 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Domain Adaptation for Speech Foundation Models
Feb 03, 2023

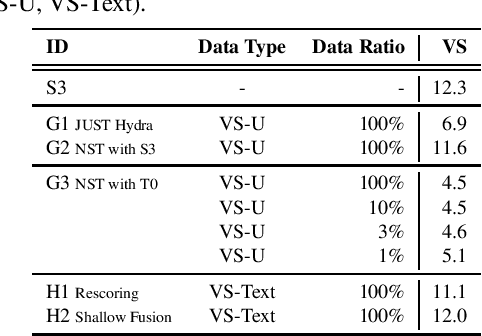

Foundation models (FMs), that are trained on broad data at scale and are adaptable to a wide range of downstream tasks, have brought large interest in the research community. Benefiting from the diverse data sources such as different modalities, languages and application domains, foundation models have demonstrated strong generalization and knowledge transfer capabilities. In this paper, we present a pioneering study towards building an efficient solution for FM-based speech recognition systems. We adopt the recently developed self-supervised BEST-RQ for pretraining, and propose the joint finetuning with both source and unsupervised target domain data using JUST Hydra. The FM encoder adapter and decoder are then finetuned to the target domain with a small amount of supervised in-domain data. On a large-scale YouTube and Voice Search task, our method is shown to be both data and model parameter efficient. It achieves the same quality with only 21.6M supervised in-domain data and 130.8M finetuned parameters, compared to the 731.1M model trained from scratch on additional 300M supervised in-domain data.
Streaming Intended Query Detection using E2E Modeling for Continued Conversation
Aug 29, 2022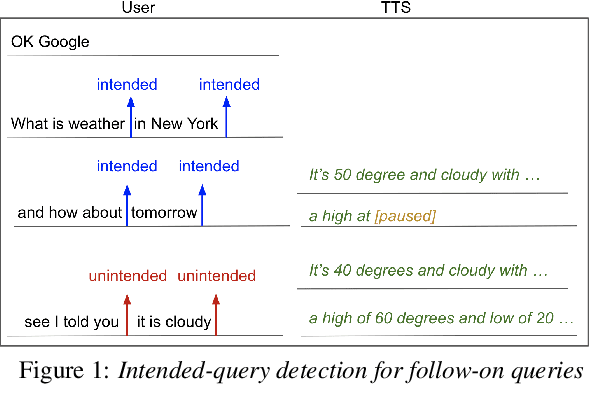

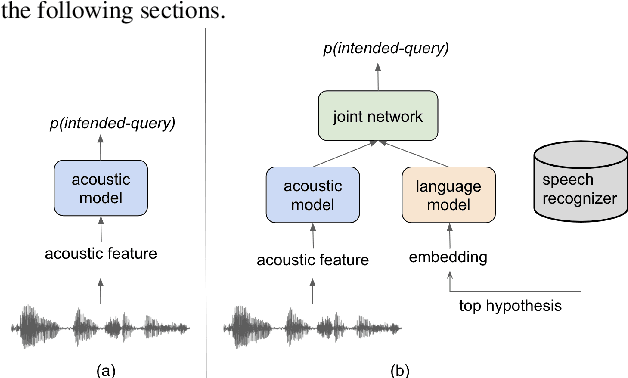
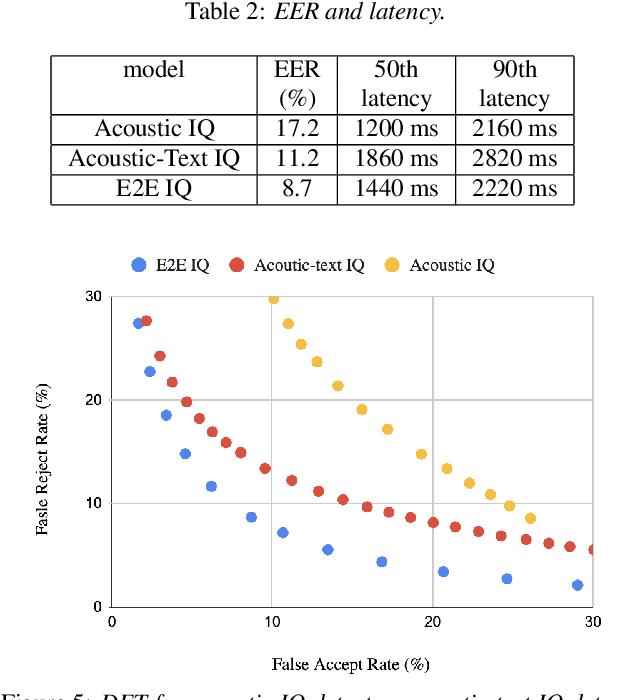
In voice-enabled applications, a predetermined hotword isusually used to activate a device in order to attend to the query.However, speaking queries followed by a hotword each timeintroduces a cognitive burden in continued conversations. Toavoid repeating a hotword, we propose a streaming end-to-end(E2E) intended query detector that identifies the utterancesdirected towards the device and filters out other utterancesnot directed towards device. The proposed approach incor-porates the intended query detector into the E2E model thatalready folds different components of the speech recognitionpipeline into one neural network.The E2E modeling onspeech decoding and intended query detection also allows us todeclare a quick intended query detection based on early partialrecognition result, which is important to decrease latencyand make the system responsive. We demonstrate that theproposed E2E approach yields a 22% relative improvement onequal error rate (EER) for the detection accuracy and 600 mslatency improvement compared with an independent intendedquery detector. In our experiment, the proposed model detectswhether the user is talking to the device with a 8.7% EERwithin 1.4 seconds of median latency after user starts speaking.