 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Semantic Feature Discrimination for Perceptual Image Super-Resolution and Opinion-Unaware No-Reference Image Quality Assessment
Mar 25, 2025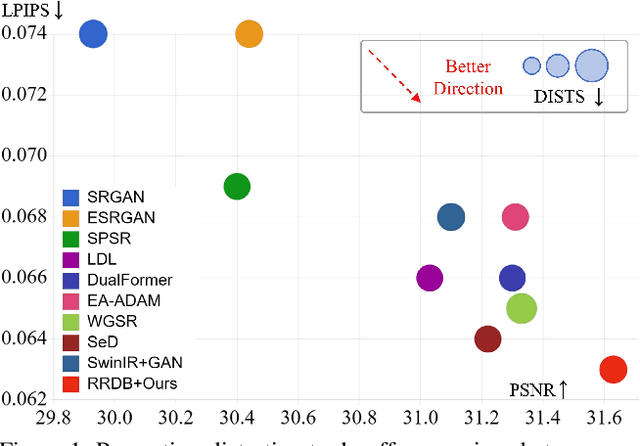
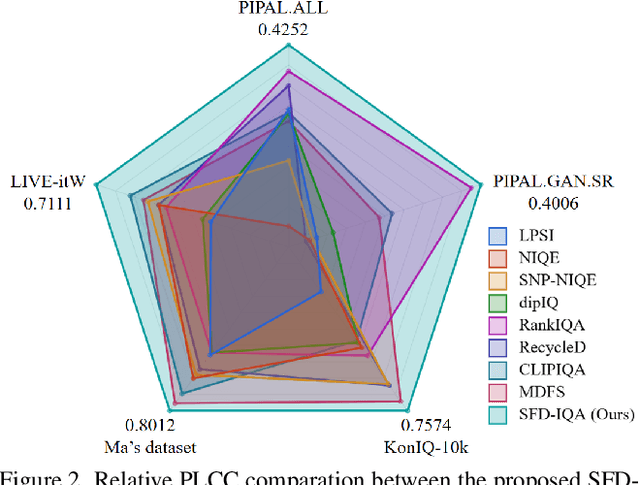
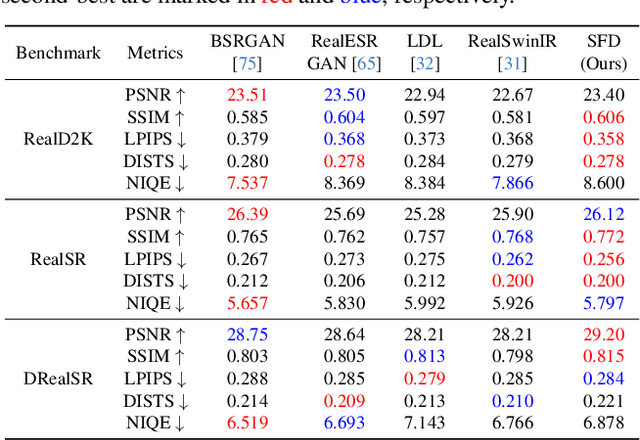
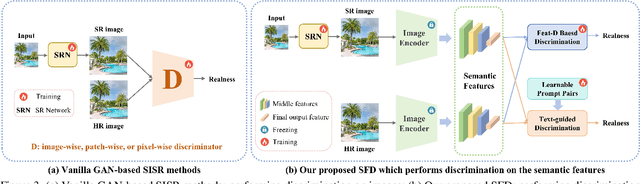
Generative Adversarial Networks (GANs) have been widely applied to image super-resolution (SR) to enhance the perceptual quality. However, most existing GAN-based SR methods typically perform coarse-grained discrimination directly on images and ignore the semantic information of images, making it challenging for the super resolution networks (SRN) to learn fine-grained and semantic-related texture details. To alleviate this issue, we propose a semantic feature discrimination method, SFD, for perceptual SR. Specifically, we first design a feature discriminator (Feat-D), to discriminate the pixel-wise middle semantic features from CLIP, aligning the feature distributions of SR images with that of high-quality images. Additionally, we propose a text-guided discrimination method (TG-D) by introducing learnable prompt pairs (LPP) in an adversarial manner to perform discrimination on the more abstract output feature of CLIP, further enhancing the discriminative ability of our method. With both Feat-D and TG-D, our SFD can effectively distinguish between the semantic feature distributions of low-quality and high-quality images, encouraging SRN to generate more realistic and semantic-relevant textures. Furthermore, based on the trained Feat-D and LPP, we propose a novel opinion-unaware no-reference image quality assessment (OU NR-IQA) method, SFD-IQA, greatly improving OU NR-IQA performance without any additional targeted training. Extensive experiments on classical SISR, real-world SISR, and OU NR-IQA tasks demonstrate the effectiveness of our proposed methods.