 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study on Individual Spatiotemporal Activity Generation Method Using MCP-Enhanced Chain-of-Thought Large Language Models
Jun 12, 2025Human spatiotemporal behavior simulation is critical for urban planning research, yet traditional rule-based and statistical approaches suffer from high computational costs, limited generalizability, and poor scalability. While large language models (LLMs) show promise as "world simulators," they face challenges in spatiotemporal reasoning including limited spatial cognition, lack of physical constraint understanding, and group homogenization tendencies. This paper introduces a framework integrating chain-of-thought (CoT) reasoning with Model Context Protocol (MCP) to enhance LLMs' capability in simulating spatiotemporal behaviors that correspond with validation data patterns. The methodology combines human-like progressive reasoning through a five-stage cognitive framework with comprehensive data processing via six specialized MCP tool categories: temporal management, spatial navigation, environmental perception, personal memory, social collaboration, and experience evaluation. Experiments in Shanghai's Lujiazui district validate the framework's effectiveness across 1,000 generated samples. Results demonstrate high similarity with real mobile signaling data, achieving generation quality scores of 7.86 to 8.36 across different base models. Parallel processing experiments show efficiency improvements, with generation times decreasing from 1.30 to 0.17 minutes per sample when scaling from 2 to 12 processes. This work contributes to integrating CoT reasoning with MCP for urban behavior modeling, advancing LLMs applications in urban computing and providing a practical approach for synthetic mobility data generation. The framework offers a foundation for smart city planning, transportation forecasting, and participatory urban design applications.
The Super Weight in Large Language Models
Nov 11, 2024
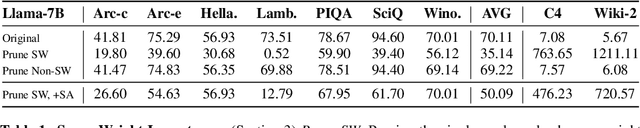
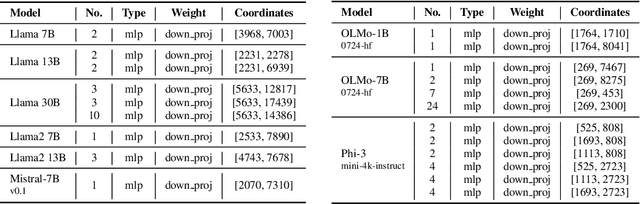

Recent works have shown a surprising result: a small fraction of Large Language Model (LLM) parameter outliers are disproportionately important to the quality of the model. LLMs contain billions of parameters, so these small fractions, such as 0.01%, translate to hundreds of thousands of parameters. In this work, we present an even more surprising finding: Pruning as few as a single parameter can destroy an LLM's ability to generate text -- increasing perplexity by 3 orders of magnitude and reducing zero-shot accuracy to guessing. We propose a data-free method for identifying such parameters, termed super weights, using a single forward pass through the model. We additionally find that these super weights induce correspondingly rare and large activation outliers, termed super activations. When preserved with high precision, super activations can improve simple round-to-nearest quantization to become competitive with state-of-the-art methods. For weight quantization, we similarly find that by preserving the super weight and clipping other weight outliers, round-to-nearest quantization can scale to much larger block sizes than previously considered. To facilitate further research into super weights, we provide an index of super weight coordinates for common, openly available LLMs.
On Inductive Biases That Enable Generalization of Diffusion Transformers
Oct 28, 2024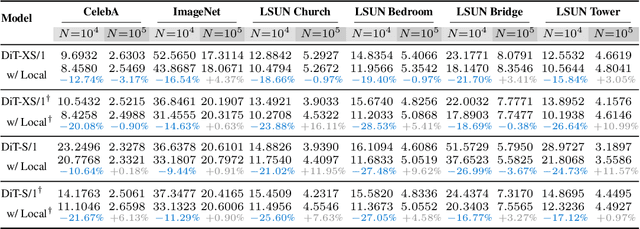
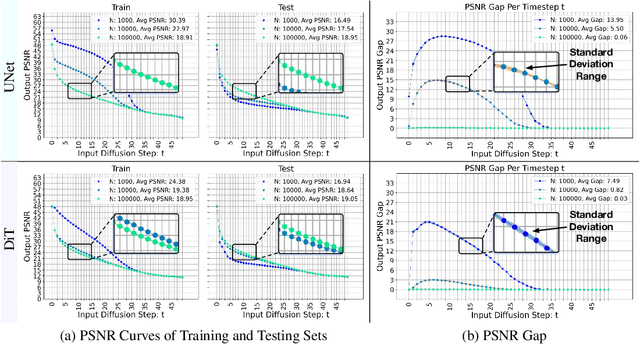
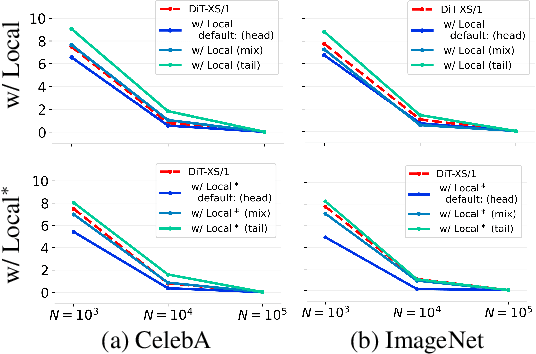
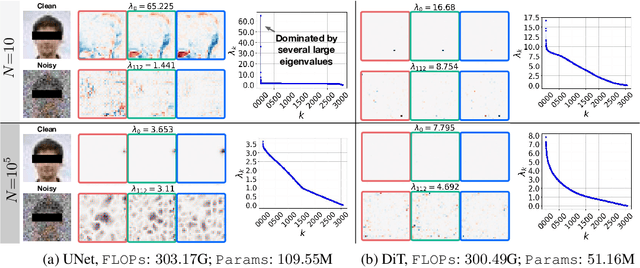
Recent work studying the generalization of diffusion models with UNet-based denoisers reveals inductive biases that can be expressed via geometry-adaptive harmonic bases. However, in practice, more recent denoising networks are often based on transformers, e.g., the diffusion transformer (DiT). This raises the question: do transformer-based denoising networks exhibit inductive biases that can also be expressed via geometry-adaptive harmonic bases? To our surprise, we find that this is not the case. This discrepancy motivates our search for the inductive bias that can lead to good generalization in DiT models. Investigating the pivotal attention modules of a DiT, we find that locality of attention maps are closely associated with generalization. To verify this finding, we modify the generalization of a DiT by restricting its attention windows. We inject local attention windows to a DiT and observe an improvement in generalization. Furthermore, we empirically find that both the placement and the effective attention size of these local attention windows are crucial factors. Experimental results on the CelebA, ImageNet, and LSUN datasets show that strengthening the inductive bias of a DiT can improve both generalization and generation quality when less training data is available. Source code will be released publicly upon paper publication. Project page: dit-generalization.github.io/.
Towards in-store multi-person tracking using head detection and track heatmaps
May 16, 2020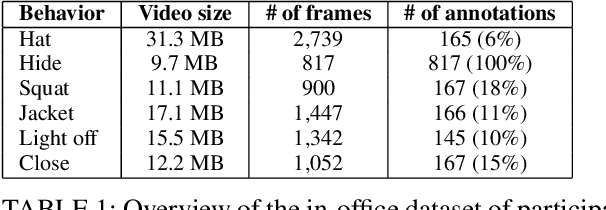

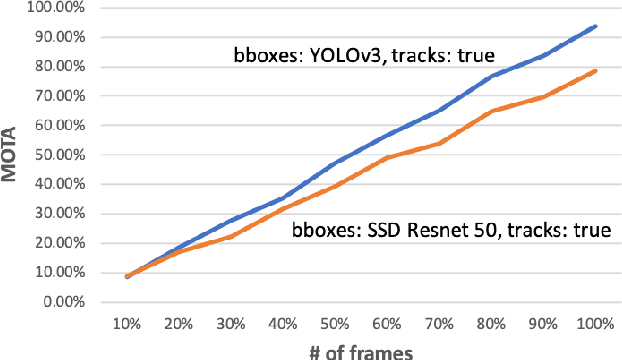
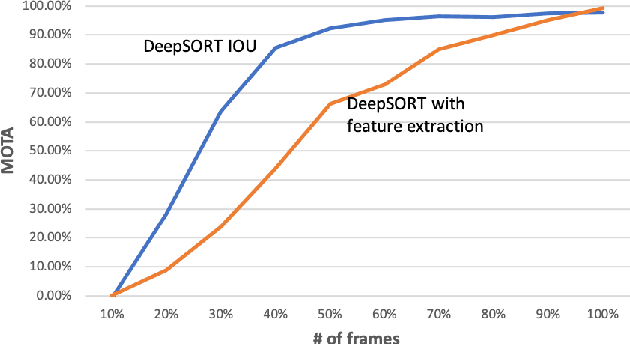
Computer vision algorithms are being implemented across a breadth of industries to enable technological innovations. In this paper, we study the problem of computer vision based customer tracking in retail industry. To this end, we introduce a dataset collected from a camera in an office environment where participants mimic various behaviors of customers in a supermarket. In addition, we describe an illustrative example of the use of this dataset for tracking participants based on a head tracking model in an effort to minimize errors due to occlusion. Furthermore, we propose a model for recognizing customers and staff based on their movement patterns. The model is evaluated using a real-world dataset collected in a supermarket over a 24-hour period that achieves 98\% accuracy during training and 93\% accuracy during evaluation.
Argoverse: 3D Tracking and Forecasting with Rich Maps
Nov 06, 2019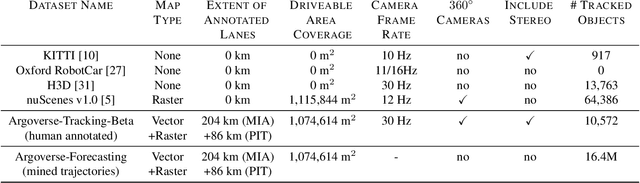

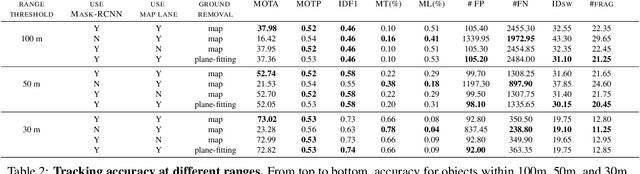
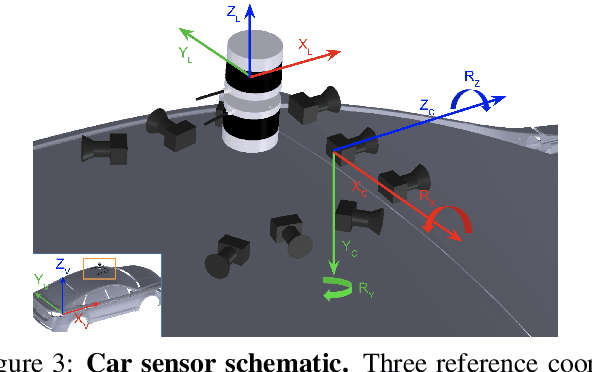
We present Argoverse -- two datasets designed to support autonomous vehicle machine learning tasks such as 3D tracking and motion forecasting. Argoverse was collected by a fleet of autonomous vehicles in Pittsburgh and Miami. The Argoverse 3D Tracking dataset includes 360 degree images from 7 cameras with overlapping fields of view, 3D point clouds from long range LiDAR, 6-DOF pose, and 3D track annotations. Notably, it is the only modern AV dataset that provides forward-facing stereo imagery. The Argoverse Motion Forecasting dataset includes more than 300,000 5-second tracked scenarios with a particular vehicle identified for trajectory forecasting. Argoverse is the first autonomous vehicle dataset to include "HD maps" with 290 km of mapped lanes with geometric and semantic metadata. All data is released under a Creative Commons license at www.argoverse.org. In our baseline experiments, we illustrate how detailed map information such as lane direction, driveable area, and ground height improves the accuracy of 3D object tracking and motion forecasting. Our tracking and forecasting experiments represent only an initial exploration of the use of rich maps in robotic perception. We hope that Argoverse will enable the research community to explore these problems in greater depth.
Inexact Proximal Gradient Methods for Non-convex and Non-smooth Optimization
Sep 08, 2018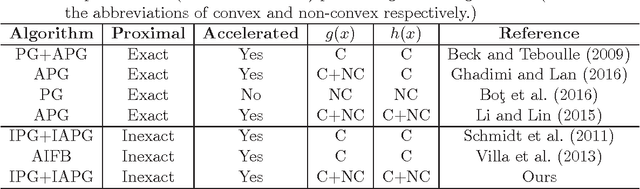
In machine learning research, the proximal gradient methods are popular for solving various optimization problems with non-smooth regularization. Inexact proximal gradient methods are extremely important when exactly solving the proximal operator is time-consuming, or the proximal operator does not have an analytic solution. However, existing inexact proximal gradient methods only consider convex problems. The knowledge of inexact proximal gradient methods in the non-convex setting is very limited. % Moreover, for some machine learning models, there is still no proposed solver for exactly solving the proximal operator. To address this challenge, in this paper, we first propose three inexact proximal gradient algorithms, including the basic version and Nesterov's accelerated version. After that, we provide the theoretical analysis to the basic and Nesterov's accelerated versions. The theoretical results show that our inexact proximal gradient algorithms can have the same convergence rates as the ones of exact proximal gradient algorithms in the non-convex setting. Finally, we show the applications of our inexact proximal gradient algorithms on three representative non-convex learning problems. All experimental results confirm the superiority of our new inexact proximal gradient algorithms.
Scalable and accurate deep learning for electronic health records
May 11, 2018
Predictive modeling with electronic health record (EHR) data is anticipated to drive personalized medicine and improve healthcare quality. Constructing predictive statistical models typically requires extraction of curated predictor variables from normalized EHR data, a labor-intensive process that discards the vast majority of information in each patient's record. We propose a representation of patients' entire, raw EHR records based on the Fast Healthcare Interoperability Resources (FHIR) format. We demonstrate that deep learning methods using this representation are capable of accurately predicting multiple medical events from multiple centers without site-specific data harmonization. We validated our approach using de-identified EHR data from two U.S. academic medical centers with 216,221 adult patients hospitalized for at least 24 hours. In the sequential format we propose, this volume of EHR data unrolled into a total of 46,864,534,945 data points, including clinical notes. Deep learning models achieved high accuracy for tasks such as predicting in-hospital mortality (AUROC across sites 0.93-0.94), 30-day unplanned readmission (AUROC 0.75-0.76), prolonged length of stay (AUROC 0.85-0.86), and all of a patient's final discharge diagnoses (frequency-weighted AUROC 0.90). These models outperformed state-of-the-art traditional predictive models in all cases. We also present a case-study of a neural-network attribution system, which illustrates how clinicians can gain some transparency into the predictions. We believe that this approach can be used to create accurate and scalable predictions for a variety of clinical scenarios, complete with explanations that directly highlight evidence in the patient's chart.
* Published version from https://www.nature.com/articles/s41746-018-0029-1