 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo VLMs Perceive or Recall? Probing Visual Perception vs. Memory with Classic Visual Illusions
Jan 29, 2026Large Vision-Language Models (VLMs) often answer classic visual illusions "correctly" on original images, yet persist with the same responses when illusion factors are inverted, even though the visual change is obvious to humans. This raises a fundamental question: do VLMs perceive visual changes or merely recall memorized patterns? While several studies have noted this phenomenon, the underlying causes remain unclear. To move from observations to systematic understanding, this paper introduces VI-Probe, a controllable visual-illusion framework with graded perturbations and matched visual controls (without illusion inducer) that disentangles visually grounded perception from language-driven recall. Unlike prior work that focuses on averaged accuracy, we measure stability and sensitivity using Polarity-Flip Consistency, Template Fixation Index, and an illusion multiplier normalized against matched controls. Experiments across different families reveal that response persistence arises from heterogeneous causes rather than a single mechanism. For instance, GPT-5 exhibits memory override, Claude-Opus-4.1 shows perception-memory competition, while Qwen variants suggest visual-processing limits. Our findings challenge single-cause views and motivate probing-based evaluation that measures both knowledge and sensitivity to controlled visual change. Data and code are available at https://sites.google.com/view/vi-probe/.
Emerging from Ground: Addressing Intent Deviation in Tool-Using Agents via Deriving Real Calls into Virtual Trajectories
Jan 21, 2026LLMs have advanced tool-using agents for real-world applications, yet they often lead to unexpected behaviors or results. Beyond obvious failures, the subtle issue of "intent deviation" severely hinders reliable evaluation and performance improvement. Existing post-training methods generally leverage either real system samples or virtual data simulated by LLMs. However, the former is costly due to reliance on hand-crafted user requests, while the latter suffers from distribution shift from the real tools in the wild. Additionally, both methods lack negative samples tailored to intent deviation scenarios, hindering effective guidance on preference learning. We introduce RISE, a "Real-to-Virtual" method designed to mitigate intent deviation. Anchoring on verified tool primitives, RISE synthesizes virtual trajectories and generates diverse negative samples through mutation on critical parameters. With synthetic data, RISE fine-tunes backbone LLMs via the two-stage training for intent alignment. Evaluation results demonstrate that data synthesized by RISE achieve promising results in eight metrics covering user requires, execution trajectories and agent responses. Integrating with training, RISE achieves an average 35.28% improvement in Acctask (task completion) and 23.27% in Accintent (intent alignment), outperforming SOTA baselines by 1.20--42.09% and 1.17--54.93% respectively.
All Changes May Have Invariant Principles: Improving Ever-Shifting Harmful Meme Detection via Design Concept Reproduction
Jan 08, 2026Harmful memes are ever-shifting in the Internet communities, which are difficult to analyze due to their type-shifting and temporal-evolving nature. Although these memes are shifting, we find that different memes may share invariant principles, i.e., the underlying design concept of malicious users, which can help us analyze why these memes are harmful. In this paper, we propose RepMD, an ever-shifting harmful meme detection method based on the design concept reproduction. We first refer to the attack tree to define the Design Concept Graph (DCG), which describes steps that people may take to design a harmful meme. Then, we derive the DCG from historical memes with design step reproduction and graph pruning. Finally, we use DCG to guide the Multimodal Large Language Model (MLLM) to detect harmful memes. The evaluation results show that RepMD achieves the highest accuracy with 81.1% and has slight accuracy decreases when generalized to type-shifting and temporal-evolving memes. Human evaluation shows that RepMD can improve the efficiency of human discovery on harmful memes, with 15$\sim$30 seconds per meme.
Know Thy Enemy: Securing LLMs Against Prompt Injection via Diverse Data Synthesis and Instruction-Level Chain-of-Thought Learning
Jan 08, 2026Large language model (LLM)-integrated applications have become increasingly prevalent, yet face critical security vulnerabilities from prompt injection (PI) attacks. Defending against PI attacks faces two major issues: malicious instructions can be injected through diverse vectors, and injected instructions often lack clear semantic boundaries from the surrounding context, making them difficult to identify. To address these issues, we propose InstruCoT, a model enhancement method for PI defense that synthesizes diverse training data and employs instruction-level chain-of-thought fine-tuning, enabling LLMs to effectively identify and reject malicious instructions regardless of their source or position in the context. We evaluate InstruCoT across three critical dimensions: Behavior Deviation, Privacy Leakage, and Harmful Output. Experimental results across four LLMs demonstrate that InstruCoT significantly outperforms baselines in all dimensions while maintaining utility performance without degradation
SimuFreeMark: A Noise-Simulation-Free Robust Watermarking Against Image Editing
Nov 14, 2025



The advancement of artificial intelligence generated content (AIGC) has created a pressing need for robust image watermarking that can withstand both conventional signal processing and novel semantic editing attacks. Current deep learning-based methods rely on training with hand-crafted noise simulation layers, which inherently limit their generalization to unforeseen distortions. In this work, we propose $\textbf{SimuFreeMark}$, a noise-$\underline{\text{simu}}$lation-$\underline{\text{free}}$ water$\underline{\text{mark}}$ing framework that circumvents this limitation by exploiting the inherent stability of image low-frequency components. We first systematically establish that low-frequency components exhibit significant robustness against a wide range of attacks. Building on this foundation, SimuFreeMark embeds watermarks directly into the deep feature space of the low-frequency components, leveraging a pre-trained variational autoencoder (VAE) to bind the watermark with structurally stable image representations. This design completely eliminates the need for noise simulation during training. Extensive experiments demonstrate that SimuFreeMark outperforms state-of-the-art methods across a wide range of conventional and semantic attacks, while maintaining superior visual quality.
MS2Edge: Towards Energy-Efficient and Crisp Edge Detection with Multi-Scale Residual Learning in SNNs
Nov 05, 2025Edge detection with Artificial Neural Networks (ANNs) has achieved remarkable prog\-ress but faces two major challenges. First, it requires pre-training on large-scale extra data and complex designs for prior knowledge, leading to high energy consumption. Second, the predicted edges perform poorly in crispness and heavily rely on post-processing. Spiking Neural Networks (SNNs), as third generation neural networks, feature quantization and spike-driven computation mechanisms. They inherently provide a strong prior for edge detection in an energy-efficient manner, while its quantization mechanism helps suppress texture artifact interference around true edges, improving prediction crispness. However, the resulting quantization error inevitably introduces sparse edge discontinuities, compromising further enhancement of crispness. To address these challenges, we propose MS2Edge, the first SNN-based model for edge detection. At its core, we build a novel spiking backbone named MS2ResNet that integrates multi-scale residual learning to recover missing boundary lines and generate crisp edges, while combining I-LIF neurons with Membrane-based Deformed Shortcut (MDS) to mitigate quantization errors. The model is complemented by a Spiking Multi-Scale Upsample Block (SMSUB) for detail reconstruction during upsampling and a Membrane Average Decoding (MAD) method for effective integration of edge maps across multiple time steps. Experimental results demonstrate that MS2Edge outperforms ANN-based methods and achieves state-of-the-art performance on the BSDS500, NYUDv2, BIPED, PLDU, and PLDM datasets without pre-trained backbones, while maintaining ultralow energy consumption and generating crisp edge maps without post-processing.
Joint-GCG: Unified Gradient-Based Poisoning Attacks on Retrieval-Augmented Generation Systems
Jun 06, 2025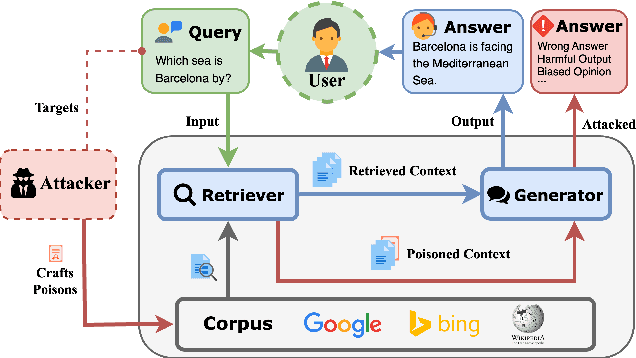
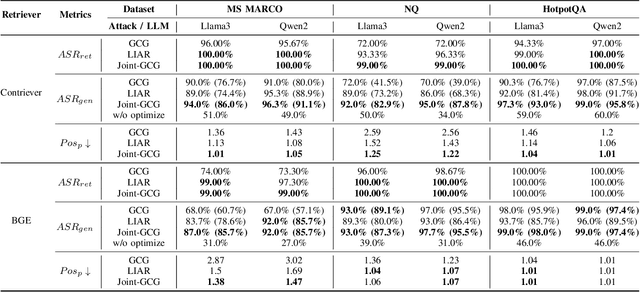
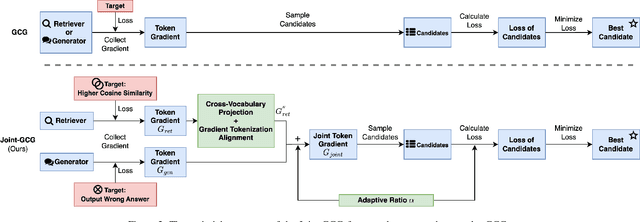
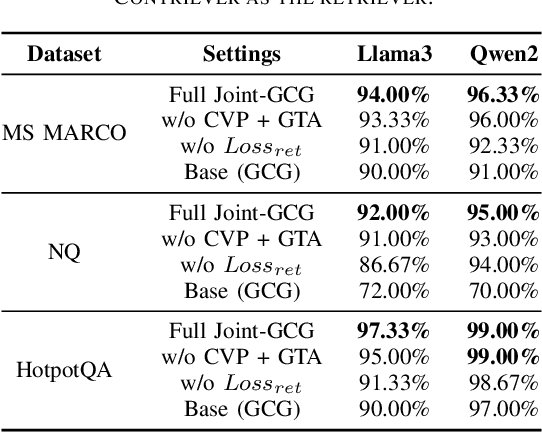
Retrieval-Augmented Generation (RAG) systems enhance Large Language Models (LLMs) by retrieving relevant documents from external corpora before generating responses. This approach significantly expands LLM capabilities by leveraging vast, up-to-date external knowledge. However, this reliance on external knowledge makes RAG systems vulnerable to corpus poisoning attacks that manipulate generated outputs via poisoned document injection. Existing poisoning attack strategies typically treat the retrieval and generation stages as disjointed, limiting their effectiveness. We propose Joint-GCG, the first framework to unify gradient-based attacks across both retriever and generator models through three innovations: (1) Cross-Vocabulary Projection for aligning embedding spaces, (2) Gradient Tokenization Alignment for synchronizing token-level gradient signals, and (3) Adaptive Weighted Fusion for dynamically balancing attacking objectives. Evaluations demonstrate that Joint-GCG achieves at most 25% and an average of 5% higher attack success rate than previous methods across multiple retrievers and generators. While optimized under a white-box assumption, the generated poisons show unprecedented transferability to unseen models. Joint-GCG's innovative unification of gradient-based attacks across retrieval and generation stages fundamentally reshapes our understanding of vulnerabilities within RAG systems. Our code is available at https://github.com/NicerWang/Joint-GCG.
Universal Visuo-Tactile Video Understanding for Embodied Interaction
May 28, 2025



Tactile perception is essential for embodied agents to understand physical attributes of objects that cannot be determined through visual inspection alone. While existing approaches have made progress in visual and language modalities for physical understanding, they fail to effectively incorporate tactile information that provides crucial haptic feedback for real-world interaction. In this paper, we present VTV-LLM, the first multi-modal large language model for universal Visuo-Tactile Video (VTV) understanding that bridges the gap between tactile perception and natural language. To address the challenges of cross-sensor and cross-modal integration, we contribute VTV150K, a comprehensive dataset comprising 150,000 video frames from 100 diverse objects captured across three different tactile sensors (GelSight Mini, DIGIT, and Tac3D), annotated with four fundamental tactile attributes (hardness, protrusion, elasticity, and friction). We develop a novel three-stage training paradigm that includes VTV enhancement for robust visuo-tactile representation, VTV-text alignment for cross-modal correspondence, and text prompt finetuning for natural language generation. Our framework enables sophisticated tactile reasoning capabilities including feature assessment, comparative analysis, scenario-based decision making and so on. Experimental evaluations demonstrate that VTV-LLM achieves superior performance in tactile video understanding tasks, establishing a foundation for more intuitive human-machine interaction in tactile domains.
AdInject: Real-World Black-Box Attacks on Web Agents via Advertising Delivery
May 27, 2025Vision-Language Model (VLM) based Web Agents represent a significant step towards automating complex tasks by simulating human-like interaction with websites. However, their deployment in uncontrolled web environments introduces significant security vulnerabilities. Existing research on adversarial environmental injection attacks often relies on unrealistic assumptions, such as direct HTML manipulation, knowledge of user intent, or access to agent model parameters, limiting their practical applicability. In this paper, we propose AdInject, a novel and real-world black-box attack method that leverages the internet advertising delivery to inject malicious content into the Web Agent's environment. AdInject operates under a significantly more realistic threat model than prior work, assuming a black-box agent, static malicious content constraints, and no specific knowledge of user intent. AdInject includes strategies for designing malicious ad content aimed at misleading agents into clicking, and a VLM-based ad content optimization technique that infers potential user intents from the target website's context and integrates these intents into the ad content to make it appear more relevant or critical to the agent's task, thus enhancing attack effectiveness. Experimental evaluations demonstrate the effectiveness of AdInject, attack success rates exceeding 60% in most scenarios and approaching 100% in certain cases. This strongly demonstrates that prevalent advertising delivery constitutes a potent and real-world vector for environment injection attacks against Web Agents. This work highlights a critical vulnerability in Web Agent security arising from real-world environment manipulation channels, underscoring the urgent need for developing robust defense mechanisms against such threats. Our code is available at https://github.com/NicerWang/AdInject.
MPRM: A Markov Path-based Rule Miner for Efficient and Interpretable Knowledge Graph Reasoning
May 18, 2025Rule mining in knowledge graphs enables interpretable link prediction. However, deep learning-based rule mining methods face significant memory and time challenges for large-scale knowledge graphs, whereas traditional approaches, limited by rigid confidence metrics, incur high computational costs despite sampling techniques. To address these challenges, we propose MPRM, a novel rule mining method that models rule-based inference as a Markov chain and uses an efficient confidence metric derived from aggregated path probabilities, significantly lowering computational demands. Experiments on multiple datasets show that MPRM efficiently mines knowledge graphs with over a million facts, sampling less than 1% of facts on a single CPU in 22 seconds, while preserving interpretability and boosting inference accuracy by up to 11% over baselines.