 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning-Based Secure Near-field Directional Modulation Enhanced by Rotatable RIS
Mar 21, 2026This paper investigates secure Directional Modulation (DM) design enhanced by a rotatable active Reconfigurable Intelligent Surface (RIS). In conventional RIS-assisted DM networks, the security performance gain is limited due to the multiplicative path loss introduced by the RIS reflection path. To address this challenge, a Secrecy Rate (SR) maximization problem is formulated, subject to constraints including the eavesdropper's Direction Of Arrival (DOA) estimation performance, transmit power, rotatable range, and maximum reflection amplitude of the RIS elements. To solve this non-convex optimization problem, three algorithms are proposed: a multi-stream null-space projection and leakage-based method, an enhanced leakage-based method, and an optimization scheme based on the Distributed Soft Actor-Critic with Three refinements (DSAC-T). Simulation results validate the effectiveness of the proposed algorithms. A performance trade-off is observed between eavesdropper's DOA estimation accuracy and the achievable SR. The security enhancement provided by the RIS is more significant in systems equipped with a small number of antennas. By optimizing the orientation of the RIS, a 52.6\% improvement in SR performance can be achieved.
ScalingNote: Scaling up Retrievers with Large Language Models for Real-World Dense Retrieval
Nov 24, 2024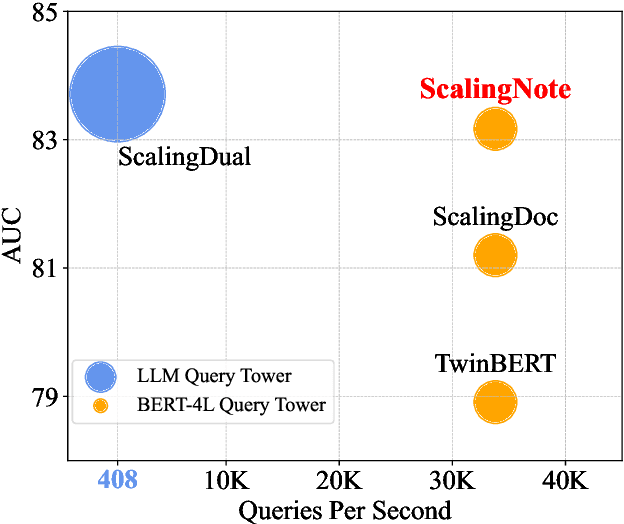
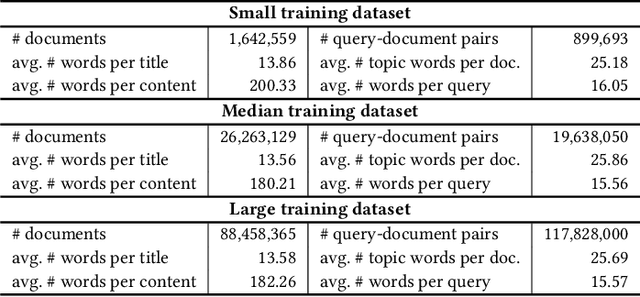
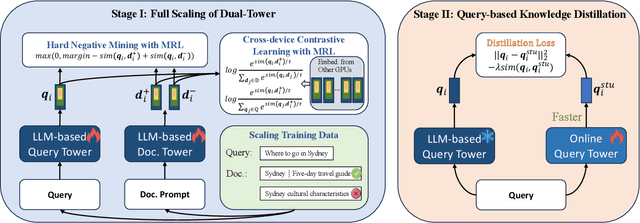
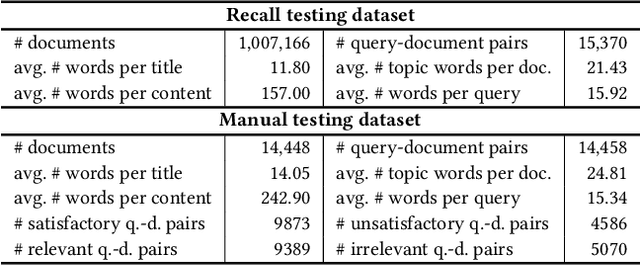
Dense retrieval in most industries employs dual-tower architectures to retrieve query-relevant documents. Due to online deployment requirements, existing real-world dense retrieval systems mainly enhance performance by designing negative sampling strategies, overlooking the advantages of scaling up. Recently, Large Language Models (LLMs) have exhibited superior performance that can be leveraged for scaling up dense retrieval. However, scaling up retrieval models significantly increases online query latency. To address this challenge, we propose ScalingNote, a two-stage method to exploit the scaling potential of LLMs for retrieval while maintaining online query latency. The first stage is training dual towers, both initialized from the same LLM, to unlock the potential of LLMs for dense retrieval. Then, we distill only the query tower using mean squared error loss and cosine similarity to reduce online costs. Through theoretical analysis and comprehensive offline and online experiments, we show the effectiveness and efficiency of ScalingNote. Our two-stage scaling method outperforms end-to-end models and verifies the scaling law of dense retrieval with LLMs in industrial scenarios, enabling cost-effective scaling of dense retrieval systems. Our online method incorporating ScalingNote significantly enhances the relevance between retrieved documents and queries.
Hierarchical Skip Decoding for Efficient Autoregressive Text Generation
Mar 22, 2024Autoregressive decoding strategy is a commonly used method for text generation tasks with pre-trained language models, while early-exiting is an effective approach to speedup the inference stage. In this work, we propose a novel decoding strategy named Hierarchical Skip Decoding (HSD) for efficient autoregressive text generation. Different from existing methods that require additional trainable components, HSD is a plug-and-play method applicable to autoregressive text generation models, it adaptively skips decoding layers in a hierarchical manner based on the current sequence length, thereby reducing computational workload and allocating computation resources. Comprehensive experiments on five text generation datasets with pre-trained language models demonstrate HSD's advantages in balancing efficiency and text quality. With almost half of the layers skipped, HSD can sustain 90% of the text quality compared to vanilla autoregressive decoding, outperforming the competitive approaches.
Beamforming Design for IRS-and-UAV-aided Two-way Amplify-and-Forward Relay Networks
Jun 01, 2023As a promising solution to improve communication quality, unmanned aerial vehicle (UAV) has been widely integrated into wireless networks. In this paper, for the sake of enhancing the message exchange rate between User1 (U1) and User2 (U2), an intelligent reflective surface (IRS)-and-UAV- assisted two-way amplify-and-forward (AF) relay wireless system is proposed, where U1 and U2 can communicate each other via a UAV-mounted IRS and an AF relay. Besides, an optimization problem of maximizing minimum rate is casted, where the variables, namely AF relay beamforming matrix and IRS phase shifts of two time slots, need to be optimized. To achieve a maximum rate, a low-complexity alternately iterative (AI) scheme based on zero forcing and successive convex approximation (LC-ZF-SCA) algorithm is put forward, where the expression of AF relay beamforming matrix can be derived in semi-closed form by ZF method, and IRS phase shift vectors of two time slots can be respectively optimized by utilizing SCA algorithm. To obtain a significant rate enhancement, a high-performance AI method based on one step, semidefinite programming and penalty SCA (ONS-SDP-PSCA) is proposed, where the beamforming matrix at AF relay can be firstly solved by singular value decomposition and ONS method, IRS phase shift matrices of two time slots are optimized by SDP and PSCA algorithms. Simulation results present that the rate performance of the proposed LC-ZF-SCA and ONS-SDP-PSCA methods surpass those of random phase and only AF relay. In particular, when total transmit power is equal to 30dBm, the proposed two methods can harvest more than 68.5% rate gain compared to random phase and only AF relay. Meanwhile, the rate performance of ONS-SDP-PSCA method at cost of extremely high complexity is superior to that of LC-ZF-SCA method.
Parameter-Efficient Fine-Tuning with Layer Pruning on Free-Text Sequence-to-Sequence Modeling
May 19, 2023The increasing size of language models raises great research interests in parameter-efficient fine-tuning such as LoRA that freezes the pre-trained model, and injects small-scale trainable parameters for multiple downstream tasks (e.g., summarization, question answering and translation). To further enhance the efficiency of fine-tuning, we propose a framework that integrates LoRA and structured layer pruning. The integrated framework is validated on two created deidentified medical report summarization datasets based on MIMIC-IV-Note and two public medical dialogue datasets. By tuning 0.6% parameters of the original model and pruning over 30% Transformer-layers, our framework can reduce 50% of GPU memory usage and speed up 100% of the training phase, while preserving over 92% generation qualities on free-text sequence-to-sequence tasks.
Leveraging Summary Guidance on Medical Report Summarization
Feb 08, 2023This study presents three deidentified large medical text datasets, named DISCHARGE, ECHO and RADIOLOGY, which contain 50K, 16K and 378K pairs of report and summary that are derived from MIMIC-III, respectively. We implement convincing baselines of automated abstractive summarization on the proposed datasets with pre-trained encoder-decoder language models, including BERT2BERT, T5-large and BART. Further, based on the BART model, we leverage the sampled summaries from the train set as prior knowledge guidance, for encoding additional contextual representations of the guidance with the encoder and enhancing the decoding representations in the decoder. The experimental results confirm the improvement of ROUGE scores and BERTScore made by the proposed method, outperforming the larger model T5-large.
Rapid Phase Ambiguity Elimination Methods for DOA Estimator via Hybrid Massive MIMO Receive Array
Apr 27, 2022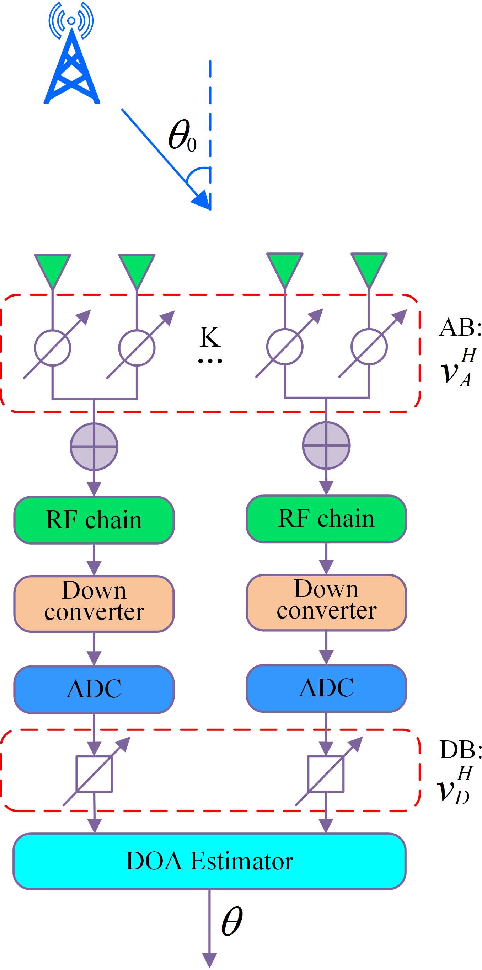
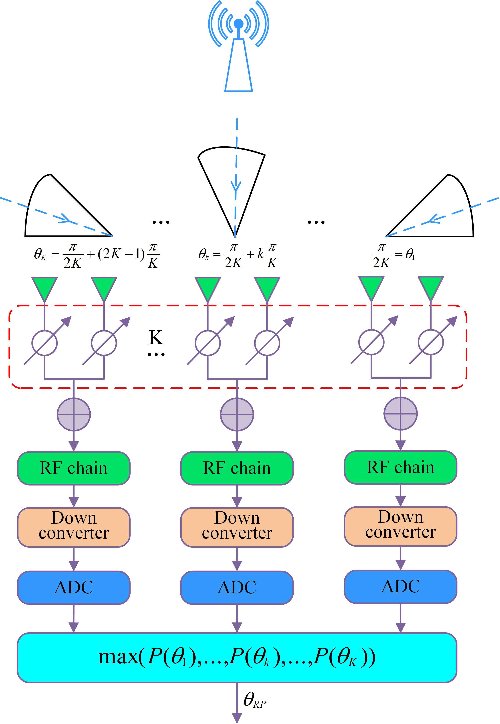
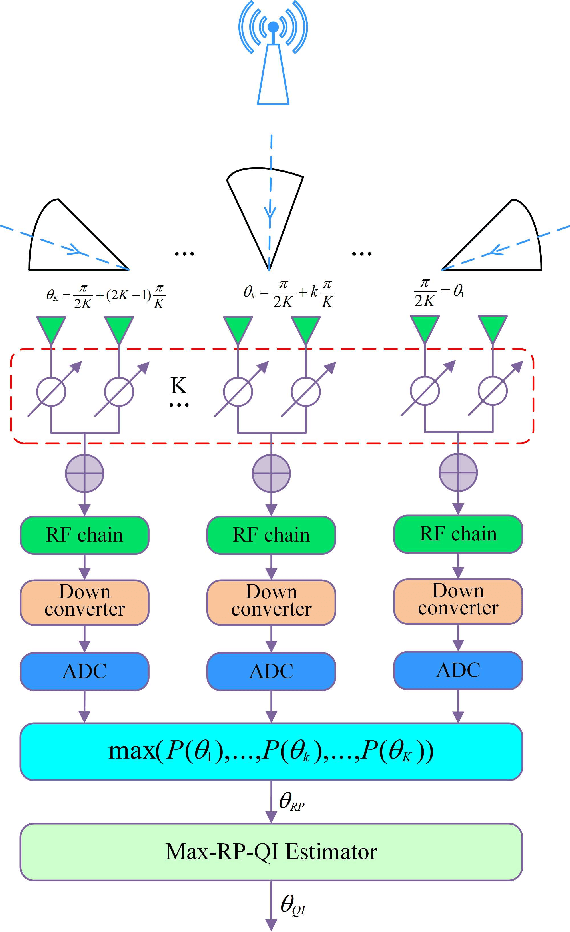
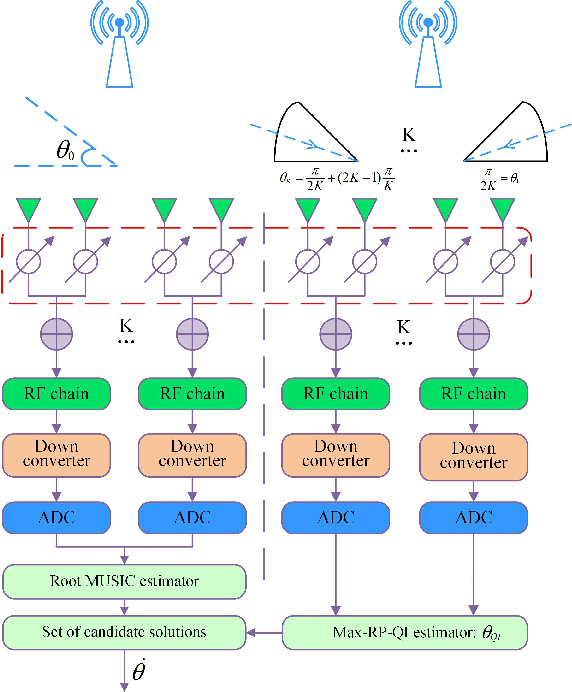
For a sub-connected hybrid multiple-input multiple-output (MIMO) receiver with $K$ subarrays and $N$ antennas, there exists a challenging problem of how to rapidly remove phase ambiguity in only single time-slot. First, a DOA estimator of maximizing received power (Max-RP) is proposed to find the maximum value of $K$-subarray output powers, where each subarray is in charge of one sector, and the center angle of the sector corresponding to the maximum output is the estimated true DOA. To make an enhancement on precision, Max-RP plus quadratic interpolation (Max-RP-QI) method is designed. In the proposed Max-RP-QI, a quadratic interpolation scheme is adopted to interpolate the three DOA values corresponding to the largest three receive powers of Max-RP. Finally, to achieve the CRLB, a Root-MUSIC plus Max-RP-QI scheme is developed. Simulation results show that the proposed three methods eliminate the phase ambiguity during one time-slot and also show low-computational-complexities. In particular, the proposed Root-MUSIC plus Max-RP-QI scheme can reach the CRLB, and the proposed Max-RP and Max-RP-QI are still some performance losses $2dB\thicksim4dB$ compared to the CRLB.
Spatial Modulation: an Attractive Secure Solution to Future Wireless Network
Mar 06, 2021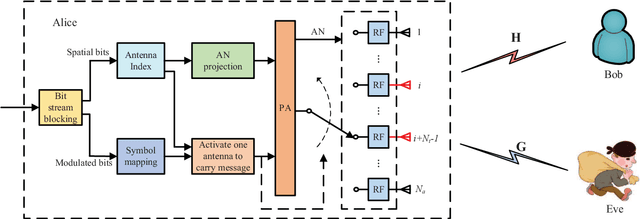
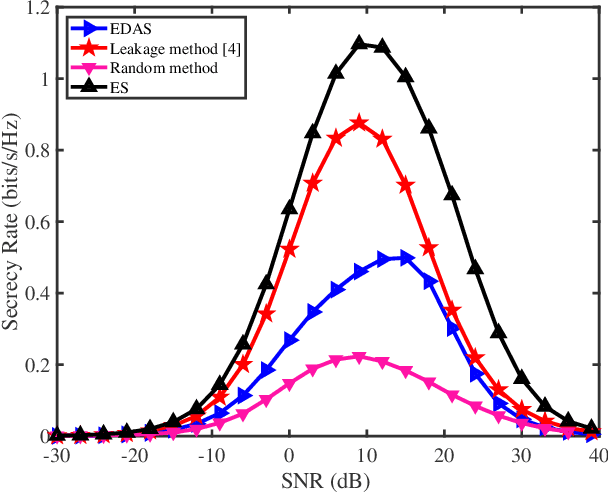
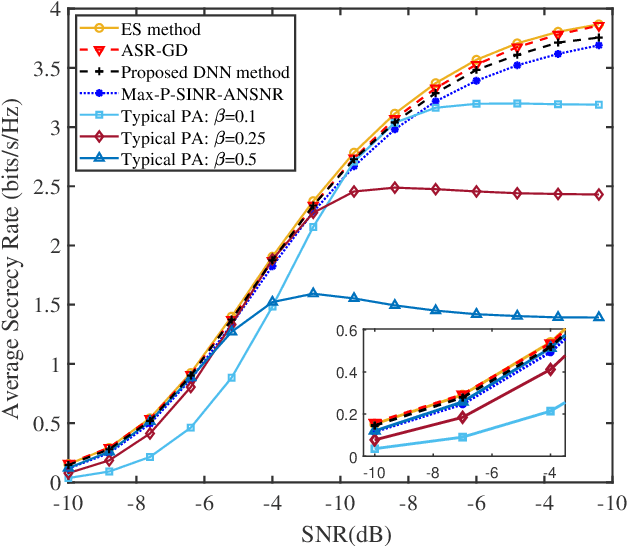
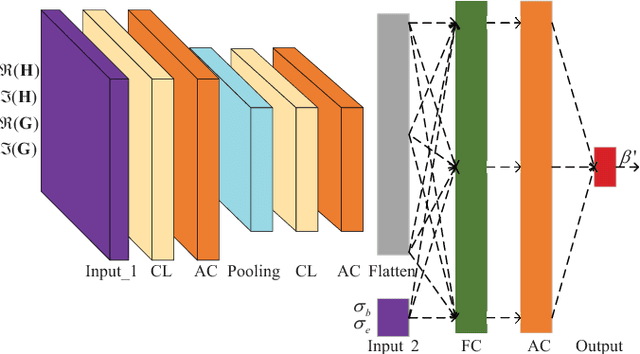
As a green and secure wireless transmission method, secure spatial modulation (SM) is becoming a hot research area. Its basic idea is to exploit both the index of activated transmit antenna and amplitude phase modulation signal to carry messages, improve security, and save energy. In this paper, we review its crucial challenges: transmit antenna selection (TAS), artificial noise (AN) projection, power allocation (PA) and joint detection at the desired receiver. As the size of signal constellation tends to medium-scale or large-scale, the complexity of traditional maximum likelihood detector becomes prohibitive. To reduce this complexity, a low-complexity maximum likelihood (ML) detector is proposed. To further enhance the secrecy rate (SR) performance, a deep-neural-network (DNN) PA strategy is proposed. Simulation results show that the proposed low-complexity ML detector, with a lower-complexity, has the same bit error rate performance as the joint ML method while the proposed DNN method strikes a good balance between complexity and SR performance.
Real-World Single Image Super-Resolution: A Brief Review
Mar 03, 2021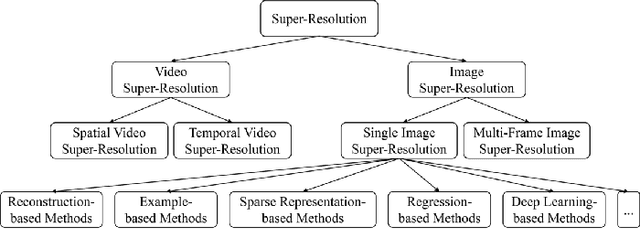

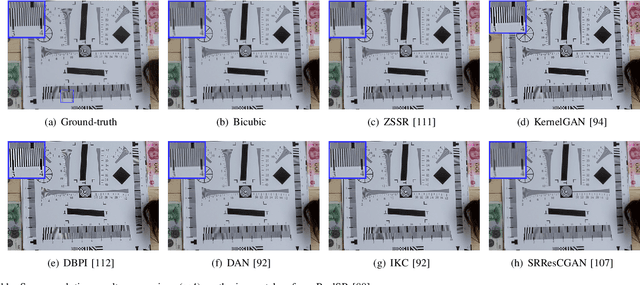
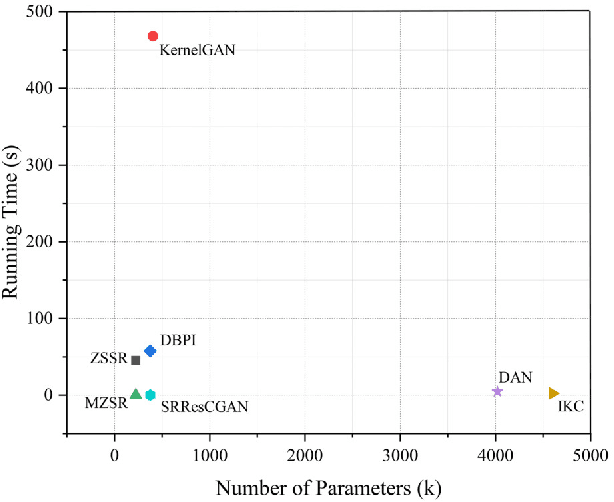
Single image super-resolution (SISR), which aims to reconstruct a high-resolution (HR) image from a low-resolution (LR) observation, has been an active research topic in the area of image processing in recent decades. Particularly, deep learning-based super-resolution (SR) approaches have drawn much attention and have greatly improved the reconstruction performance on synthetic data. Recent studies show that simulation results on synthetic data usually overestimate the capacity to super-resolve real-world images. In this context, more and more researchers devote themselves to develop SR approaches for realistic images. This article aims to make a comprehensive review on real-world single image super-resolution (RSISR). More specifically, this review covers the critical publically available datasets and assessment metrics for RSISR, and four major categories of RSISR methods, namely the degradation modeling-based RSISR, image pairs-based RSISR, domain translation-based RSISR, and self-learning-based RSISR. Comparisons are also made among representative RSISR methods on benchmark datasets, in terms of both reconstruction quality and computational efficiency. Besides, we discuss challenges and promising research topics on RSISR.
Long-Range Motion Trajectories Extraction of Articulated Human Using Mesh Evolution
Mar 29, 2016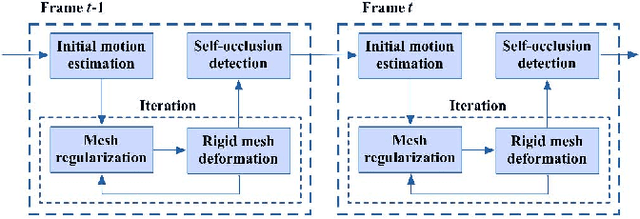
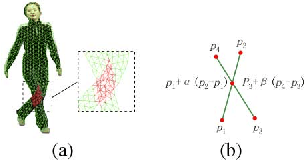

This letter presents a novel approach to extract reliable dense and long-range motion trajectories of articulated human in a video sequence. Compared with existing approaches that emphasize temporal consistency of each tracked point, we also consider the spatial structure of tracked points on the articulated human. We treat points as a set of vertices, and build a triangle mesh to join them in image space. The problem of extracting long-range motion trajectories is changed to the issue of consistency of mesh evolution over time. First, self-occlusion is detected by a novel mesh-based method and an adaptive motion estimation method is proposed to initialize mesh between successive frames. Furthermore, we propose an iterative algorithm to efficiently adjust vertices of mesh for a physically plausible deformation, which can meet the local rigidity of mesh and silhouette constraints. Finally, we compare the proposed method with the state-of-the-art methods on a set of challenging sequences. Evaluations demonstrate that our method achieves favorable performance in terms of both accuracy and integrity of extracted trajectories.