 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
Jan 12, 2026While Mixture-of-Experts (MoE) scales capacity via conditional computation, Transformers lack a native primitive for knowledge lookup, forcing them to inefficiently simulate retrieval through computation. To address this, we introduce conditional memory as a complementary sparsity axis, instantiated via Engram, a module that modernizes classic $N$-gram embedding for O(1) lookup. By formulating the Sparsity Allocation problem, we uncover a U-shaped scaling law that optimizes the trade-off between neural computation (MoE) and static memory (Engram). Guided by this law, we scale Engram to 27B parameters, achieving superior performance over a strictly iso-parameter and iso-FLOPs MoE baseline. Most notably, while the memory module is expected to aid knowledge retrieval (e.g., MMLU +3.4; CMMLU +4.0), we observe even larger gains in general reasoning (e.g., BBH +5.0; ARC-Challenge +3.7) and code/math domains~(HumanEval +3.0; MATH +2.4). Mechanistic analyses reveal that Engram relieves the backbone's early layers from static reconstruction, effectively deepening the network for complex reasoning. Furthermore, by delegating local dependencies to lookups, it frees up attention capacity for global context, substantially boosting long-context retrieval (e.g., Multi-Query NIAH: 84.2 to 97.0). Finally, Engram establishes infrastructure-aware efficiency: its deterministic addressing enables runtime prefetching from host memory, incurring negligible overhead. We envision conditional memory as an indispensable modeling primitive for next-generation sparse models.
AgentOCR: Reimagining Agent History via Optical Self-Compression
Jan 08, 2026Recent advances in large language models (LLMs) enable agentic systems trained with reinforcement learning (RL) over multi-turn interaction trajectories, but practical deployment is bottlenecked by rapidly growing textual histories that inflate token budgets and memory usage. We introduce AgentOCR, a framework that exploits the superior information density of visual tokens by representing the accumulated observation-action history as a compact rendered image. To make multi-turn rollouts scalable, AgentOCR proposes segment optical caching. By decomposing history into hashable segments and maintaining a visual cache, this mechanism eliminates redundant re-rendering. Beyond fixed rendering, AgentOCR introduces agentic self-compression, where the agent actively emits a compression rate and is trained with compression-aware reward to adaptively balance task success and token efficiency. We conduct extensive experiments on challenging agentic benchmarks, ALFWorld and search-based QA. Remarkably, results demonstrate that AgentOCR preserves over 95\% of text-based agent performance while substantially reducing token consumption (>50\%), yielding consistent token and memory efficiency. Our further analysis validates a 20x rendering speedup from segment optical caching and the effective strategic balancing of self-compression.
Reasoning via Video: The First Evaluation of Video Models' Reasoning Abilities through Maze-Solving Tasks
Nov 19, 2025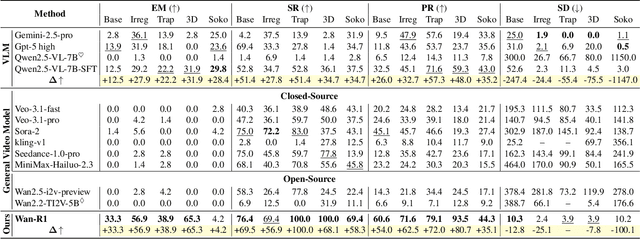

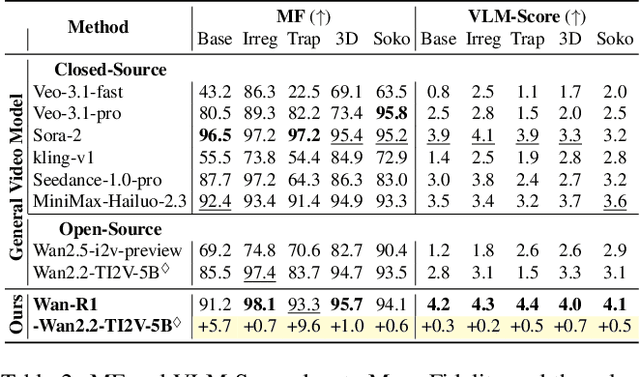
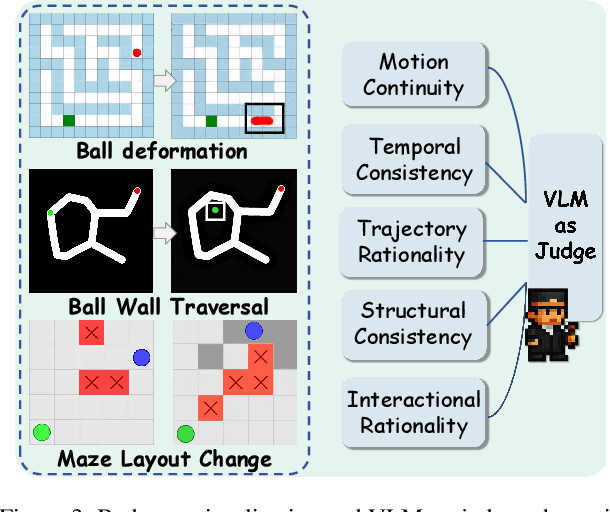
Video Models have achieved remarkable success in high-fidelity video generation with coherent motion dynamics. Analogous to the development from text generation to text-based reasoning in language modeling, the development of video models motivates us to ask: Can video models reason via video generation? Compared with the discrete text corpus, video grounds reasoning in explicit spatial layouts and temporal continuity, which serves as an ideal substrate for spatial reasoning. In this work, we explore the reasoning via video paradigm and introduce VR-Bench -- a comprehensive benchmark designed to systematically evaluate video models' reasoning capabilities. Grounded in maze-solving tasks that inherently require spatial planning and multi-step reasoning, VR-Bench contains 7,920 procedurally generated videos across five maze types and diverse visual styles. Our empirical analysis demonstrates that SFT can efficiently elicit the reasoning ability of video model. Video models exhibit stronger spatial perception during reasoning, outperforming leading VLMs and generalizing well across diverse scenarios, tasks, and levels of complexity. We further discover a test-time scaling effect, where diverse sampling during inference improves reasoning reliability by 10--20%. These findings highlight the unique potential and scalability of reasoning via video for spatial reasoning tasks.
WildSpoof Challenge Evaluation Plan
Aug 23, 2025The WildSpoof Challenge aims to advance the use of in-the-wild data in two intertwined speech processing tasks. It consists of two parallel tracks: (1) Text-to-Speech (TTS) synthesis for generating spoofed speech, and (2) Spoofing-robust Automatic Speaker Verification (SASV) for detecting spoofed speech. While the organizers coordinate both tracks and define the data protocols, participants treat them as separate and independent tasks. The primary objectives of the challenge are: (i) to promote the use of in-the-wild data for both TTS and SASV, moving beyond conventional clean and controlled datasets and considering real-world scenarios; and (ii) to encourage interdisciplinary collaboration between the spoofing generation (TTS) and spoofing detection (SASV) communities, thereby fostering the development of more integrated, robust, and realistic systems.
Millimeter-Wave Position Sensing Using Reconfigurable Intelligent Surfaces: Positioning Error Bound and Phase Shift Configuration
Aug 09, 2025



Millimeter-wave (mmWave) positioning has emerged as a promising technology for next-generation intelligent systems. The advent of reconfigurable intelligent surfaces (RISs) has revolutionized high-precision mmWave localization by enabling dynamic manipulation of wireless propagation environments. This paper investigates a three-dimensional (3D) multi-input single-output (MISO) mmWave positioning system assisted by multiple RISs. We introduce a measurement framework incorporating sequential RIS activation and directional beamforming to fully exploit virtual line-of-sight (VLoS) paths. The theoretical performance limits are rigorously analyzed through derivation of the Fisher information and subsequent positioning error bound (PEB). To minimize the PEB, two distinct optimization approaches are proposed for continuous and discrete phase shift configurations of RISs. For continuous phase shifts, a Riemannian manifold-based optimization algorithm is proposed. For discrete phase shifts, a heuristic algorithm incorporating the grey wolf optimizer is proposed. Extensive numerical simulations demonstrate the effectiveness of the proposed algorithms in reducing the PEB and validate the improvement in positioning accuracy achieved by multiple RISs.
DeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
Cycle-Constrained Adversarial Denoising Convolutional Network for PET Image Denoising: Multi-Dimensional Validation on Large Datasets with Reader Study and Real Low-Dose Data
Oct 31, 2024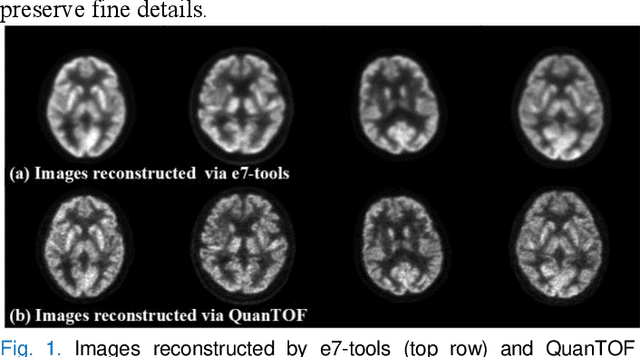
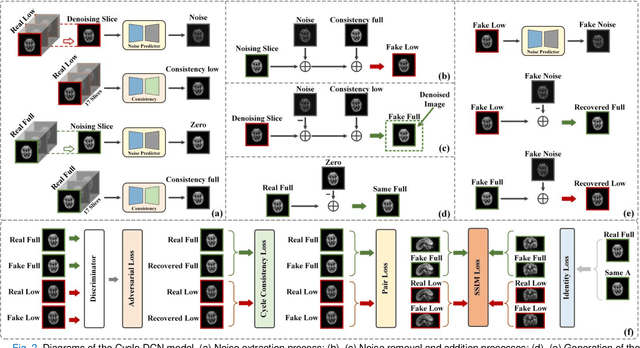
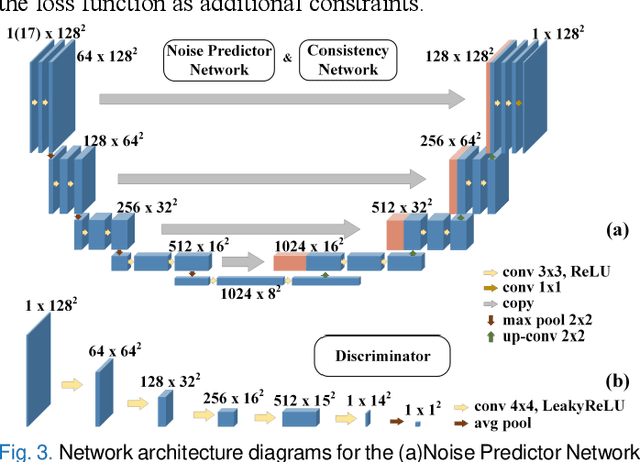
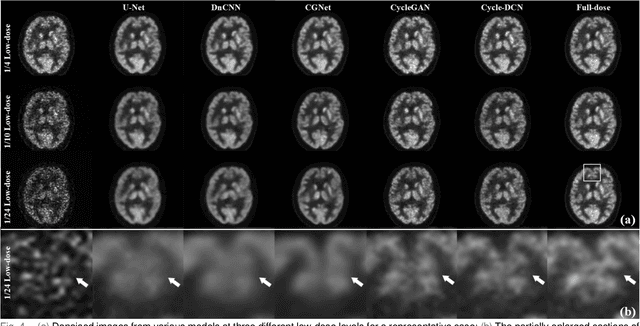
Positron emission tomography (PET) is a critical tool for diagnosing tumors and neurological disorders but poses radiation risks to patients, particularly to sensitive populations. While reducing injected radiation dose mitigates this risk, it often compromises image quality. To reconstruct full-dose-quality images from low-dose scans, we propose a Cycle-constrained Adversarial Denoising Convolutional Network (Cycle-DCN). This model integrates a noise predictor, two discriminators, and a consistency network, and is optimized using a combination of supervised loss, adversarial loss, cycle consistency loss, identity loss, and neighboring Structural Similarity Index (SSIM) loss. Experiments were conducted on a large dataset consisting of raw PET brain data from 1,224 patients, acquired using a Siemens Biograph Vision PET/CT scanner. Each patient underwent a 120-seconds brain scan. To simulate low-dose PET conditions, images were reconstructed from shortened scan durations of 30, 12, and 5 seconds, corresponding to 1/4, 1/10, and 1/24 of the full-dose acquisition, respectively, using a custom-developed GPU-based image reconstruction software. The results show that Cycle-DCN significantly improves average Peak Signal-to-Noise Ratio (PSNR), SSIM, and Normalized Root Mean Square Error (NRMSE) across three dose levels, with improvements of up to 56%, 35%, and 71%, respectively. Additionally, it achieves contrast-to-noise ratio (CNR) and Edge Preservation Index (EPI) values that closely align with full-dose images, effectively preserving image details, tumor shape, and contrast, while resolving issues with blurred edges. The results of reader studies indicated that the images restored by Cycle-DCN consistently received the highest ratings from nuclear medicine physicians, highlighting their strong clinical relevance.
AFlow: Automating Agentic Workflow Generation
Oct 14, 2024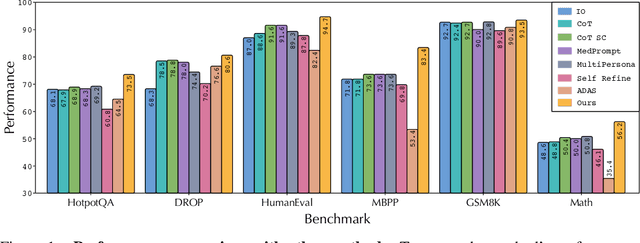

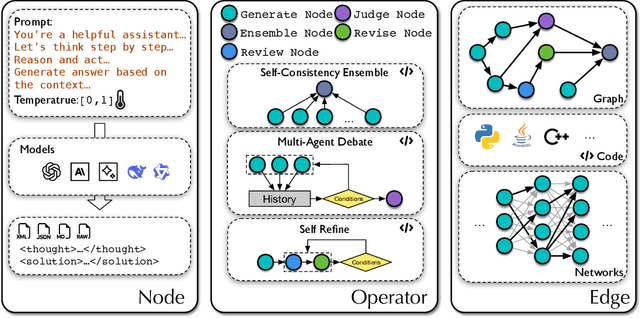
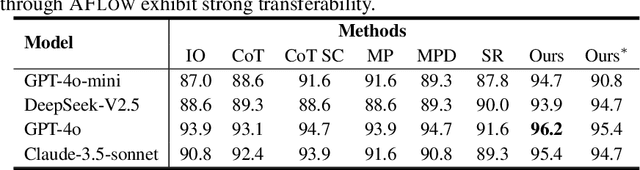
Large language models (LLMs) have demonstrated remarkable potential in solving complex tasks across diverse domains, typically by employing agentic workflows that follow detailed instructions and operational sequences. However, constructing these workflows requires significant human effort, limiting scalability and generalizability. Recent research has sought to automate the generation and optimization of these workflows, but existing methods still rely on initial manual setup and fall short of achieving fully automated and effective workflow generation. To address this challenge, we reformulate workflow optimization as a search problem over code-represented workflows, where LLM-invoking nodes are connected by edges. We introduce AFlow, an automated framework that efficiently explores this space using Monte Carlo Tree Search, iteratively refining workflows through code modification, tree-structured experience, and execution feedback. Empirical evaluations across six benchmark datasets demonstrate AFlow's efficacy, yielding a 5.7% average improvement over state-of-the-art baselines. Furthermore, AFlow enables smaller models to outperform GPT-4o on specific tasks at 4.55% of its inference cost in dollars. The code will be available at https://github.com/geekan/MetaGPT.
PersonaMath: Enhancing Math Reasoning through Persona-Driven Data Augmentation
Oct 02, 2024


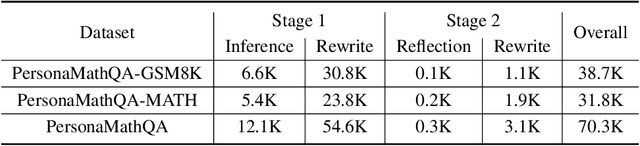
While closed-source Large Language Models (LLMs) demonstrate strong mathematical problem-solving abilities, open-source models continue to struggle with such tasks. To bridge this gap, we propose a data augmentation approach and introduce PersonaMathQA, a dataset derived from MATH and GSM8K, on which we train the PersonaMath models. Our approach consists of two stages: the first stage is learning from Persona Diversification, and the second stage is learning from Reflection. In the first stage, we regenerate detailed chain-of-thought (CoT) solutions as instructions using a closed-source LLM and introduce a novel persona-driven data augmentation technique to enhance the dataset's quantity and diversity. In the second stage, we incorporate reflection to fully leverage more challenging and valuable questions. Evaluation of our PersonaMath models on MATH and GSM8K reveals that the PersonaMath-7B model (based on LLaMA-2-7B) achieves an accuracy of 24.2% on MATH and 68.7% on GSM8K, surpassing all baseline methods and achieving state-of-the-art performance. Notably, our dataset contains only 70.3K data points-merely 17.8% of MetaMathQA and 27% of MathInstruct-yet our model outperforms these baselines, demonstrating the high quality and diversity of our dataset, which enables more efficient model training. We open-source the PersonaMathQA dataset, PersonaMath models, and our code for public usage.
ChipExpert: The Open-Source Integrated-Circuit-Design-Specific Large Language Model
Jul 26, 2024The field of integrated circuit (IC) design is highly specialized, presenting significant barriers to entry and research and development challenges. Although large language models (LLMs) have achieved remarkable success in various domains, existing LLMs often fail to meet the specific needs of students, engineers, and researchers. Consequently, the potential of LLMs in the IC design domain remains largely unexplored. To address these issues, we introduce ChipExpert, the first open-source, instructional LLM specifically tailored for the IC design field. ChipExpert is trained on one of the current best open-source base model (Llama-3 8B). The entire training process encompasses several key stages, including data preparation, continue pre-training, instruction-guided supervised fine-tuning, preference alignment, and evaluation. In the data preparation stage, we construct multiple high-quality custom datasets through manual selection and data synthesis techniques. In the subsequent two stages, ChipExpert acquires a vast amount of IC design knowledge and learns how to respond to user queries professionally. ChipExpert also undergoes an alignment phase, using Direct Preference Optimization, to achieve a high standard of ethical performance. Finally, to mitigate the hallucinations of ChipExpert, we have developed a Retrieval-Augmented Generation (RAG) system, based on the IC design knowledge base. We also released the first IC design benchmark ChipICD-Bench, to evaluate the capabilities of LLMs across multiple IC design sub-domains. Through comprehensive experiments conducted on this benchmark, ChipExpert demonstrated a high level of expertise in IC design knowledge Question-and-Answer tasks.