 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniOVCD: Streamlining Open-Vocabulary Change Detection with SAM 3
Jan 20, 2026Change Detection (CD) is a fundamental task in remote sensing. It monitors the evolution of land cover over time. Based on this, Open-Vocabulary Change Detection (OVCD) introduces a new requirement. It aims to reduce the reliance on predefined categories. Existing training-free OVCD methods mostly use CLIP to identify categories. These methods also need extra models like DINO to extract features. However, combining different models often causes problems in matching features and makes the system unstable. Recently, the Segment Anything Model 3 (SAM 3) is introduced. It integrates segmentation and identification capabilities within one promptable model, which offers new possibilities for the OVCD task. In this paper, we propose OmniOVCD, a standalone framework designed for OVCD. By leveraging the decoupled output heads of SAM 3, we propose a Synergistic Fusion to Instance Decoupling (SFID) strategy. SFID first fuses the semantic, instance, and presence outputs of SAM 3 to construct land-cover masks, and then decomposes them into individual instance masks for change comparison. This design preserves high accuracy in category recognition and maintains instance-level consistency across images. As a result, the model can generate accurate change masks. Experiments on four public benchmarks (LEVIR-CD, WHU-CD, S2Looking, and SECOND) demonstrate SOTA performance, achieving IoU scores of 67.2, 66.5, 24.5, and 27.1 (class-average), respectively, surpassing all previous methods.
Not All Parameters Matter: Masking Diffusion Models for Enhancing Generation Ability
May 06, 2025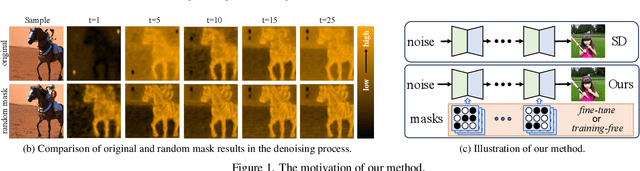
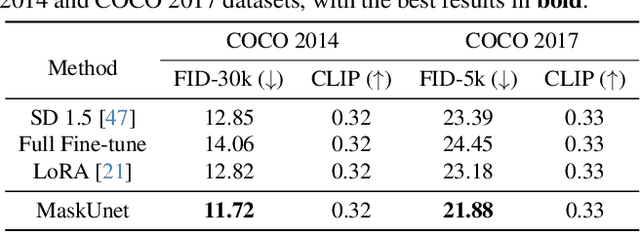
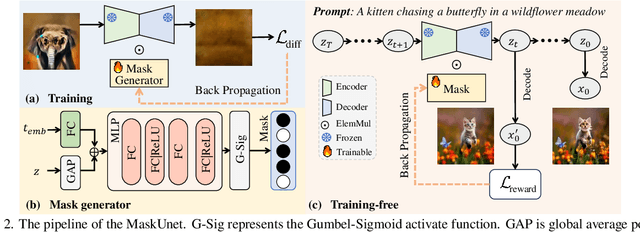
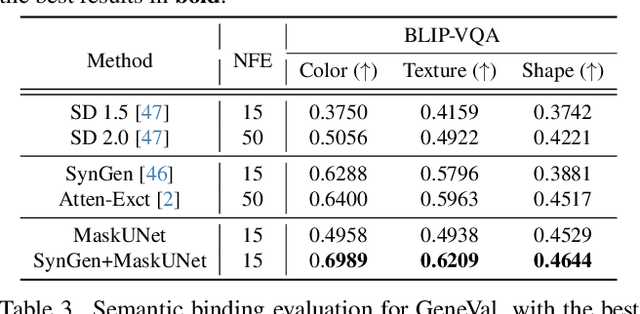
The diffusion models, in early stages focus on constructing basic image structures, while the refined details, including local features and textures, are generated in later stages. Thus the same network layers are forced to learn both structural and textural information simultaneously, significantly differing from the traditional deep learning architectures (e.g., ResNet or GANs) which captures or generates the image semantic information at different layers. This difference inspires us to explore the time-wise diffusion models. We initially investigate the key contributions of the U-Net parameters to the denoising process and identify that properly zeroing out certain parameters (including large parameters) contributes to denoising, substantially improving the generation quality on the fly. Capitalizing on this discovery, we propose a simple yet effective method-termed ``MaskUNet''- that enhances generation quality with negligible parameter numbers. Our method fully leverages timestep- and sample-dependent effective U-Net parameters. To optimize MaskUNet, we offer two fine-tuning strategies: a training-based approach and a training-free approach, including tailored networks and optimization functions. In zero-shot inference on the COCO dataset, MaskUNet achieves the best FID score and further demonstrates its effectiveness in downstream task evaluations. Project page: https://gudaochangsheng.github.io/MaskUnet-Page/
Beyond Flat Text: Dual Self-inherited Guidance for Visual Text Generation
Jan 10, 2025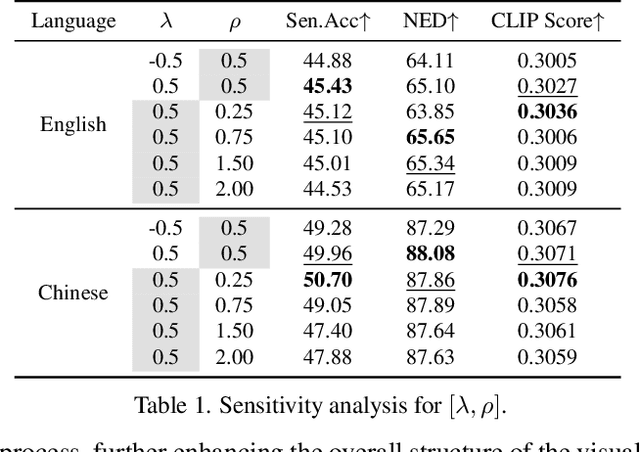


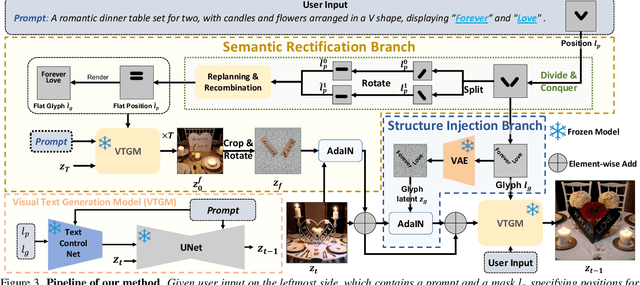
In real-world images, slanted or curved texts, especially those on cans, banners, or badges, appear as frequently, if not more so, than flat texts due to artistic design or layout constraints. While high-quality visual text generation has become available with the advanced generative capabilities of diffusion models, these models often produce distorted text and inharmonious text background when given slanted or curved text layouts due to training data limitation. In this paper, we introduce a new training-free framework, STGen, which accurately generates visual texts in challenging scenarios (\eg, slanted or curved text layouts) while harmonizing them with the text background. Our framework decomposes the visual text generation process into two branches: (i) \textbf{Semantic Rectification Branch}, which leverages the ability in generating flat but accurate visual texts of the model to guide the generation of challenging scenarios. The generated latent of flat text is abundant in accurate semantic information related both to the text itself and its background. By incorporating this, we rectify the semantic information of the texts and harmonize the integration of the text with its background in complex layouts. (ii) \textbf{Structure Injection Branch}, which reinforces the visual text structure during inference. We incorporate the latent information of the glyph image, rich in glyph structure, as a new condition to further strengthen the text structure. To enhance image harmony, we also apply an effective combination method to merge the priors, providing a solid foundation for generation. Extensive experiments across a variety of visual text layouts demonstrate that our framework achieves superior accuracy and outstanding quality.
Occlusion-Aware 3D Motion Interpretation for Abnormal Behavior Detection
Jul 23, 2024Estimating abnormal posture based on 3D pose is vital in human pose analysis, yet it presents challenges, especially when reconstructing 3D human poses from monocular datasets with occlusions. Accurate reconstructions enable the restoration of 3D movements, which assist in the extraction of semantic details necessary for analyzing abnormal behaviors. However, most existing methods depend on predefined key points as a basis for estimating the coordinates of occluded joints, where variations in data quality have adversely affected the performance of these models. In this paper, we present OAD2D, which discriminates against motion abnormalities based on reconstructing 3D coordinates of mesh vertices and human joints from monocular videos. The OAD2D employs optical flow to capture motion prior information in video streams, enriching the information on occluded human movements and ensuring temporal-spatial alignment of poses. Moreover, we reformulate the abnormal posture estimation by coupling it with Motion to Text (M2T) model in which, the VQVAE is employed to quantize motion features. This approach maps motion tokens to text tokens, allowing for a semantically interpretable analysis of motion, and enhancing the generalization of abnormal posture detection boosted by Language model. Our approach demonstrates the robustness of abnormal behavior detection against severe and self-occlusions, as it reconstructs human motion trajectories in global coordinates to effectively mitigate occlusion issues. Our method, validated using the Human3.6M, 3DPW, and NTU RGB+D datasets, achieves a high $F_1-$Score of 0.94 on the NTU RGB+D dataset for medical condition detection. And we will release all of our code and data.