 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
Exploring Semantic Feature Discrimination for Perceptual Image Super-Resolution and Opinion-Unaware No-Reference Image Quality Assessment
Mar 25, 2025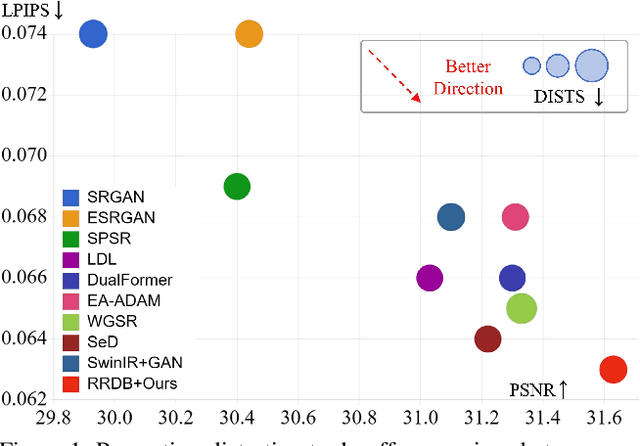
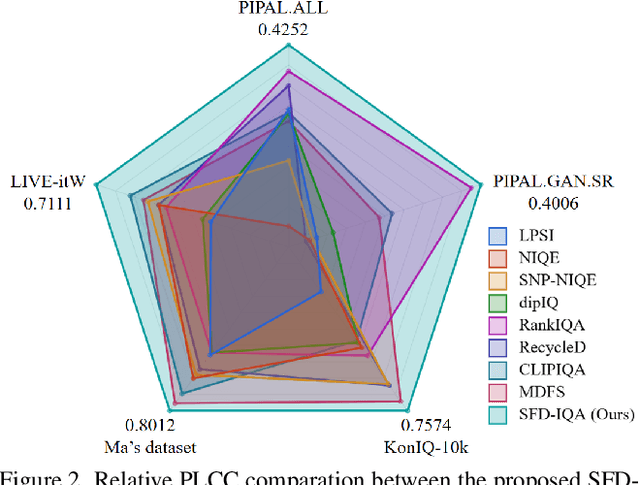
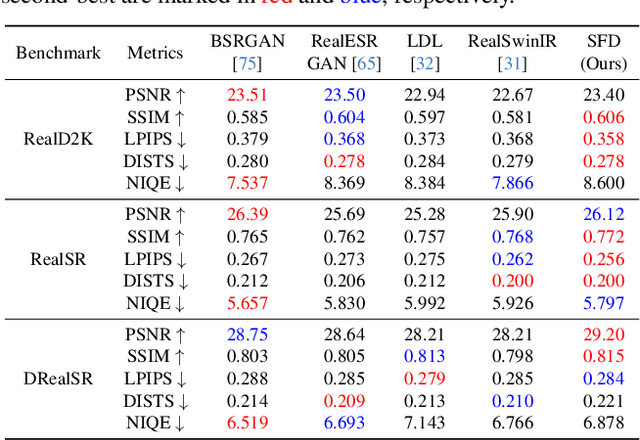
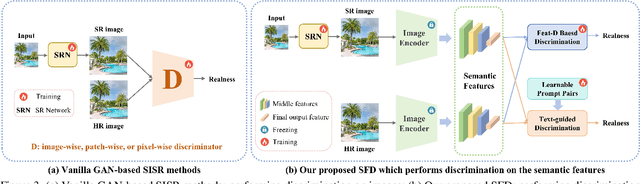
Generative Adversarial Networks (GANs) have been widely applied to image super-resolution (SR) to enhance the perceptual quality. However, most existing GAN-based SR methods typically perform coarse-grained discrimination directly on images and ignore the semantic information of images, making it challenging for the super resolution networks (SRN) to learn fine-grained and semantic-related texture details. To alleviate this issue, we propose a semantic feature discrimination method, SFD, for perceptual SR. Specifically, we first design a feature discriminator (Feat-D), to discriminate the pixel-wise middle semantic features from CLIP, aligning the feature distributions of SR images with that of high-quality images. Additionally, we propose a text-guided discrimination method (TG-D) by introducing learnable prompt pairs (LPP) in an adversarial manner to perform discrimination on the more abstract output feature of CLIP, further enhancing the discriminative ability of our method. With both Feat-D and TG-D, our SFD can effectively distinguish between the semantic feature distributions of low-quality and high-quality images, encouraging SRN to generate more realistic and semantic-relevant textures. Furthermore, based on the trained Feat-D and LPP, we propose a novel opinion-unaware no-reference image quality assessment (OU NR-IQA) method, SFD-IQA, greatly improving OU NR-IQA performance without any additional targeted training. Extensive experiments on classical SISR, real-world SISR, and OU NR-IQA tasks demonstrate the effectiveness of our proposed methods.
Channel Consistency Prior and Self-Reconstruction Strategy Based Unsupervised Image Deraining
Mar 24, 2025

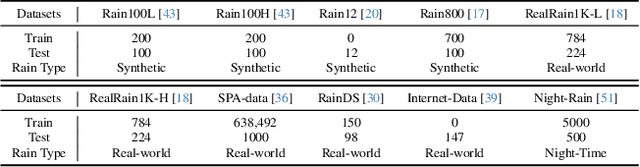
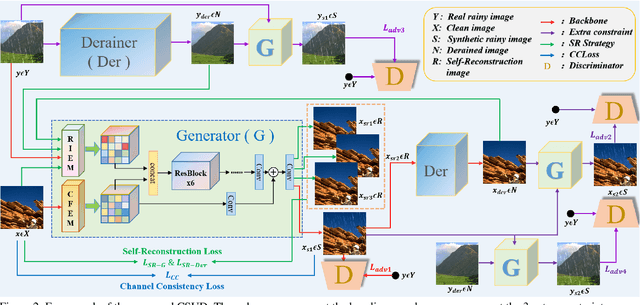
Recently, deep image deraining models based on paired datasets have made a series of remarkable progress. However, they cannot be well applied in real-world applications due to the difficulty of obtaining real paired datasets and the poor generalization performance. In this paper, we propose a novel Channel Consistency Prior and Self-Reconstruction Strategy Based Unsupervised Image Deraining framework, CSUD, to tackle the aforementioned challenges. During training with unpaired data, CSUD is capable of generating high-quality pseudo clean and rainy image pairs which are used to enhance the performance of deraining network. Specifically, to preserve more image background details while transferring rain streaks from rainy images to the unpaired clean images, we propose a novel Channel Consistency Loss (CCLoss) by introducing the Channel Consistency Prior (CCP) of rain streaks into training process, thereby ensuring that the generated pseudo rainy images closely resemble the real ones. Furthermore, we propose a novel Self-Reconstruction (SR) strategy to alleviate the redundant information transfer problem of the generator, further improving the deraining performance and the generalization capability of our method. Extensive experiments on multiple synthetic and real-world datasets demonstrate that the deraining performance of CSUD surpasses other state-of-the-art unsupervised methods and CSUD exhibits superior generalization capability.