 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling Ambiguity in Emotion: From Out-of-Domain Detection to Distribution Estimation
Feb 20, 2024



The subjective perception of emotion leads to inconsistent labels from human annotators. Typically, utterances lacking majority-agreed labels are excluded when training an emotion classifier, which cause problems when encountering ambiguous emotional expressions during testing. This paper investigates three methods to handle ambiguous emotion. First, we show that incorporating utterances without majority-agreed labels as an additional class in the classifier reduces the classification performance of the other emotion classes. Then, we propose detecting utterances with ambiguous emotions as out-of-domain samples by quantifying the uncertainty in emotion classification using evidential deep learning. This approach retains the classification accuracy while effectively detects ambiguous emotion expressions. Furthermore, to obtain fine-grained distinctions among ambiguous emotions, we propose representing emotion as a distribution instead of a single class label. The task is thus re-framed from classification to distribution estimation where every individual annotation is taken into account, not just the majority opinion. The evidential uncertainty measure is extended to quantify the uncertainty in emotion distribution estimation. Experimental results on the IEMOCAP and CREMA-D datasets demonstrate the superior capability of the proposed method in terms of majority class prediction, emotion distribution estimation, and uncertainty estimation.
Efficient Adapter Finetuning for Tail Languages in Streaming Multilingual ASR
Jan 17, 2024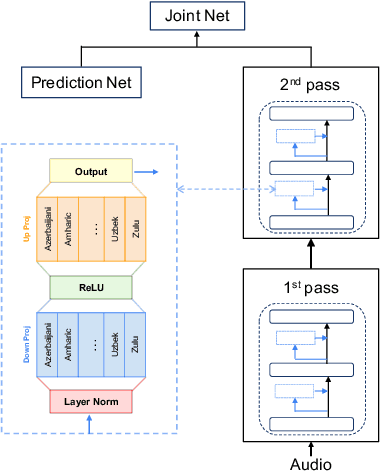

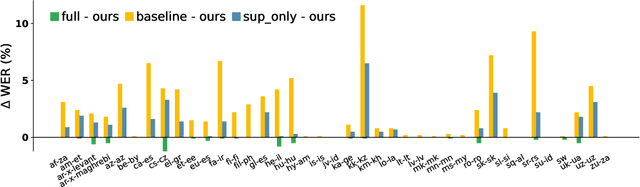
The end-to-end ASR model is often desired in the streaming multilingual scenario since it is easier to deploy and can benefit from pre-trained speech models such as powerful foundation models. Meanwhile, the heterogeneous nature and imbalanced data abundance of different languages may cause performance degradation, leading to asynchronous peak performance for different languages during training, especially on tail ones. Sometimes even the data itself may become unavailable as a result of the enhanced privacy protection. Existing work tend to significantly increase the model size or learn language-specific decoders to accommodate each language separately. In this study, we explore simple yet effective Language-Dependent Adapter (LDA) finetuning under a cascaded Conformer transducer framework enhanced by teacher pseudo-labeling for tail languages in the streaming multilingual ASR. The adapter only accounts for 0.4% of the full model per language. It is plugged into the frozen foundation model and is the only trainable module during the finetuning process with noisy student training. The final model merges the adapter parameters from different checkpoints for different languages. The model performance is validated on a challenging multilingual dictation dataset, which includes 39 tail languages across Latin, Greek, Arabic, etc. Our proposed method brings 12.2% word error rate reduction on average and up to 37.5% on a single locale. Furthermore, we show that our parameter-efficient LDA can match the quality of the full model finetuning, thus greatly alleviating the asynchronous peak performance issue.
Conditional Adapters: Parameter-efficient Transfer Learning with Fast Inference
Apr 11, 2023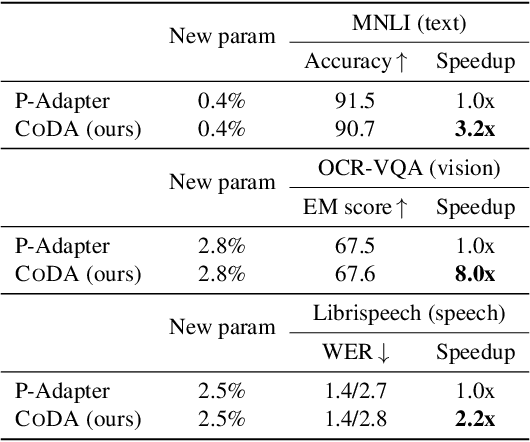

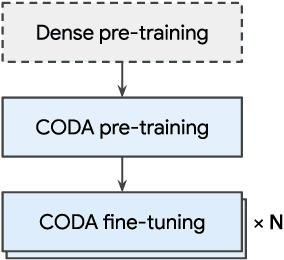
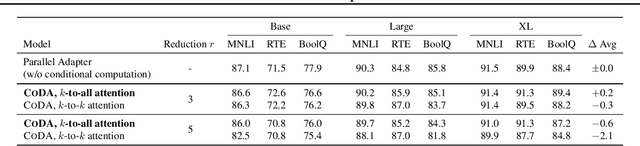
We propose Conditional Adapter (CoDA), a parameter-efficient transfer learning method that also improves inference efficiency. CoDA generalizes beyond standard adapter approaches to enable a new way of balancing speed and accuracy using conditional computation. Starting with an existing dense pretrained model, CoDA adds sparse activation together with a small number of new parameters and a light-weight training phase. Our experiments demonstrate that the CoDA approach provides an unexpectedly efficient way to transfer knowledge. Across a variety of language, vision, and speech tasks, CoDA achieves a 2x to 8x inference speed-up compared to the state-of-the-art Adapter approach with moderate to no accuracy loss and the same parameter efficiency.
Xtal2DoS: Attention-based Crystal to Sequence Learning for Density of States Prediction
Feb 03, 2023Modern machine learning techniques have been extensively applied to materials science, especially for property prediction tasks. A majority of these methods address scalar property predictions, while more challenging spectral properties remain less emphasized. We formulate a crystal-to-sequence learning task and propose a novel attention-based learning method, Xtal2DoS, which decodes the sequential representation of the material density of states (DoS) properties by incorporating the learned atomic embeddings through attention networks. Experiments show Xtal2DoS is faster than the existing models, and consistently outperforms other state-of-the-art methods on four metrics for two fundamental spectral properties, phonon and electronic DoS.
Efficient Domain Adaptation for Speech Foundation Models
Feb 03, 2023

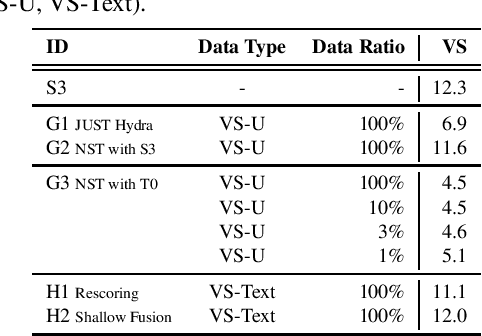

Foundation models (FMs), that are trained on broad data at scale and are adaptable to a wide range of downstream tasks, have brought large interest in the research community. Benefiting from the diverse data sources such as different modalities, languages and application domains, foundation models have demonstrated strong generalization and knowledge transfer capabilities. In this paper, we present a pioneering study towards building an efficient solution for FM-based speech recognition systems. We adopt the recently developed self-supervised BEST-RQ for pretraining, and propose the joint finetuning with both source and unsupervised target domain data using JUST Hydra. The FM encoder adapter and decoder are then finetuned to the target domain with a small amount of supervised in-domain data. On a large-scale YouTube and Voice Search task, our method is shown to be both data and model parameter efficient. It achieves the same quality with only 21.6M supervised in-domain data and 130.8M finetuned parameters, compared to the 731.1M model trained from scratch on additional 300M supervised in-domain data.
Gaussian Mixture Variational Autoencoder with Contrastive Learning for Multi-Label Classification
Dec 02, 2021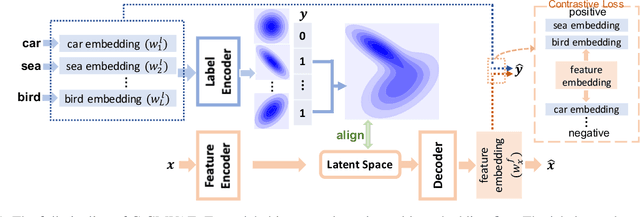
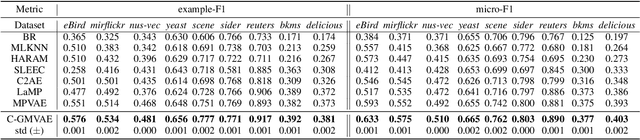
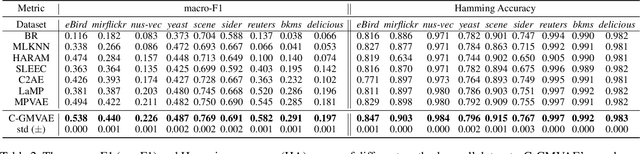
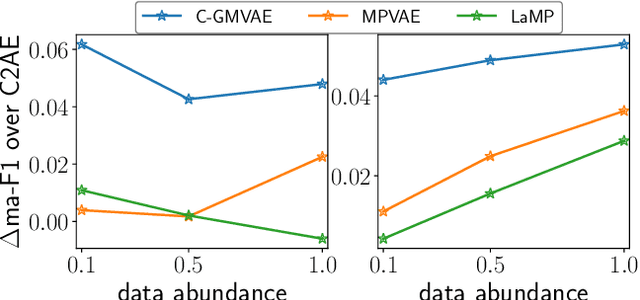
Multi-label classification (MLC) is a prediction task where each sample can have more than one label. We propose a novel contrastive learning boosted multi-label prediction model based on a Gaussian mixture variational autoencoder (C-GMVAE), which learns a multimodal prior space and employs a contrastive loss. Many existing methods introduce extra complex neural modules to capture the label correlations, in addition to the prediction modules. We found that by using contrastive learning in the supervised setting, we can exploit label information effectively, and learn meaningful feature and label embeddings capturing both the label correlations and predictive power, without extra neural modules. Our method also adopts the idea of learning and aligning latent spaces for both features and labels. C-GMVAE imposes a Gaussian mixture structure on the latent space, to alleviate posterior collapse and over-regularization issues, in contrast to previous works based on a unimodal prior. C-GMVAE outperforms existing methods on multiple public datasets and can often match other models' full performance with only 50% of the training data. Furthermore, we show that the learnt embeddings provide insights into the interpretation of label-label interactions.
A GNN-RNN Approach for Harnessing Geospatial and Temporal Information: Application to Crop Yield Prediction
Nov 17, 2021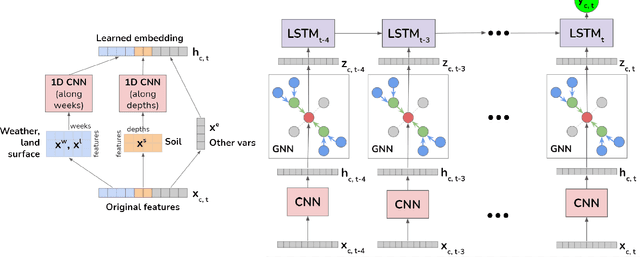
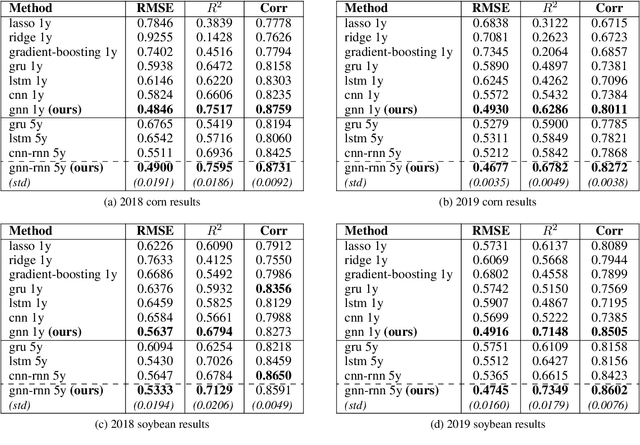
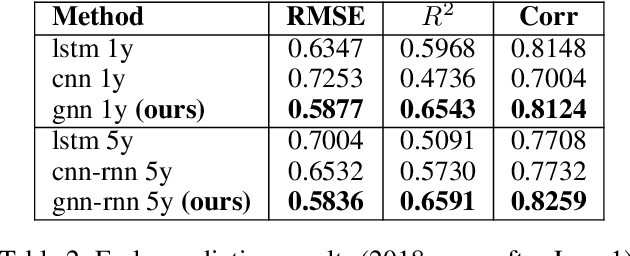
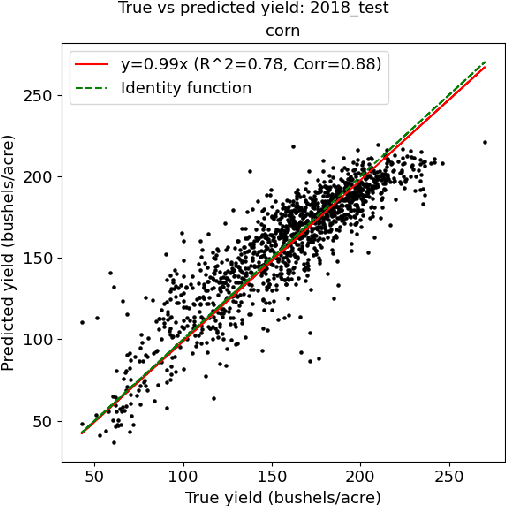
Climate change is posing new challenges to crop-related concerns including food insecurity, supply stability and economic planning. As one of the central challenges, crop yield prediction has become a pressing task in the machine learning field. Despite its importance, the prediction task is exceptionally complicated since crop yields depend on various factors such as weather, land surface, soil quality as well as their interactions. In recent years, machine learning models have been successfully applied in this domain. However, these models either restrict their tasks to a relatively small region, or only study over a single or few years, which makes them hard to generalize spatially and temporally. In this paper, we introduce a novel graph-based recurrent neural network for crop yield prediction, to incorporate both geographical and temporal knowledge in the model, and further boost predictive power. Our method is trained, validated, and tested on over 2000 counties from 41 states in the US mainland, covering years from 1981 to 2019. As far as we know, this is the first machine learning method that embeds geographical knowledge in crop yield prediction and predicts the crop yields at county level nationwide. We also laid a solid foundation for the comparison with other machine learning baselines by applying well-known linear models, tree-based models, deep learning methods and comparing their performance. Experiments show that our proposed method consistently outperforms the existing state-of-the-art methods on various metrics, validating the effectiveness of geospatial and temporal information.
Joint Unsupervised and Supervised Training for Multilingual ASR
Nov 15, 2021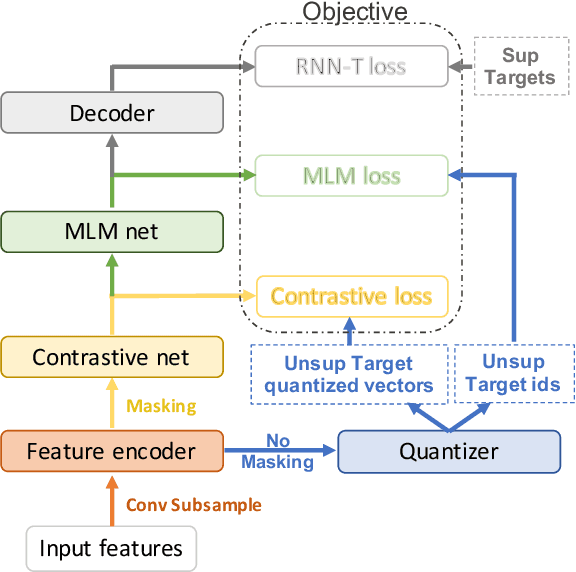
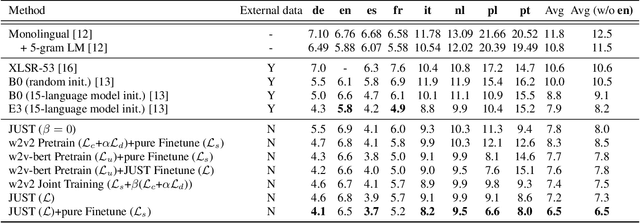
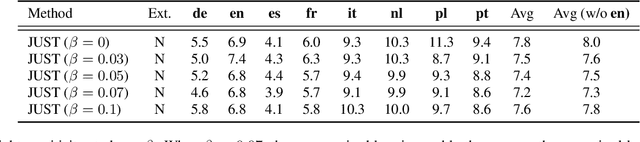
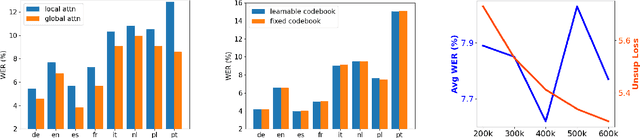
Self-supervised training has shown promising gains in pretraining models and facilitating the downstream finetuning for speech recognition, like multilingual ASR. Most existing methods adopt a 2-stage scheme where the self-supervised loss is optimized in the first pretraining stage, and the standard supervised finetuning resumes in the second stage. In this paper, we propose an end-to-end (E2E) Joint Unsupervised and Supervised Training (JUST) method to combine the supervised RNN-T loss and the self-supervised contrastive and masked language modeling (MLM) losses. We validate its performance on the public dataset Multilingual LibriSpeech (MLS), which includes 8 languages and is extremely imbalanced. On MLS, we explore (1) JUST trained from scratch, and (2) JUST finetuned from a pretrained checkpoint. Experiments show that JUST can consistently outperform other existing state-of-the-art methods, and beat the monolingual baseline by a significant margin, demonstrating JUST's capability of handling low-resource languages in multilingual ASR. Our average WER of all languages outperforms average monolingual baseline by 33.3%, and the state-of-the-art 2-stage XLSR by 32%. On low-resource languages like Polish, our WER is less than half of the monolingual baseline and even beats the supervised transfer learning method which uses external supervision.
Contrastively Disentangled Sequential Variational Autoencoder
Oct 22, 2021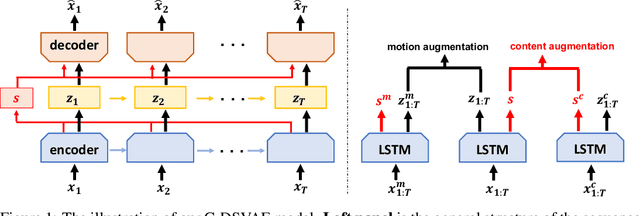
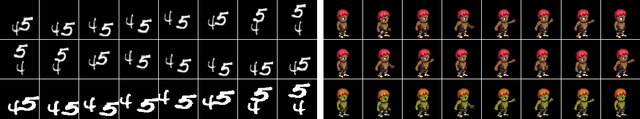

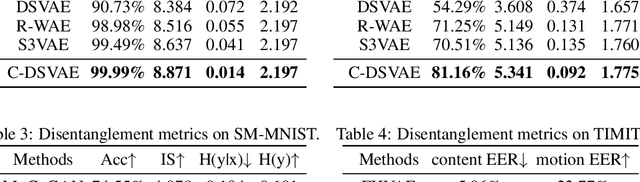
Self-supervised disentangled representation learning is a critical task in sequence modeling. The learnt representations contribute to better model interpretability as well as the data generation, and improve the sample efficiency for downstream tasks. We propose a novel sequence representation learning method, named Contrastively Disentangled Sequential Variational Autoencoder (C-DSVAE), to extract and separate the static (time-invariant) and dynamic (time-variant) factors in the latent space. Different from previous sequential variational autoencoder methods, we use a novel evidence lower bound which maximizes the mutual information between the input and the latent factors, while penalizes the mutual information between the static and dynamic factors. We leverage contrastive estimations of the mutual information terms in training, together with simple yet effective augmentation techniques, to introduce additional inductive biases. Our experiments show that C-DSVAE significantly outperforms the previous state-of-the-art methods on multiple metrics.
HOT-VAE: Learning High-Order Label Correlation for Multi-Label Classification via Attention-Based Variational Autoencoders
Mar 09, 2021


Understanding how environmental characteristics affect bio-diversity patterns, from individual species to communities of species, is critical for mitigating effects of global change. A central goal for conservation planning and monitoring is the ability to accurately predict the occurrence of species communities and how these communities change over space and time. This in turn leads to a challenging and long-standing problem in the field of computer science - how to perform ac-curate multi-label classification with hundreds of labels? The key challenge of this problem is its exponential-sized output space with regards to the number of labels to be predicted.Therefore, it is essential to facilitate the learning process by exploiting correlations (or dependency) among labels. Previous methods mostly focus on modelling the correlation on label pairs; however, complex relations between real-world objects often go beyond second order. In this paper, we pro-pose a novel framework for multi-label classification, High-order Tie-in Variational Autoencoder (HOT-VAE), which per-forms adaptive high-order label correlation learning. We experimentally verify that our model outperforms the existing state-of-the-art approaches on a bird distribution dataset on both conventional F1 scores and a variety of ecological metrics. To show our method is general, we also perform empirical analysis on seven other public real-world datasets in several application domains, and Hot-VAE exhibits superior performance to previous methods.