 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Speech Recognition for African American English With Audio Classification
Sep 16, 2023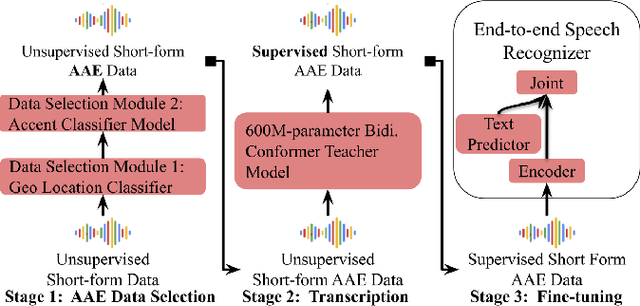
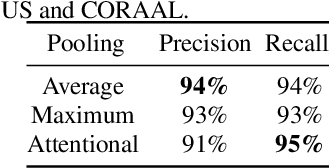
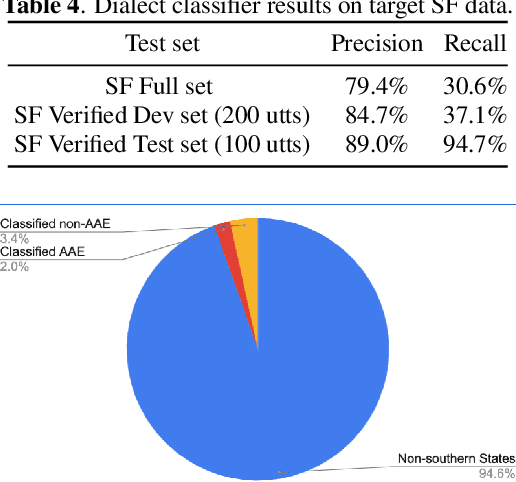

Automatic speech recognition (ASR) systems have been shown to have large quality disparities between the language varieties they are intended or expected to recognize. One way to mitigate this is to train or fine-tune models with more representative datasets. But this approach can be hindered by limited in-domain data for training and evaluation. We propose a new way to improve the robustness of a US English short-form speech recognizer using a small amount of out-of-domain (long-form) African American English (AAE) data. We use CORAAL, YouTube and Mozilla Common Voice to train an audio classifier to approximately output whether an utterance is AAE or some other variety including Mainstream American English (MAE). By combining the classifier output with coarse geographic information, we can select a subset of utterances from a large corpus of untranscribed short-form queries for semi-supervised learning at scale. Fine-tuning on this data results in a 38.5% relative word error rate disparity reduction between AAE and MAE without reducing MAE quality.
Efficient Domain Adaptation for Speech Foundation Models
Feb 03, 2023

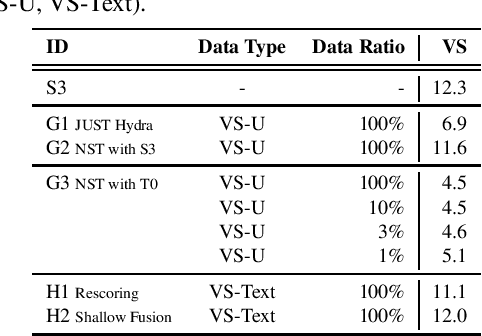

Foundation models (FMs), that are trained on broad data at scale and are adaptable to a wide range of downstream tasks, have brought large interest in the research community. Benefiting from the diverse data sources such as different modalities, languages and application domains, foundation models have demonstrated strong generalization and knowledge transfer capabilities. In this paper, we present a pioneering study towards building an efficient solution for FM-based speech recognition systems. We adopt the recently developed self-supervised BEST-RQ for pretraining, and propose the joint finetuning with both source and unsupervised target domain data using JUST Hydra. The FM encoder adapter and decoder are then finetuned to the target domain with a small amount of supervised in-domain data. On a large-scale YouTube and Voice Search task, our method is shown to be both data and model parameter efficient. It achieves the same quality with only 21.6M supervised in-domain data and 130.8M finetuned parameters, compared to the 731.1M model trained from scratch on additional 300M supervised in-domain data.
Resource-Efficient Transfer Learning From Speech Foundation Model Using Hierarchical Feature Fusion
Nov 04, 2022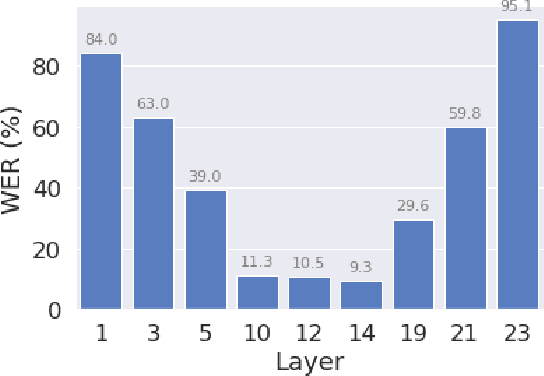
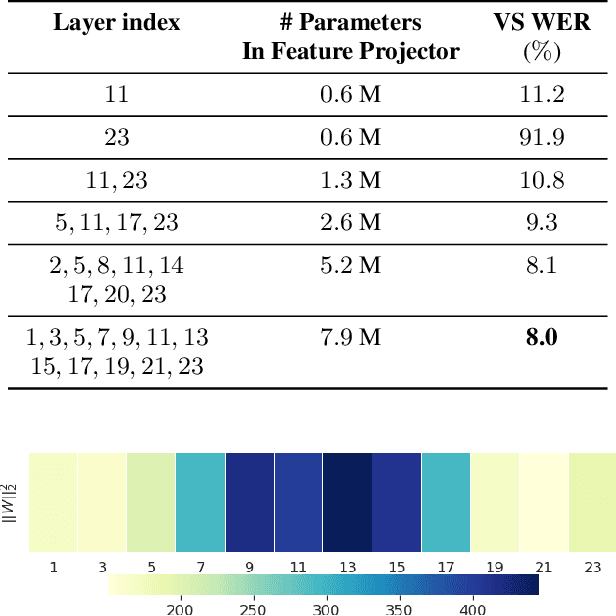
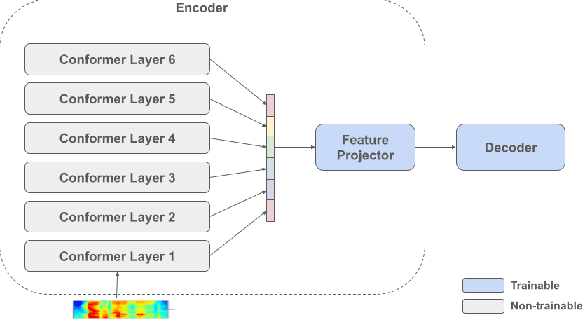
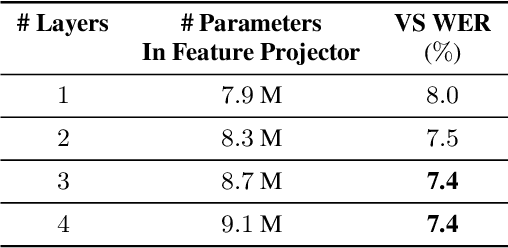
Self-supervised pre-training of a speech foundation model, followed by supervised fine-tuning, has shown impressive quality improvements on automatic speech recognition (ASR) tasks. Fine-tuning separate foundation models for many downstream tasks are expensive since the foundation model is usually very big. Parameter-efficient fine-tuning methods (e.g. adapter, sparse update methods) offer an alternative paradigm where a small set of parameters are updated to adapt the foundation model to new tasks. However, these methods still suffer from a high computational memory cost and slow training speed because they require backpropagation through the entire neural network at each step. In the paper, we analyze the performance of features at different layers of a foundation model on the speech recognition task and propose a novel hierarchical feature fusion method for resource-efficient transfer learning from speech foundation models. Experimental results show that the proposed method can achieve better performance on speech recognition task than existing algorithms with fewer number of trainable parameters, less computational memory cost and faster training speed. After combining with Adapters at all layers, the proposed method can achieve the same performance as fine-tuning the whole model with $97\%$ fewer trainable encoder parameters and $53\%$ faster training speed.
JOIST: A Joint Speech and Text Streaming Model For ASR
Oct 13, 2022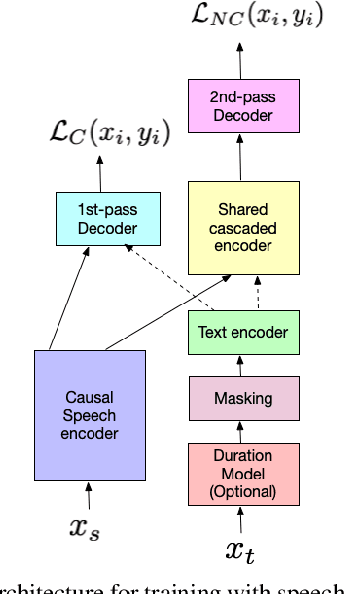

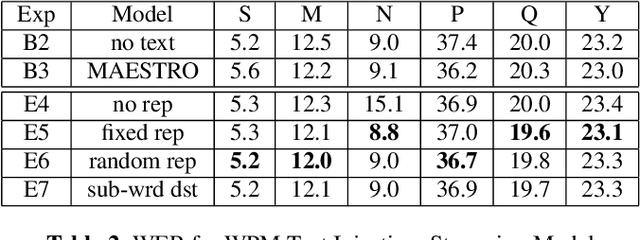

We present JOIST, an algorithm to train a streaming, cascaded, encoder end-to-end (E2E) model with both speech-text paired inputs, and text-only unpaired inputs. Unlike previous works, we explore joint training with both modalities, rather than pre-training and fine-tuning. In addition, we explore JOIST using a streaming E2E model with an order of magnitude more data, which are also novelties compared to previous works. Through a series of ablation studies, we explore different types of text modeling, including how to model the length of the text sequence and the appropriate text sub-word unit representation. We find that best text representation for JOIST improves WER across a variety of search and rare-word test sets by 4-14% relative, compared to a model not trained with text. In addition, we quantitatively show that JOIST maintains streaming capabilities, which is important for good user-level experience.
Pseudo Label Is Better Than Human Label
Mar 28, 2022


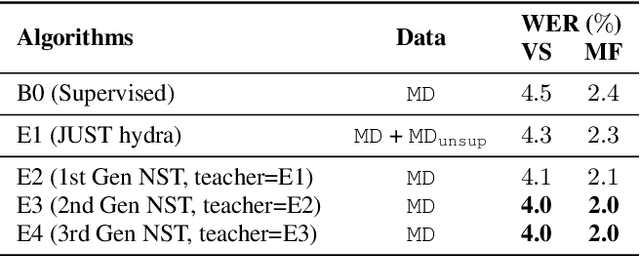
State-of-the-art automatic speech recognition (ASR) systems are trained with tens of thousands of hours of labeled speech data. Human transcription is expensive and time consuming. Factors such as the quality and consistency of the transcription can greatly affect the performance of the ASR models trained with these data. In this paper, we show that we can train a strong teacher model to produce high quality pseudo labels by utilizing recent self-supervised and semi-supervised learning techniques. Specifically, we use JUST (Joint Unsupervised/Supervised Training) and iterative noisy student teacher training to train a 600 million parameter bi-directional teacher model. This model achieved 4.0% word error rate (WER) on a voice search task, 11.1% relatively better than a baseline. We further show that by using this strong teacher model to generate high-quality pseudo labels for training, we can achieve 13.6% relative WER reduction (5.9% to 5.1%) for a streaming model compared to using human labels.
Large-scale ASR Domain Adaptation using Self- and Semi-supervised Learning
Oct 13, 2021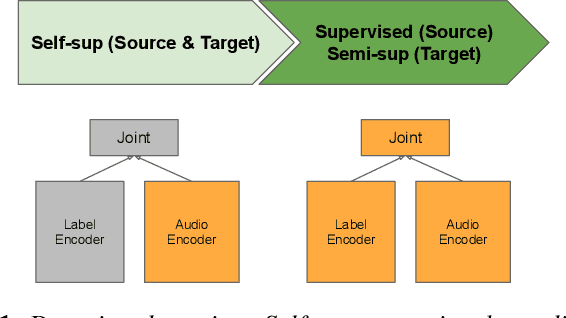

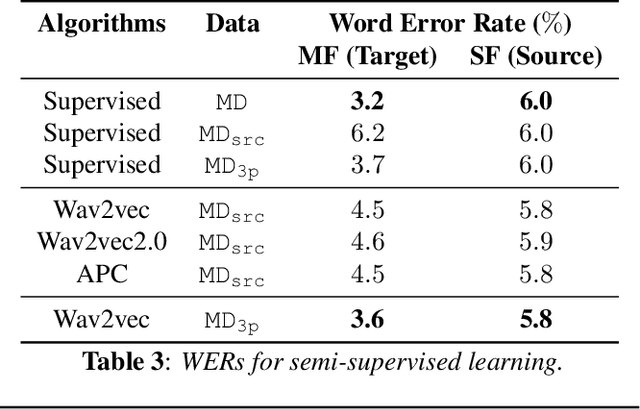
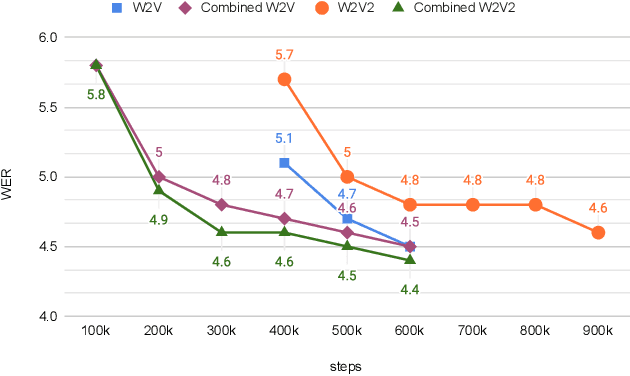
Self- and semi-supervised learning methods have been actively investigated to reduce labeled training data or enhance the model performance. However, the approach mostly focus on in-domain performance for public datasets. In this study, we utilize the combination of self- and semi-supervised learning methods to solve unseen domain adaptation problem in a large-scale production setting for online ASR model. This approach demonstrates that using the source domain data with a small fraction of the target domain data (3%) can recover the performance gap compared to a full data baseline: relative 13.5% WER improvement for target domain data.
Incremental Layer-wise Self-Supervised Learning for Efficient Speech Domain Adaptation On Device
Oct 01, 2021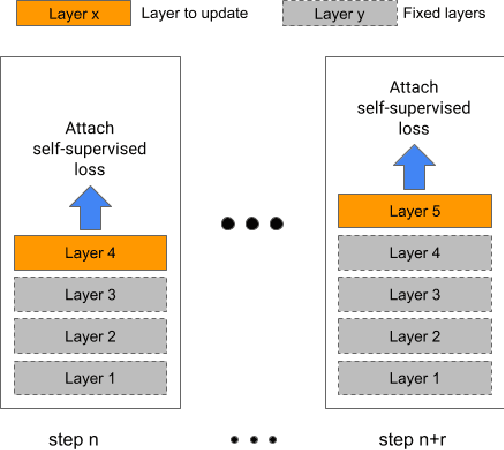
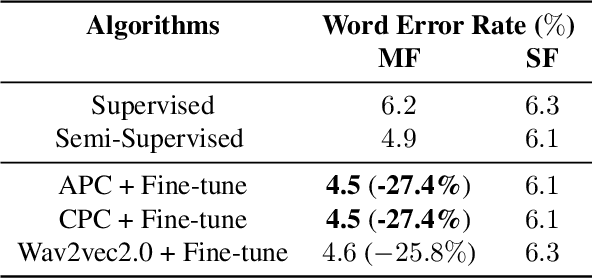
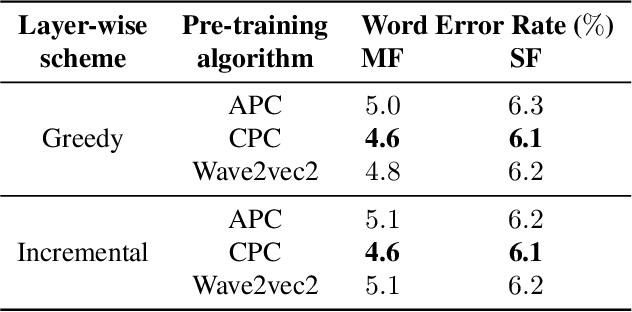
Streaming end-to-end speech recognition models have been widely applied to mobile devices and show significant improvement in efficiency. These models are typically trained on the server using transcribed speech data. However, the server data distribution can be very different from the data distribution on user devices, which could affect the model performance. There are two main challenges for on device training, limited reliable labels and limited training memory. While self-supervised learning algorithms can mitigate the mismatch between domains using unlabeled data, they are not applicable on mobile devices directly because of the memory constraint. In this paper, we propose an incremental layer-wise self-supervised learning algorithm for efficient speech domain adaptation on mobile devices, in which only one layer is updated at a time. Extensive experimental results demonstrate that the proposed algorithm obtains a Word Error Rate (WER) on the target domain $24.2\%$ better than supervised baseline and costs $89.7\%$ less training memory than the end-to-end self-supervised learning algorithm.
A Field Guide to Federated Optimization
Jul 14, 2021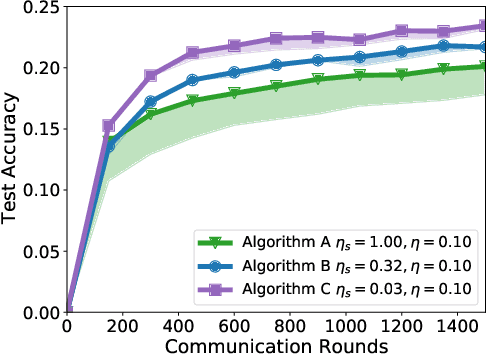


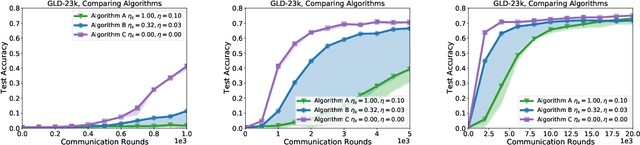
Federated learning and analytics are a distributed approach for collaboratively learning models (or statistics) from decentralized data, motivated by and designed for privacy protection. The distributed learning process can be formulated as solving federated optimization problems, which emphasize communication efficiency, data heterogeneity, compatibility with privacy and system requirements, and other constraints that are not primary considerations in other problem settings. This paper provides recommendations and guidelines on formulating, designing, evaluating and analyzing federated optimization algorithms through concrete examples and practical implementation, with a focus on conducting effective simulations to infer real-world performance. The goal of this work is not to survey the current literature, but to inspire researchers and practitioners to design federated learning algorithms that can be used in various practical applications.
On Large-Cohort Training for Federated Learning
Jun 15, 2021

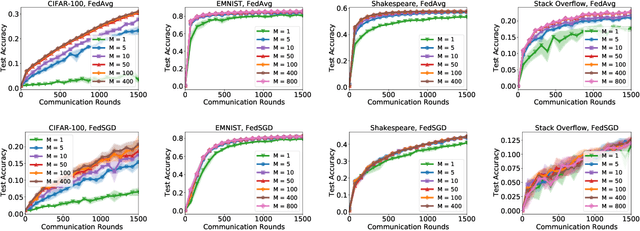
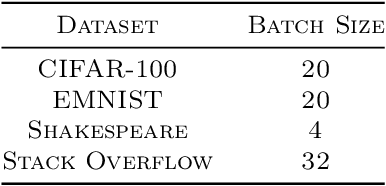
Federated learning methods typically learn a model by iteratively sampling updates from a population of clients. In this work, we explore how the number of clients sampled at each round (the cohort size) impacts the quality of the learned model and the training dynamics of federated learning algorithms. Our work poses three fundamental questions. First, what challenges arise when trying to scale federated learning to larger cohorts? Second, what parallels exist between cohort sizes in federated learning and batch sizes in centralized learning? Last, how can we design federated learning methods that effectively utilize larger cohort sizes? We give partial answers to these questions based on extensive empirical evaluation. Our work highlights a number of challenges stemming from the use of larger cohorts. While some of these (such as generalization issues and diminishing returns) are analogs of large-batch training challenges, others (including training failures and fairness concerns) are unique to federated learning.
Privacy-Preserving Asynchronous Federated Learning Algorithms for Multi-Party Vertically Collaborative Learning
Aug 14, 2020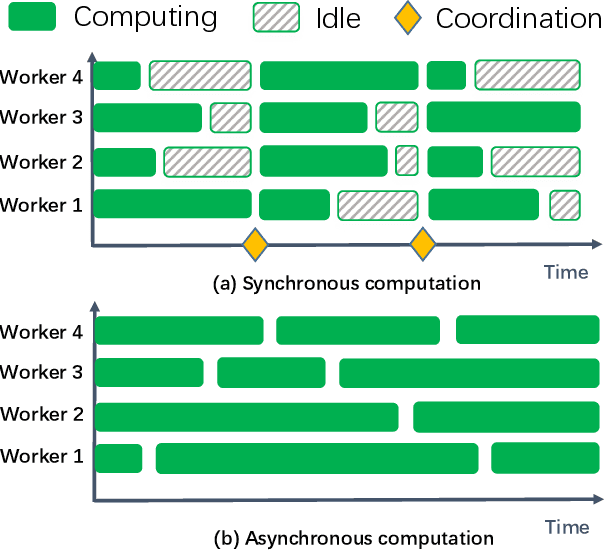

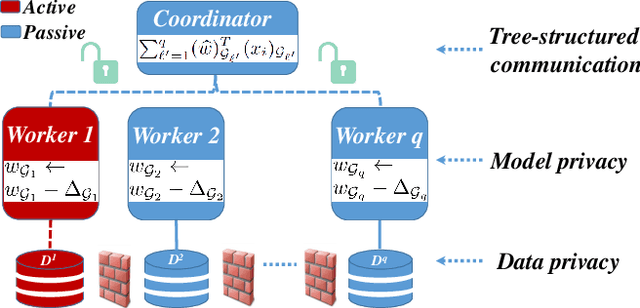
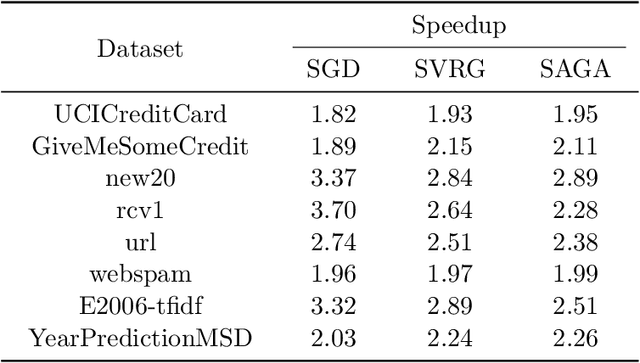
The privacy-preserving federated learning for vertically partitioned data has shown promising results as the solution of the emerging multi-party joint modeling application, in which the data holders (such as government branches, private finance and e-business companies) collaborate throughout the learning process rather than relying on a trusted third party to hold data. However, existing federated learning algorithms for vertically partitioned data are limited to synchronous computation. To improve the efficiency when the unbalanced computation/communication resources are common among the parties in the federated learning system, it is essential to develop asynchronous training algorithms for vertically partitioned data while keeping the data privacy. In this paper, we propose an asynchronous federated SGD (AFSGD-VP) algorithm and its SVRG and SAGA variants on the vertically partitioned data. Moreover, we provide the convergence analyses of AFSGD-VP and its SVRG and SAGA variants under the condition of strong convexity. We also discuss their model privacy, data privacy, computational complexities and communication costs. To the best of our knowledge, AFSGD-VP and its SVRG and SAGA variants are the first asynchronous federated learning algorithms for vertically partitioned data. Extensive experimental results on a variety of vertically partitioned datasets not only verify the theoretical results of AFSGD-VP and its SVRG and SAGA variants, but also show that our algorithms have much higher efficiency than the corresponding synchronous algorithms.