for robot RL training. Project page: https://unilabsim.github.io.
A Heterogeneous Architecture for Robot RL Beyond GPU-Dominant Paradigms
May 28, 2026Simulation-based RL for contemporary robot control is increasingly organized around GPU-resident simulation: physics, rollout collection, and learning are placed on a single GPU-centric execution path. This paradigm has greatly improved training speed, but it has also encouraged a default assumption that efficient training requires physics to reside on the GPU. We revisit this assumption. Our view is that, in simulation-dominated robot control, the essential question is not which processor runs physics, but whether simulation throughput, policy learning, and runtime synchronization form an efficient end-to-end loop. We present UniLab, a heterogeneous CPU-simulation / GPU-learning architecture that decouples CPU-parallel simulation from GPU policy updates through a unified runtime for data movement, buffering, and synchronization. UniLab is implemented as a complete and extensible training system using MuJoCoUni and MotrixSim CPU-batched physics backends, supporting PPO, SAC, FlashSAC, TD3, and APPO. On representative simulation-based robot control tasks, UniLab improves end-to-end training efficiency by 3--10$\times$ under the same hardware configuration, while reducing dependence on the NVIDIA CUDA-based software stack and supporting cross-platform execution on the Apple macOS platform and the AMD ROCm and Intel XPU accelerator backends. These results show that GPU simulation is an effective path to efficient training, but not a necessary one, broadening the practical system choices available for robot RL training. Project page: https://github.com/unilabsim/UniLab.
Auditing Training-Free 3D Shape Retrieval with Diffused Geodesic Moments
May 27, 2026Reported retrieval scores for training-free shape descriptors conflate local signal design, normalization, aggregation, codebook fitting, and metric choices, making isolated component evaluation difficult. This paper reframes descriptor evaluation as a {\em protocol audit}. We introduce Diffused Geodesic Moments (DGM), a seed-conditioned descriptor that computes sparse implicit heat responses, converts them to distance-like fields, and summarizes each vertex by low-order moments across seeds and scales. DGM is used both as a practical non-spectral baseline and as an instrument for isolating protocol effects. On the registered FAUST benchmark split (FAUST-Reg) and the TOSCA shape collection, aggregation-matched experiments show that an independent Geometric Moment Shape Descriptor baseline built on Heat Kernel Signature features (GMSD-HKS) obtains the highest scores in this implementation ($0.621/0.820$ and $0.865/0.963$ mean average precision (mAP)/top-1), Wave Kernel Signature (WKS) remains a strong classical signal, and DGM is useful mainly when sparse solves, non-spectral deployment, or symmetry-informative seed frames are priorities. The broader finding is methodological: the input field and aggregation protocol can dominate the moment formula. The paper contributes a reproducible protocol-cascade analysis, a cross-shape alignment diagnostic for functional-map compatibility, and concrete recommendations for designing and reporting training-free shape descriptors.
WARDEN: Endangered Indigenous Language Transcription and Translation with 6 Hours of Training Data
May 13, 2026This paper introduces WARDEN, an early language model system capable of transcribing and translating Wardaman, an endangered Australian indigenous language into English. The significant challenge we face is the lack of large-scale training data: in fact, we only have 6 hours of annotated audio. Therefore, while it is common practice to train a single model for transcription and translation using large datasets (like English to French), this practice is no longer viable in the Wardaman to English context. To tackle the low-resource challenge, we design WARDEN to have separate transcription and translation models: WARDEN first turns a Wardaman audio input into phonemic transcription, and then the transcription into English translation. Further, we propose two useful techniques to enhance performance. For transcription, we initialize the Wardaman token from Sundanese, a language that shares similar phonemes with Wardaman, to accelerate fine-tuning of the transcription model. For translation, we compile a Wardaman-English dictionary from expert annotations, and provide this domain-specific knowledge to a large language model (LLM) to reason and decide the final output. We empirically demonstrate that this two-stage design works better than data-hungry unified approaches in extremely low data settings. Using a mere 6 hours of annotated data, WARDEN outperforms larger open-source and proprietary models and establishes a strong baseline. Data and code are available.
GS-Playground: A High-Throughput Photorealistic Simulator for Vision-Informed Robot Learning
Apr 28, 2026Embodied AI research is undergoing a shift toward vision-centric perceptual paradigms. While massively parallel simulators have catalyzed breakthroughs in proprioception-based locomotion, their potential remains largely untapped for vision-informed tasks due to the prohibitive computational overhead of large-scale photorealistic rendering. Furthermore, the creation of simulation-ready 3D assets heavily relies on labor-intensive manual modeling, while the significant sim-to-real physical gap hinders the transfer of contact-rich manipulation policies. To address these bottlenecks, we propose GS-Playground, a multi-modal simulation framework designed to accelerate end-to-end perceptual learning. We develop a novel high-performance parallel physics engine, specifically designed to integrate with a batch 3D Gaussian Splatting (3DGS) rendering pipeline to ensure high-fidelity synchronization. Our system achieves a breakthrough throughput of 10^4 FPS at 640x480 resolution, significantly lowering the barrier for large-scale visual RL. Additionally, we introduce an automated Real2Sim workflow that reconstructs photorealistic, physically consistent, and memory-efficient environments, streamlining the generation of complex simulation-ready scenes. Extensive experiments on locomotion, navigation, and manipulation demonstrate that GS-Playground effectively bridges the perceptual and physical gaps across diverse embodied tasks. Project homepage: https://gsplayground.github.io.
Agentization of Digital Assets for the Agentic Web: Concepts, Techniques, and Benchmark
Apr 05, 2026Agentic Web, as a new paradigm that redefines the internet through autonomous, goal-driven interactions, plays an important role in group intelligence. As the foundational semantic primitives of the Agentic Web, digital assets encapsulate interactive web elements into agents, which expand the capacities and coverage of agents in agentic web. The lack of automated methodologies for agent generation limits the wider usage of digital assets and the advancement of the Agentic Web. In this paper, we first formalize these challenges by strictly defining the A2A-Agentization process, decomposing it into critical stages and identifying key technical hurdles on top of the A2A protocol. Based on this framework, we develop an Agentization Agent to agentize digital assets for the Agentic Web. To rigorously evaluate this capability, we propose A2A-Agentization Bench, the first benchmark explicitly designed to evaluate agentization quality in terms of fidelity and interoperability. Our experiments demonstrate that our approach effectively activates the functional capabilities of digital assets and enables interoperable A2A multi-agent collaboration. We believe this work will further facilitate scalable and standardized integration of digital assets into the Agentic Web ecosystem.
MMSpec: Benchmarking Speculative Decoding for Vision-Language Models
Mar 16, 2026Vision-language models (VLMs) achieve strong performance on multimodal tasks but suffer from high inference latency due to large model sizes and long multimodal contexts. Speculative decoding has recently emerged as an effective acceleration technique, yet its behavior in VLMs remains insufficiently understood. We introduce MMSpec, the first benchmark for evaluating speculative decoding in vision-language models. MMSpec contains 600 multimodal samples across six task categories and integrates ten representative speculative decoding algorithms under a unified evaluation framework. Our study reveals three key findings: (1) methods designed for text-only LLMs degrade in multimodal scenarios, (2) vision awareness becomes increasingly important at larger batch sizes, and (3) throughput speedup alone does not reliably reflect latency performance. Motivated by these findings, we propose ViSkip, a plug-and-play speculative decoding method that dynamically adapts speculation to vision tokens and achieves state-of-the-art performance.
DM0: An Embodied-Native Vision-Language-Action Model towards Physical AI
Feb 16, 2026Moving beyond the traditional paradigm of adapting internet-pretrained models to physical tasks, we present DM0, an Embodied-Native Vision-Language-Action (VLA) framework designed for Physical AI. Unlike approaches that treat physical grounding as a fine-tuning afterthought, DM0 unifies embodied manipulation and navigation by learning from heterogeneous data sources from the onset. Our methodology follows a comprehensive three-stage pipeline: Pretraining, Mid-Training, and Post-Training. First, we conduct large-scale unified pretraining on the Vision-Language Model (VLM) using diverse corpora--seamlessly integrating web text, autonomous driving scenarios, and embodied interaction logs-to jointly acquire semantic knowledge and physical priors. Subsequently, we build a flow-matching action expert atop the VLM. To reconcile high-level reasoning with low-level control, DM0 employs a hybrid training strategy: for embodied data, gradients from the action expert are not backpropagated to the VLM to preserve generalized representations, while the VLM remains trainable on non-embodied data. Furthermore, we introduce an Embodied Spatial Scaffolding strategy to construct spatial Chain-of-Thought (CoT) reasoning, effectively constraining the action solution space. Experiments on the RoboChallenge benchmark demonstrate that DM0 achieves state-of-the-art performance in both Specialist and Generalist settings on Table30.
Intelligent Reflecting Surfaces for Integrated Sensing and Communications: A Survey
Nov 14, 2025
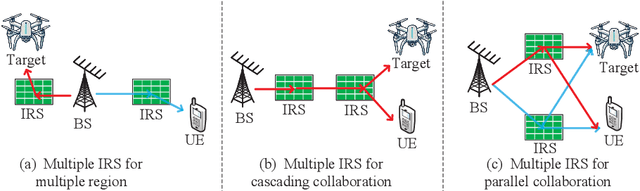
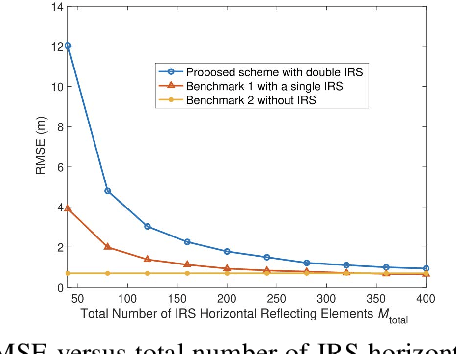
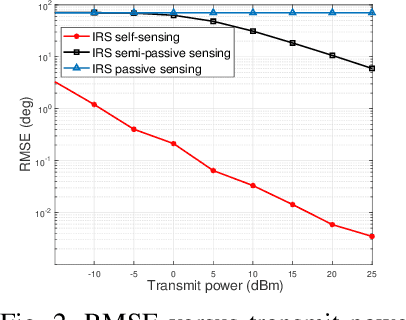
The rapid development of sixth-generation (6G) wireless networks requires seamless integration of communication and sensing to support ubiquitous intelligence and real-time, high-reliability applications. Integrated sensing and communication (ISAC) has emerged as a key solution for achieving this convergence, offering joint utilization of spectral, hardware, and computing resources. However, realizing high-performance ISAC remains challenging due to environmental line-of-sight (LoS) blockage, limited spatial resolution, and the inherent coverage asymmetry and resource coupling between sensing and communication. Intelligent reflecting surfaces (IRSs), featuring low-cost, energy-efficient, and programmable electromagnetic reconfiguration, provide a promising solution to overcome these limitations. This article presents a comprehensive overview of IRS-aided wireless sensing and ISAC technologies, including IRS architectures, target detection and estimation techniques, beamforming designs, and performance metrics. It further explores IRS-enabled new opportunities for more efficient performance balancing, coexistence, and networking in ISAC systems, focuses on current design bottlenecks, and outlines future research directions. This article aims to offer a unified design framework that guides the development of practical and scalable IRS-aided ISAC systems for the next-generation wireless network.