 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLOT: Enhancing Preference Learning via Optimal Transport
Apr 02, 2026Preference learning in Large Language Models (LLMs) has advanced significantly, yet existing methods remain limited by modest performance gains, high computational costs, hyperparameter sensitivity, and insufficient modeling of global token-level relationships. We introduce PLOT, which enhances Preference Learning in fine-tuning-based alignment through a token-level loss derived from Optimal Transport. By formulating preference learning as an Optimal Transport Problem, PLOT aligns model outputs with human preferences while preserving the original distribution of LLMs, ensuring stability and robustness. Furthermore, PLOT leverages token embeddings to capture semantic relationships, enabling globally informed optimization. Experiments across two preference categories - Human Values and Logic & Problem Solving - spanning seven subpreferences demonstrate that PLOT consistently improves alignment performance while maintaining fluency and coherence. These results substantiate optimal transport as a principled methodology for preference learning, establishing a theoretically grounded framework that provides new insights for preference learning of LLMs.
DEFT: Distribution-guided Efficient Fine-Tuning for Human Alignment
Apr 02, 2026Reinforcement Learning from Human Feedback (RLHF), using algorithms like Proximal Policy Optimization (PPO), aligns Large Language Models (LLMs) with human values but is costly and unstable. Alternatives have been proposed to replace PPO or integrate Supervised Fine-Tuning (SFT) and contrastive learning for direct fine-tuning and value alignment. However, these methods still require voluminous data to learn preferences and may weaken the generalization ability of LLMs. To further enhance alignment efficiency and performance while mitigating the loss of generalization ability, this paper introduces Distribution-guided Efficient Fine-Tuning (DEFT), an efficient alignment framework incorporating data filtering and distributional guidance by calculating the differential distribution reward based on the output distribution of language model and the discrepancy distribution of preference data. A small yet high-quality subset is filtered from the raw data using a differential distribution reward, which is then incorporated into existing alignment methods to guide the model's output distribution. Experimental results demonstrate that the methods enhanced by DEFT outperform the original methods in both alignment capability and generalization ability, with significantly reduced training time.
From Guessing to Placeholding: A Cost-Theoretic Framework for Uncertainty-Aware Code Completion
Apr 02, 2026While Large Language Models (LLMs) have demonstrated exceptional proficiency in code completion, they typically adhere to a Hard Completion (HC) paradigm, compelling the generation of fully concrete code even amidst insufficient context. Our analysis of 3 million real-world interactions exposes the limitations of this strategy: 61% of the generated suggestions were either edited after acceptance or rejected despite exhibiting over 80% similarity to the user's subsequent code, suggesting that models frequently make erroneous predictions at specific token positions. Motivated by this observation, we propose Adaptive Placeholder Completion (APC), a collaborative framework that extends HC by strategically outputting explicit placeholders at high-entropy positions, allowing users to fill directly via IDE navigation. Theoretically, we formulate code completion as a cost-minimization problem under uncertainty. Premised on the observation that filling placeholders incurs lower cost than correcting errors, we prove the existence of a critical entropy threshold above which APC achieves strictly lower expected cost than HC. We instantiate this framework by constructing training data from filtered real-world edit logs and design a cost-based reward function for reinforcement learning. Extensive evaluations across 1.5B--14B parameter models demonstrate that APC reduces expected editing costs from 19% to 50% while preserving standard HC performance. Our work provides both a theoretical foundation and a practical training framework for uncertainty-aware code completion, demonstrating that adaptive abstention can be learned end-to-end without sacrificing conventional completion quality.
Omni-Manip: Beyond-FOV Large-Workspace Humanoid Manipulation with Omnidirectional 3D Perception
Mar 05, 2026The deployment of humanoid robots for dexterous manipulation in unstructured environments remains challenging due to perceptual limitations that constrain the effective workspace. In scenarios where physical constraints prevent the robot from repositioning itself, maintaining omnidirectional awareness becomes far more critical than color or semantic information. While recent advances in visuomotor policy learning have improved manipulation capabilities, conventional RGB-D solutions suffer from narrow fields of view (FOV) and self-occlusion, requiring frequent base movements that introduce motion uncertainty and safety risks. Existing approaches to expanding perception, including active vision systems and third-view cameras, introduce mechanical complexity, calibration dependencies, and latency that hinder reliable real-time performance. In this work, We propose Omni-Manip, an end-to-end LiDAR-driven 3D visuomotor policy that enables robust manipulation in large workspaces. Our method processes panoramic point clouds through a Time-Aware Attention Pooling mechanism, efficiently encoding sparse 3D data while capturing temporal dependencies. This 360° perception allows the robot to interact with objects across wide areas without frequent repositioning. To support policy learning, we develop a whole-body teleoperation system for efficient data collection on full-body coordination. Extensive experiments in simulation and real-world environments show that Omni-Manip achieves robust performance in large-workspace and cluttered scenarios, outperforming baselines that rely on egocentric depth cameras.
ChARM: Character-based Act-adaptive Reward Modeling for Advanced Role-Playing Language Agents
May 29, 2025
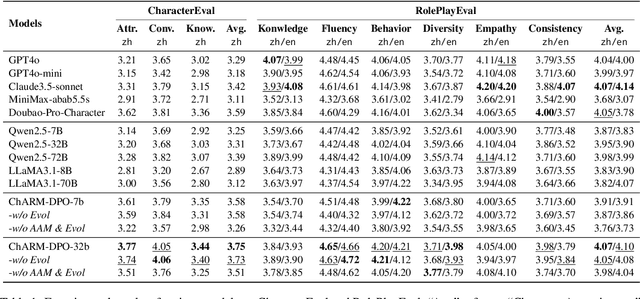
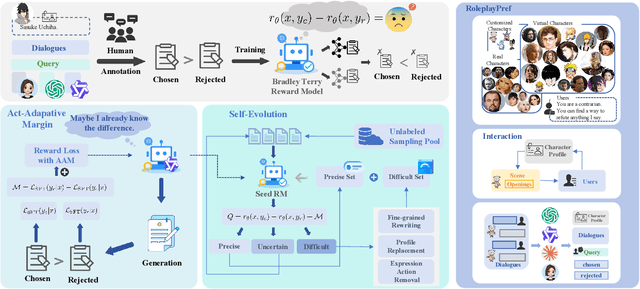
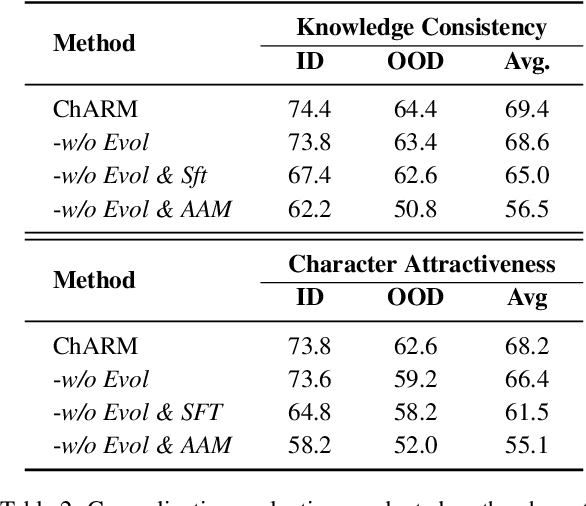
Role-Playing Language Agents (RPLAs) aim to simulate characters for realistic and engaging human-computer interactions. However, traditional reward models often struggle with scalability and adapting to subjective conversational preferences. We propose ChARM, a Character-based Act-adaptive Reward Model, addressing these challenges through two innovations: (1) an act-adaptive margin that significantly enhances learning efficiency and generalizability, and (2) a self-evolution mechanism leveraging large-scale unlabeled data to improve training coverage. Additionally, we introduce RoleplayPref, the first large-scale preference dataset specifically for RPLAs, featuring 1,108 characters, 13 subcategories, and 16,888 bilingual dialogues, alongside RoleplayEval, a dedicated evaluation benchmark. Experimental results show a 13% improvement over the conventional Bradley-Terry model in preference rankings. Furthermore, applying ChARM-generated rewards to preference learning techniques (e.g., direct preference optimization) achieves state-of-the-art results on CharacterEval and RoleplayEval. Code and dataset are available at https://github.com/calubkk/ChARM.
UTSRMorph: A Unified Transformer and Superresolution Network for Unsupervised Medical Image Registration
Oct 27, 2024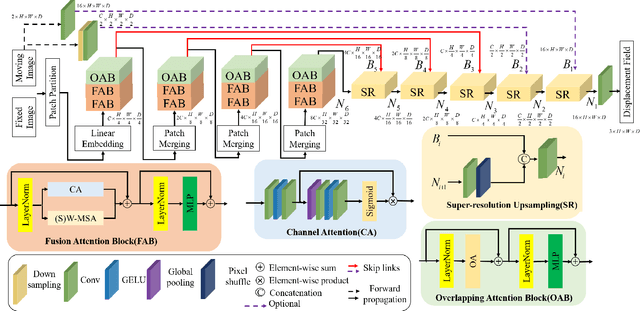
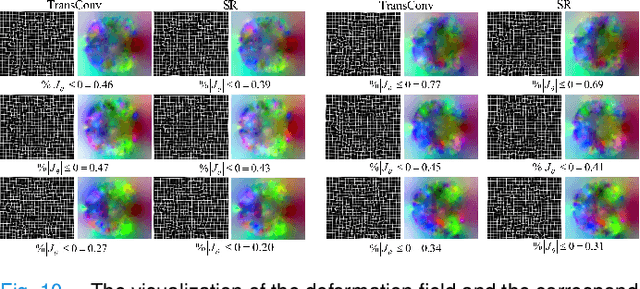

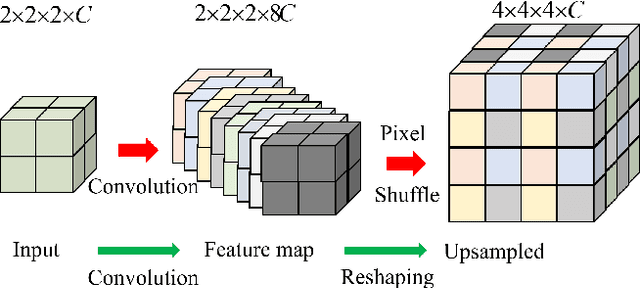
Complicated image registration is a key issue in medical image analysis, and deep learning-based methods have achieved better results than traditional methods. The methods include ConvNet-based and Transformer-based methods. Although ConvNets can effectively utilize local information to reduce redundancy via small neighborhood convolution, the limited receptive field results in the inability to capture global dependencies. Transformers can establish long-distance dependencies via a self-attention mechanism; however, the intense calculation of the relationships among all tokens leads to high redundancy. We propose a novel unsupervised image registration method named the unified Transformer and superresolution (UTSRMorph) network, which can enhance feature representation learning in the encoder and generate detailed displacement fields in the decoder to overcome these problems. We first propose a fusion attention block to integrate the advantages of ConvNets and Transformers, which inserts a ConvNet-based channel attention module into a multihead self-attention module. The overlapping attention block, a novel cross-attention method, uses overlapping windows to obtain abundant correlations with match information of a pair of images. Then, the blocks are flexibly stacked into a new powerful encoder. The decoder generation process of a high-resolution deformation displacement field from low-resolution features is considered as a superresolution process. Specifically, the superresolution module was employed to replace interpolation upsampling, which can overcome feature degradation. UTSRMorph was compared to state-of-the-art registration methods in the 3D brain MR (OASIS, IXI) and MR-CT datasets. The qualitative and quantitative results indicate that UTSRMorph achieves relatively better performance. The code and datasets are publicly available at https://github.com/Runshi-Zhang/UTSRMorph.
* 13pages,10 figures
PersonaMath: Enhancing Math Reasoning through Persona-Driven Data Augmentation
Oct 02, 2024


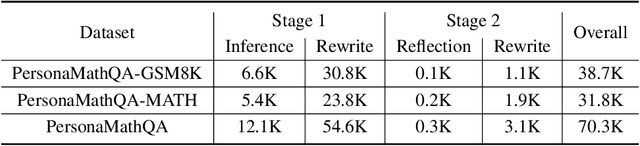
While closed-source Large Language Models (LLMs) demonstrate strong mathematical problem-solving abilities, open-source models continue to struggle with such tasks. To bridge this gap, we propose a data augmentation approach and introduce PersonaMathQA, a dataset derived from MATH and GSM8K, on which we train the PersonaMath models. Our approach consists of two stages: the first stage is learning from Persona Diversification, and the second stage is learning from Reflection. In the first stage, we regenerate detailed chain-of-thought (CoT) solutions as instructions using a closed-source LLM and introduce a novel persona-driven data augmentation technique to enhance the dataset's quantity and diversity. In the second stage, we incorporate reflection to fully leverage more challenging and valuable questions. Evaluation of our PersonaMath models on MATH and GSM8K reveals that the PersonaMath-7B model (based on LLaMA-2-7B) achieves an accuracy of 24.2% on MATH and 68.7% on GSM8K, surpassing all baseline methods and achieving state-of-the-art performance. Notably, our dataset contains only 70.3K data points-merely 17.8% of MetaMathQA and 27% of MathInstruct-yet our model outperforms these baselines, demonstrating the high quality and diversity of our dataset, which enables more efficient model training. We open-source the PersonaMathQA dataset, PersonaMath models, and our code for public usage.
DeliLaw: A Chinese Legal Counselling System Based on a Large Language Model
Aug 01, 2024

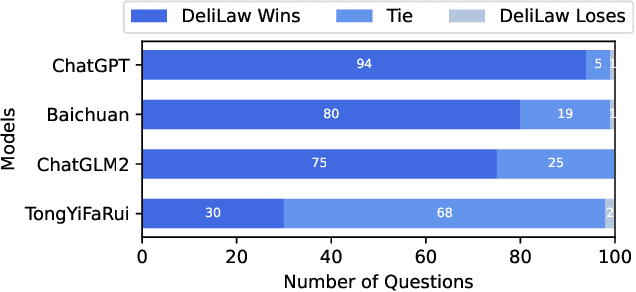
Traditional legal retrieval systems designed to retrieve legal documents, statutes, precedents, and other legal information are unable to give satisfactory answers due to lack of semantic understanding of specific questions. Large Language Models (LLMs) have achieved excellent results in a variety of natural language processing tasks, which inspired us that we train a LLM in the legal domain to help legal retrieval. However, in the Chinese legal domain, due to the complexity of legal questions and the rigour of legal articles, there is no legal large model with satisfactory practical application yet. In this paper, we present DeliLaw, a Chinese legal counselling system based on a large language model. DeliLaw integrates a legal retrieval module and a case retrieval module to overcome the model hallucination. Users can consult professional legal questions, search for legal articles and relevant judgement cases, etc. on the DeliLaw system in a dialogue mode. In addition, DeliLaw supports the use of English for counseling. we provide the address of the system: https://data.delilegal.com/lawQuestion.
CLHA: A Simple yet Effective Contrastive Learning Framework for Human Alignment
Mar 26, 2024Reinforcement learning from human feedback (RLHF) is a crucial technique in aligning large language models (LLMs) with human preferences, ensuring these LLMs behave in beneficial and comprehensible ways to users. However, a longstanding challenge in human alignment techniques based on reinforcement learning lies in their inherent complexity and difficulty in training. To address this challenge, we present a simple yet effective Contrastive Learning Framework for Human Alignment (CLHA) to align LLMs with human preferences directly. CLHA employs a novel rescoring strategy to evaluate the noise within the data by considering its inherent quality and dynamically adjusting the training process. Simultaneously, CLHA utilizes pairwise contrastive loss and adaptive supervised fine-tuning loss to adaptively modify the likelihood of generating responses, ensuring enhanced alignment with human preferences. Using advanced methods, CLHA surpasses other algorithms, showcasing superior performance in terms of reward model scores, automatic evaluations, and human assessments on the widely used ``Helpful and Harmless'' dataset.
Less Can Be More: Unsupervised Graph Pruning for Large-scale Dynamic Graphs
May 18, 2023


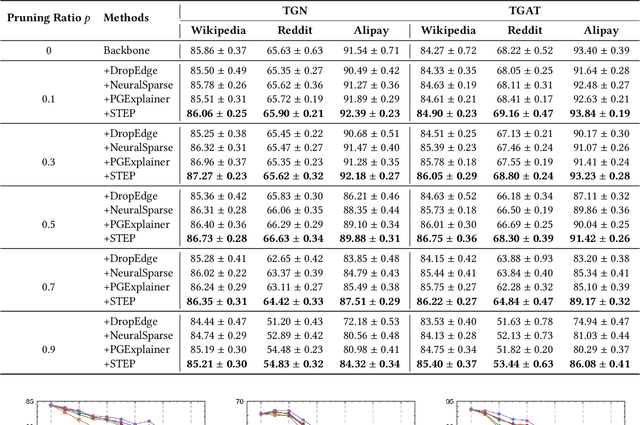
The prevalence of large-scale graphs poses great challenges in time and storage for training and deploying graph neural networks (GNNs). Several recent works have explored solutions for pruning the large original graph into a small and highly-informative one, such that training and inference on the pruned and large graphs have comparable performance. Although empirically effective, current researches focus on static or non-temporal graphs, which are not directly applicable to dynamic scenarios. In addition, they require labels as ground truth to learn the informative structure, limiting their applicability to new problem domains where labels are hard to obtain. To solve the dilemma, we propose and study the problem of unsupervised graph pruning on dynamic graphs. We approach the problem by our proposed STEP, a self-supervised temporal pruning framework that learns to remove potentially redundant edges from input dynamic graphs. From a technical and industrial viewpoint, our method overcomes the trade-offs between the performance and the time & memory overheads. Our results on three real-world datasets demonstrate the advantages on improving the efficacy, robustness, and efficiency of GNNs on dynamic node classification tasks. Most notably, STEP is able to prune more than 50% of edges on a million-scale industrial graph Alipay (7M nodes, 21M edges) while approximating up to 98% of the original performance. Code is available at https://github.com/EdisonLeeeee/STEP.