 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReCal3R: Reliability-Calibrated Learning Rates for Streaming 3D Reconstruction
Jul 06, 2026Streaming 3D reconstruction relies on a compact recurrent scene state to process long image streams in linear time and bounded memory. However, repeated updates can gradually corrupt this state, causing reliable historical information to be overwritten by noisy or ambiguous observations. We introduce ReCal3R, a reliability-calibrated learning rate method for recurrent 3D reconstruction. Instead of directly applying a candidate learning rate, our method estimates state token reliability from the maintained scene state and uses it to calibrate a candidate learning rate derived from token alignment, state reconstruction residual, and recent update pressure. The resulting token-wise learning rate interpolates between a conservative base rate and the candidate rate, suppressing aggressive updates on unreliable tokens while preserving adaptation to informative frames. Applied to CUT3R as a training-free calibration rule, ReCal3R reaches strong performance on long sequences in pose, depth, and reconstruction quality, including a 3.7$\times$ reduction in ATE, with comparable runtime and memory. Code is available at: https://github.com/Powertony102/ReCal3R.
QuadBox: Accelerating 3D Gaussian Splatting with Geometry-Aware Boxes
May 06, 20263D Gaussian Splatting (3DGS) has emerged as an advanced technique for real-time novel view synthesis by representing scene geometry and appearance using differentiable Gaussian primitives. However, efficiently computing precise Gaussian-tile intersections remains a critical task in the rasterization pipeline. To this end, we propose QuadBox, a method that leverages four axis-aligned bounding boxes to tightly encapsulate projected Gaussians in a discrete manner. First, we derive a geometry-aware stretching factor that enables the construction of a tile-aligned QuadBox, which covers the elliptical projection and largely excludes irrelevant tiles. Second, we introduce QPass, a single-pass tile traversal algorithm that exhaustively exploits the discrete nature of QuadBox, ensuring that the tile intersection check is performed with simple interval tests. Experiments on public datasets show that our method accelerates the rendering speed of 3DGS by 1.85$\times$. Code is available at \href{https://github.com/Powertony102/QuadBox}{https://github.com/Powertony102/QuadBox}.
S-VGGT: Structure-Aware Subscene Decomposition for Scalable 3D Foundation Models
Mar 18, 2026Feed-forward 3D foundation models face a key challenge: the quadratic computational cost introduced by global attention, which severely limits scalability as input length increases. Concurrent acceleration methods, such as token merging, operate at the token level. While they offer local savings, the required nearest-neighbor searches introduce undesirable overhead. Consequently, these techniques fail to tackle the fundamental issue of structural redundancy dominant in dense capture data. In this work, we introduce \textbf{S-VGGT}, a novel approach that addresses redundancy at the structural frame level, drastically shifting the optimization focus. We first leverage the initial features to build a dense scene graph, which characterizes structural scene redundancy and guides the subsequent scene partitioning. Using this graph, we softly assign frames to a small number of subscenes, guaranteeing balanced groups and smooth geometric transitions. The core innovation lies in designing the subscenes to share a common reference frame, establishing a parallel geometric bridge that enables independent and highly efficient processing without explicit geometric alignment. This structural reorganization provides strong intrinsic acceleration by cutting the global attention cost at its source. Crucially, S-VGGT is entirely orthogonal to token-level acceleration methods, allowing the two to be seamlessly combined for compounded speedups without compromising reconstruction fidelity. Code is available at https://github.com/Powertony102/S-VGGT.
Large Language Models Enhanced Hyperbolic Space Recommender Systems
Apr 08, 2025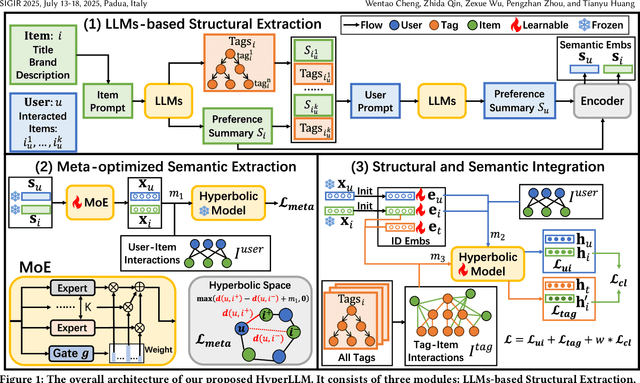
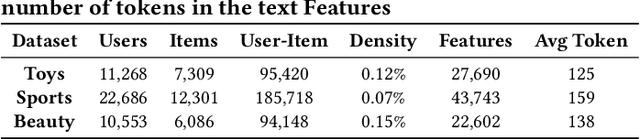
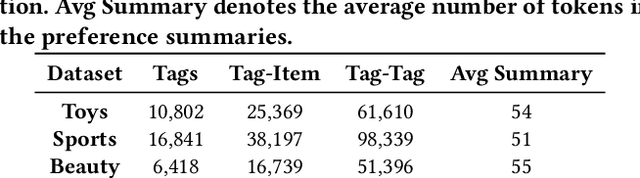
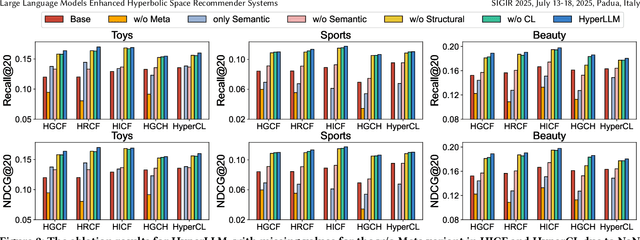
Large Language Models (LLMs) have attracted significant attention in recommender systems for their excellent world knowledge capabilities. However, existing methods that rely on Euclidean space struggle to capture the rich hierarchical information inherent in textual and semantic data, which is essential for capturing user preferences. The geometric properties of hyperbolic space offer a promising solution to address this issue. Nevertheless, integrating LLMs-based methods with hyperbolic space to effectively extract and incorporate diverse hierarchical information is non-trivial. To this end, we propose a model-agnostic framework, named HyperLLM, which extracts and integrates hierarchical information from both structural and semantic perspectives. Structurally, HyperLLM uses LLMs to generate multi-level classification tags with hierarchical parent-child relationships for each item. Then, tag-item and user-item interactions are jointly learned and aligned through contrastive learning, thereby providing the model with clear hierarchical information. Semantically, HyperLLM introduces a novel meta-optimized strategy to extract hierarchical information from semantic embeddings and bridge the gap between the semantic and collaborative spaces for seamless integration. Extensive experiments show that HyperLLM significantly outperforms recommender systems based on hyperbolic space and LLMs, achieving performance improvements of over 40%. Furthermore, HyperLLM not only improves recommender performance but also enhances training stability, highlighting the critical role of hierarchical information in recommender systems.
Beyond Flat Text: Dual Self-inherited Guidance for Visual Text Generation
Jan 10, 2025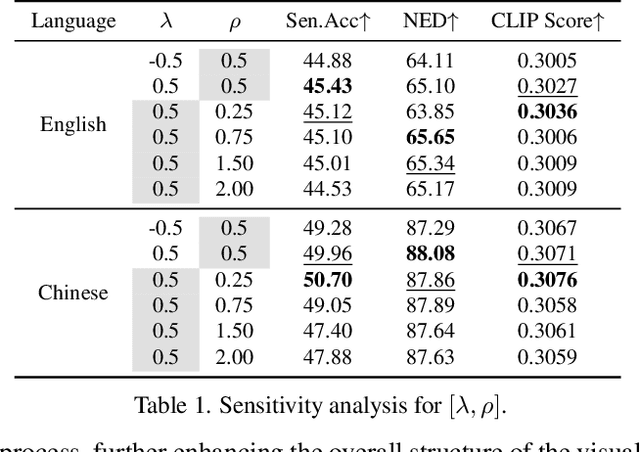


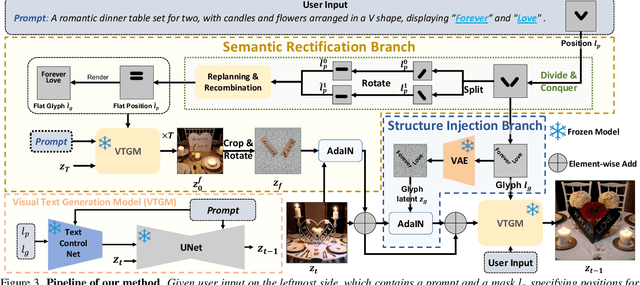
In real-world images, slanted or curved texts, especially those on cans, banners, or badges, appear as frequently, if not more so, than flat texts due to artistic design or layout constraints. While high-quality visual text generation has become available with the advanced generative capabilities of diffusion models, these models often produce distorted text and inharmonious text background when given slanted or curved text layouts due to training data limitation. In this paper, we introduce a new training-free framework, STGen, which accurately generates visual texts in challenging scenarios (\eg, slanted or curved text layouts) while harmonizing them with the text background. Our framework decomposes the visual text generation process into two branches: (i) \textbf{Semantic Rectification Branch}, which leverages the ability in generating flat but accurate visual texts of the model to guide the generation of challenging scenarios. The generated latent of flat text is abundant in accurate semantic information related both to the text itself and its background. By incorporating this, we rectify the semantic information of the texts and harmonize the integration of the text with its background in complex layouts. (ii) \textbf{Structure Injection Branch}, which reinforces the visual text structure during inference. We incorporate the latent information of the glyph image, rich in glyph structure, as a new condition to further strengthen the text structure. To enhance image harmony, we also apply an effective combination method to merge the priors, providing a solid foundation for generation. Extensive experiments across a variety of visual text layouts demonstrate that our framework achieves superior accuracy and outstanding quality.
RotationDrag: Point-based Image Editing with Rotated Diffusion Features
Jan 12, 2024A precise and user-friendly manipulation of image content while preserving image fidelity has always been crucial to the field of image editing. Thanks to the power of generative models, recent point-based image editing methods allow users to interactively change the image content with high generalizability by clicking several control points. But the above mentioned editing process is usually based on the assumption that features stay constant in the motion supervision step from initial to target points. In this work, we conduct a comprehensive investigation in the feature space of diffusion models, and find that features change acutely under in-plane rotation. Based on this, we propose a novel approach named RotationDrag, which significantly improves point-based image editing performance when users intend to in-plane rotate the image content. Our method tracks handle points more precisely by utilizing the feature map of the rotated images, thus ensuring precise optimization and high image fidelity. Furthermore, we build a in-plane rotation focused benchmark called RotateBench, the first benchmark to evaluate the performance of point-based image editing method under in-plane rotation scenario on both real images and generated images. A thorough user study demonstrates the superior capability in accomplishing in-plane rotation that users intend to achieve, comparing the DragDiffusion baseline and other existing diffusion-based methods. See the project page https://github.com/Tony-Lowe/RotationDrag for code and experiment results.
Road Mapping and Localization using Sparse Semantic Visual Features
Aug 11, 2021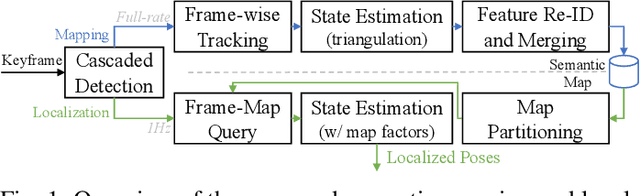
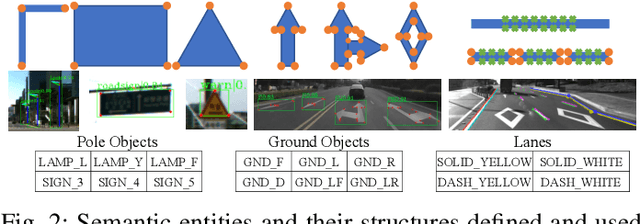
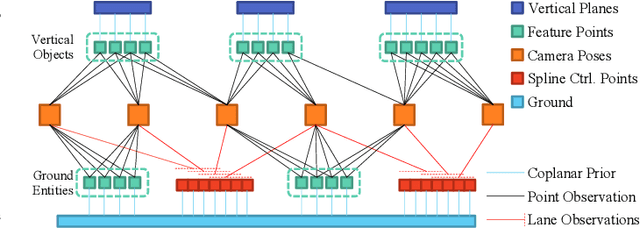
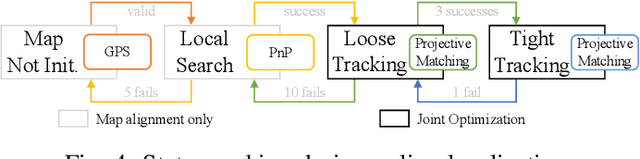
We present a novel method for visual mapping and localization for autonomous vehicles, by extracting, modeling, and optimizing semantic road elements. Specifically, our method integrates cascaded deep models to detect standardized road elements instead of traditional point features, to seek for improved pose accuracy and map representation compactness. To utilize the structural features, we model road lights and signs by their representative deep keypoints for skeleton and boundary, and parameterize lanes via piecewise cubic splines. Based on the road semantic features, we build a complete pipeline for mapping and localization, which includes a) image processing front-end, b) sensor fusion strategies, and c) optimization backend. Experiments on public datasets and our testing platform have demonstrated the effectiveness and advantages of our method by outperforming traditional approaches.
Cascaded Parallel Filtering for Memory-Efficient Image-Based Localization
Aug 16, 2019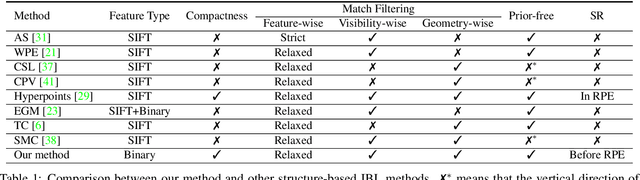
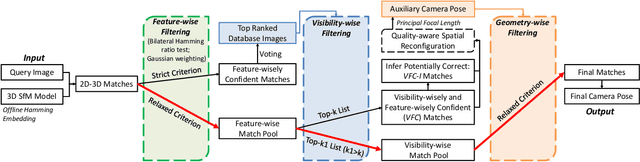
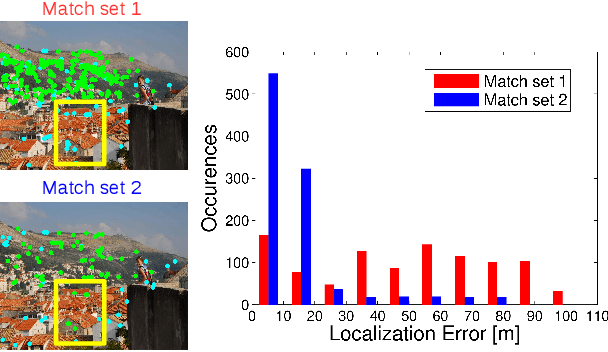
Image-based localization (IBL) aims to estimate the 6DOF camera pose for a given query image. The camera pose can be computed from 2D-3D matches between a query image and Structure-from-Motion (SfM) models. Despite recent advances in IBL, it remains difficult to simultaneously resolve the memory consumption and match ambiguity problems of large SfM models. In this work, we propose a cascaded parallel filtering method that leverages the feature, visibility and geometry information to filter wrong matches under binary feature representation. The core idea is that we divide the challenging filtering task into two parallel tasks before deriving an auxiliary camera pose for final filtering. One task focuses on preserving potentially correct matches, while another focuses on obtaining high quality matches to facilitate subsequent more powerful filtering. Moreover, our proposed method improves the localization accuracy by introducing a quality-aware spatial reconfiguration method and a principal focal length enhanced pose estimation method. Experimental results on real-world datasets demonstrate that our method achieves very competitive localization performances in a memory-efficient manner.