 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsyReC: A Multimodal Graph-based Framework for Spatio-Temporal Asymmetric Dyadic Relationship Classification
Apr 07, 2025Dyadic social relationships, which refer to relationships between two individuals who know each other through repeated interactions (or not), are shaped by shared spatial and temporal experiences. Current computational methods for modeling these relationships face three major challenges: (1) the failure to model asymmetric relationships, e.g., one individual may perceive the other as a friend while the other perceives them as an acquaintance, (2) the disruption of continuous interactions by discrete frame sampling, which segments the temporal continuity of interaction in real-world scenarios, and (3) the limitation to consider periodic behavioral cues, such as rhythmic vocalizations or recurrent gestures, which are crucial for inferring the evolution of dyadic relationships. To address these challenges, we propose AsyReC, a multimodal graph-based framework for asymmetric dyadic relationship classification, with three core innovations: (i) a triplet graph neural network with node-edge dual attention that dynamically weights multimodal cues to capture interaction asymmetries (addressing challenge 1); (ii) a clip-level relationship learning architecture that preserves temporal continuity, enabling fine-grained modeling of real-world interaction dynamics (addressing challenge 2); and (iii) a periodic temporal encoder that projects time indices onto sine/cosine waveforms to model recurrent behavioral patterns (addressing challenge 3). Extensive experiments on two public datasets demonstrate state-of-the-art performance, while ablation studies validate the critical role of asymmetric interaction modeling and periodic temporal encoding in improving the robustness of dyadic relationship classification in real-world scenarios. Our code is publicly available at: https://github.com/tw-repository/AsyReC.
Channel Consistency Prior and Self-Reconstruction Strategy Based Unsupervised Image Deraining
Mar 24, 2025

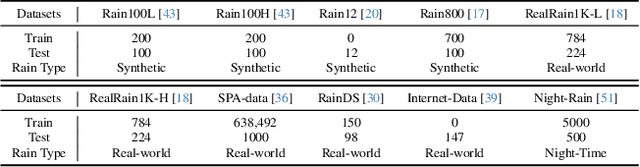
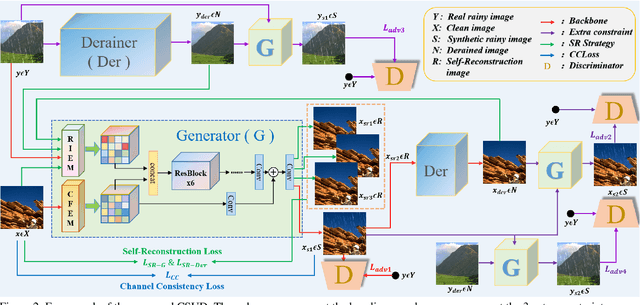
Recently, deep image deraining models based on paired datasets have made a series of remarkable progress. However, they cannot be well applied in real-world applications due to the difficulty of obtaining real paired datasets and the poor generalization performance. In this paper, we propose a novel Channel Consistency Prior and Self-Reconstruction Strategy Based Unsupervised Image Deraining framework, CSUD, to tackle the aforementioned challenges. During training with unpaired data, CSUD is capable of generating high-quality pseudo clean and rainy image pairs which are used to enhance the performance of deraining network. Specifically, to preserve more image background details while transferring rain streaks from rainy images to the unpaired clean images, we propose a novel Channel Consistency Loss (CCLoss) by introducing the Channel Consistency Prior (CCP) of rain streaks into training process, thereby ensuring that the generated pseudo rainy images closely resemble the real ones. Furthermore, we propose a novel Self-Reconstruction (SR) strategy to alleviate the redundant information transfer problem of the generator, further improving the deraining performance and the generalization capability of our method. Extensive experiments on multiple synthetic and real-world datasets demonstrate that the deraining performance of CSUD surpasses other state-of-the-art unsupervised methods and CSUD exhibits superior generalization capability.
Real-World Single Image Super-Resolution: A Brief Review
Mar 03, 2021

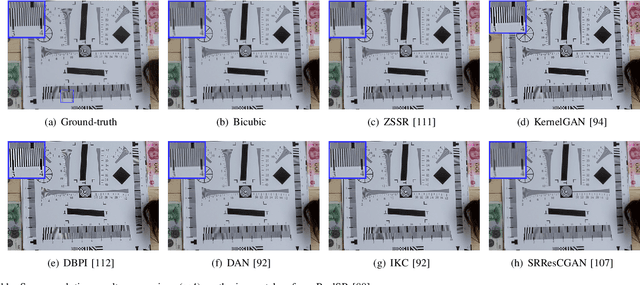
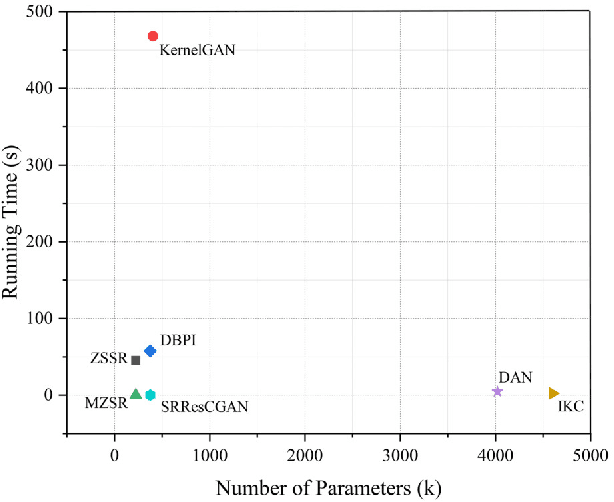
Single image super-resolution (SISR), which aims to reconstruct a high-resolution (HR) image from a low-resolution (LR) observation, has been an active research topic in the area of image processing in recent decades. Particularly, deep learning-based super-resolution (SR) approaches have drawn much attention and have greatly improved the reconstruction performance on synthetic data. Recent studies show that simulation results on synthetic data usually overestimate the capacity to super-resolve real-world images. In this context, more and more researchers devote themselves to develop SR approaches for realistic images. This article aims to make a comprehensive review on real-world single image super-resolution (RSISR). More specifically, this review covers the critical publically available datasets and assessment metrics for RSISR, and four major categories of RSISR methods, namely the degradation modeling-based RSISR, image pairs-based RSISR, domain translation-based RSISR, and self-learning-based RSISR. Comparisons are also made among representative RSISR methods on benchmark datasets, in terms of both reconstruction quality and computational efficiency. Besides, we discuss challenges and promising research topics on RSISR.
DPW-SDNet: Dual Pixel-Wavelet Domain Deep CNNs for Soft Decoding of JPEG-Compressed Images
May 27, 2018
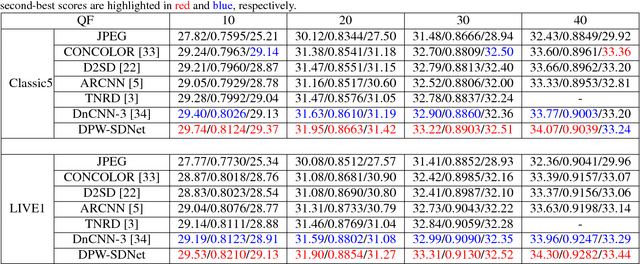
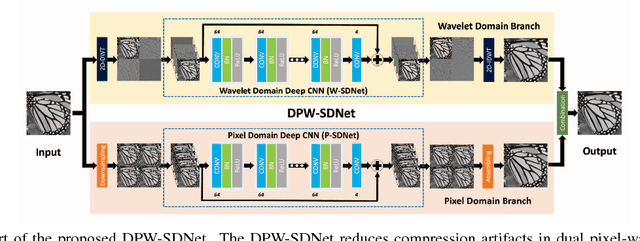
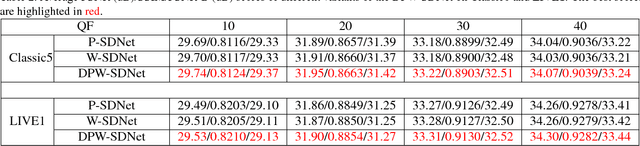
JPEG is one of the widely used lossy compression methods. JPEG-compressed images usually suffer from compression artifacts including blocking and blurring, especially at low bit-rates. Soft decoding is an effective solution to improve the quality of compressed images without changing codec or introducing extra coding bits. Inspired by the excellent performance of the deep convolutional neural networks (CNNs) on both low-level and high-level computer vision problems, we develop a dual pixel-wavelet domain deep CNNs-based soft decoding network for JPEG-compressed images, namely DPW-SDNet. The pixel domain deep network takes the four downsampled versions of the compressed image to form a 4-channel input and outputs a pixel domain prediction, while the wavelet domain deep network uses the 1-level discrete wavelet transformation (DWT) coefficients to form a 4-channel input to produce a DWT domain prediction. The pixel domain and wavelet domain estimates are combined to generate the final soft decoded result. Experimental results demonstrate the superiority of the proposed DPW-SDNet over several state-of-the-art compression artifacts reduction algorithms.
CISRDCNN: Super-resolution of compressed images using deep convolutional neural networks
Sep 19, 2017
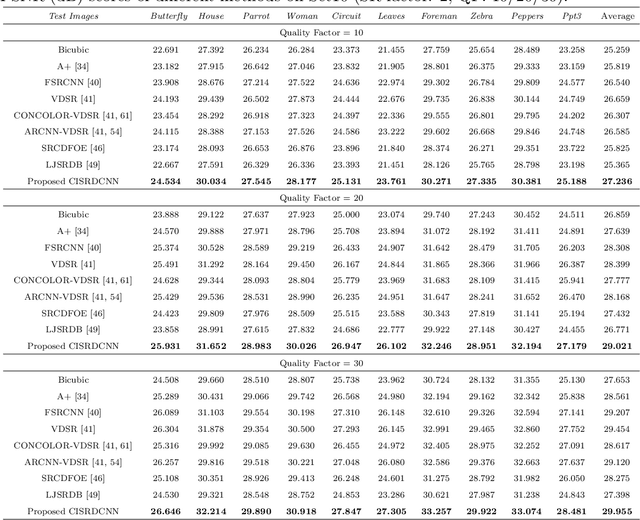
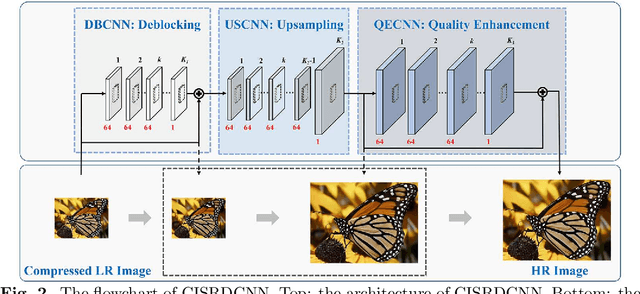
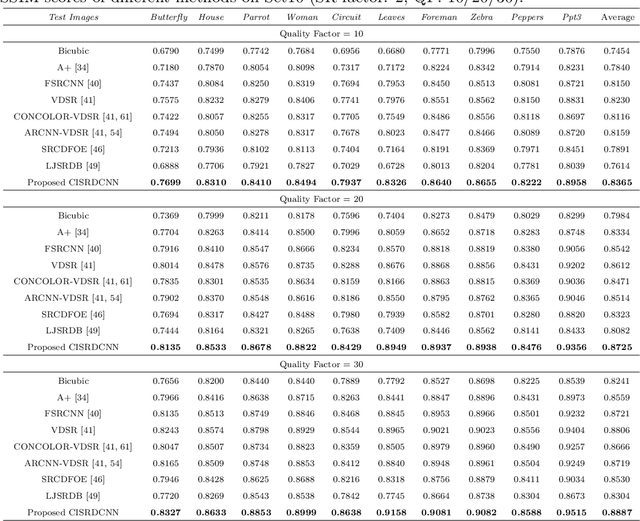
In recent years, much research has been conducted on image super-resolution (SR). To the best of our knowledge, however, few SR methods were concerned with compressed images. The SR of compressed images is a challenging task due to the complicated compression artifacts, while many images suffer from them in practice. The intuitive solution for this difficult task is to decouple it into two sequential but independent subproblems, i.e., compression artifacts reduction (CAR) and SR. Nevertheless, some useful details may be removed in CAR stage, which is contrary to the goal of SR and makes the SR stage more challenging. In this paper, an end-to-end trainable deep convolutional neural network is designed to perform SR on compressed images (CISRDCNN), which reduces compression artifacts and improves image resolution jointly. Experiments on compressed images produced by JPEG (we take the JPEG as an example in this paper) demonstrate that the proposed CISRDCNN yields state-of-the-art SR performance on commonly used test images and imagesets. The results of CISRDCNN on real low quality web images are also very impressive, with obvious quality enhancement. Further, we explore the application of the proposed SR method in low bit-rate image coding, leading to better rate-distortion performance than JPEG.