 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Improved Long-Form Speech Recognition by Jointly Modeling the Primary and Non-primary Speakers
Dec 18, 2023ASR models often suffer from a long-form deletion problem where the model predicts sequential blanks instead of words when transcribing a lengthy audio (in the order of minutes or hours). From the perspective of a user or downstream system consuming the ASR results, this behavior can be perceived as the model "being stuck", and potentially make the product hard to use. One of the culprits for long-form deletion is training-test data mismatch, which can happen even when the model is trained on diverse and large-scale data collected from multiple application domains. In this work, we introduce a novel technique to simultaneously model different groups of speakers in the audio along with the standard transcript tokens. Speakers are grouped as primary and non-primary, which connects the application domains and significantly alleviates the long-form deletion problem. This improved model neither needs any additional training data nor incurs additional training or inference cost.
Towards General-Purpose Text-Instruction-Guided Voice Conversion
Sep 25, 2023



This paper introduces a novel voice conversion (VC) model, guided by text instructions such as "articulate slowly with a deep tone" or "speak in a cheerful boyish voice". Unlike traditional methods that rely on reference utterances to determine the attributes of the converted speech, our model adds versatility and specificity to voice conversion. The proposed VC model is a neural codec language model which processes a sequence of discrete codes, resulting in the code sequence of converted speech. It utilizes text instructions as style prompts to modify the prosody and emotional information of the given speech. In contrast to previous approaches, which often rely on employing separate encoders like prosody and content encoders to handle different aspects of the source speech, our model handles various information of speech in an end-to-end manner. Experiments have demonstrated the impressive capabilities of our model in comprehending instructions and delivering reasonable results.
Text Injection for Capitalization and Turn-Taking Prediction in Speech Models
Aug 14, 2023



Text injection for automatic speech recognition (ASR), wherein unpaired text-only data is used to supplement paired audio-text data, has shown promising improvements for word error rate. This study examines the use of text injection for auxiliary tasks, which are the non-ASR tasks often performed by an E2E model. In this work, we use joint end-to-end and internal language model training (JEIT) as our text injection algorithm to train an ASR model which performs two auxiliary tasks. The first is capitalization, which is a de-normalization task. The second is turn-taking prediction, which attempts to identify whether a user has completed their conversation turn in a digital assistant interaction. We show results demonstrating that our text injection method boosts capitalization performance for long-tail data, and improves turn-taking detection recall.
Semantic Segmentation with Bidirectional Language Models Improves Long-form ASR
May 28, 2023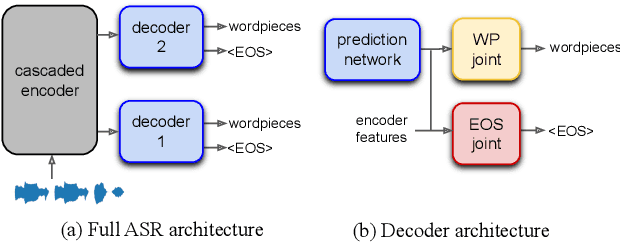
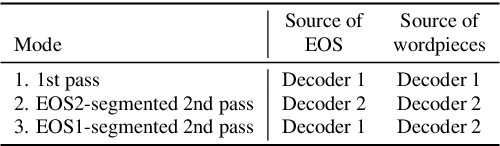
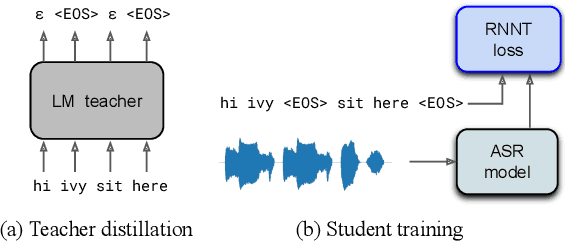
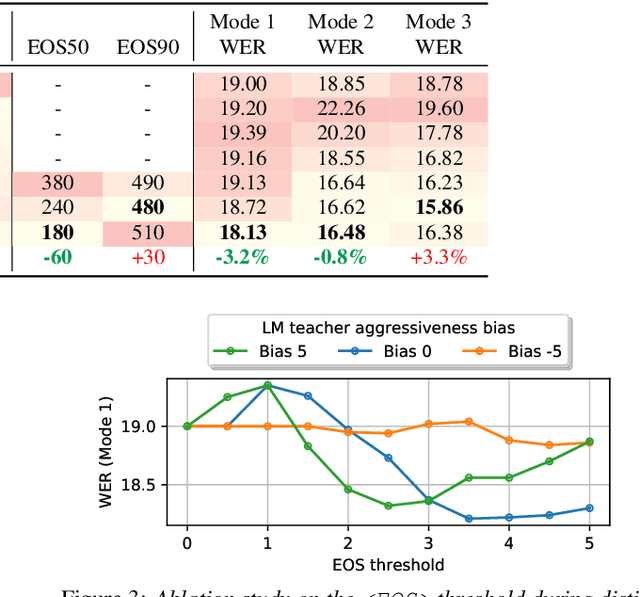
We propose a method of segmenting long-form speech by separating semantically complete sentences within the utterance. This prevents the ASR decoder from needlessly processing faraway context while also preventing it from missing relevant context within the current sentence. Semantically complete sentence boundaries are typically demarcated by punctuation in written text; but unfortunately, spoken real-world utterances rarely contain punctuation. We address this limitation by distilling punctuation knowledge from a bidirectional teacher language model (LM) trained on written, punctuated text. We compare our segmenter, which is distilled from the LM teacher, against a segmenter distilled from a acoustic-pause-based teacher used in other works, on a streaming ASR pipeline. The pipeline with our segmenter achieves a 3.2% relative WER gain along with a 60 ms median end-of-segment latency reduction on a YouTube captioning task.
UML: A Universal Monolingual Output Layer for Multilingual ASR
Feb 22, 2023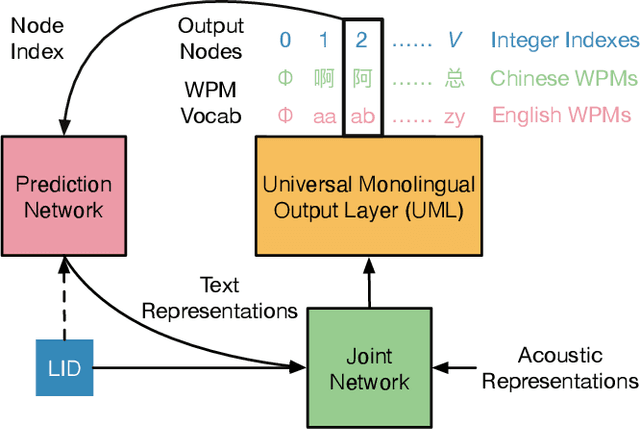
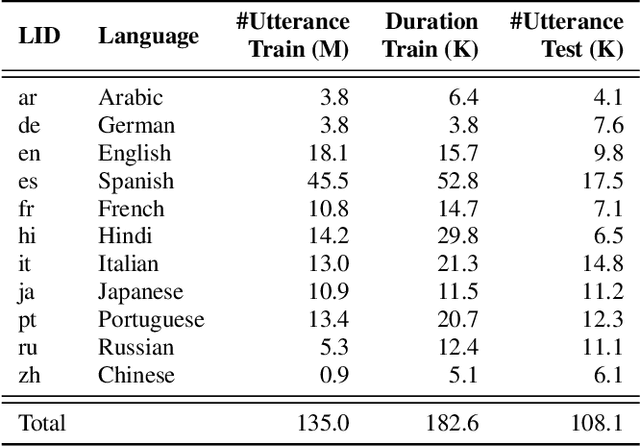
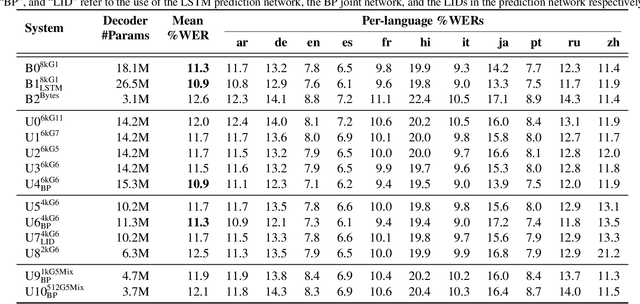
Word-piece models (WPMs) are commonly used subword units in state-of-the-art end-to-end automatic speech recognition (ASR) systems. For multilingual ASR, due to the differences in written scripts across languages, multilingual WPMs bring the challenges of having overly large output layers and scaling to more languages. In this work, we propose a universal monolingual output layer (UML) to address such problems. Instead of one output node for only one WPM, UML re-associates each output node with multiple WPMs, one for each language, and results in a smaller monolingual output layer shared across languages. Consequently, the UML enables to switch in the interpretation of each output node depending on the language of the input speech. Experimental results on an 11-language voice search task demonstrated the feasibility of using UML for high-quality and high-efficiency multilingual streaming ASR.
Unified End-to-End Speech Recognition and Endpointing for Fast and Efficient Speech Systems
Nov 01, 2022



Automatic speech recognition (ASR) systems typically rely on an external endpointer (EP) model to identify speech boundaries. In this work, we propose a method to jointly train the ASR and EP tasks in a single end-to-end (E2E) multitask model, improving EP quality by optionally leveraging information from the ASR audio encoder. We introduce a "switch" connection, which trains the EP to consume either the audio frames directly or low-level latent representations from the ASR model. This results in a single E2E model that can be used during inference to perform frame filtering at low cost, and also make high quality end-of-query (EOQ) predictions based on ongoing ASR computation. We present results on a voice search test set showing that, compared to separate single-task models, this approach reduces median endpoint latency by 120 ms (30.8% reduction), and 90th percentile latency by 170 ms (23.0% reduction), without regressing word error rate. For continuous recognition, WER improves by 10.6% (relative).
Streaming End-to-End Multilingual Speech Recognition with Joint Language Identification
Sep 13, 2022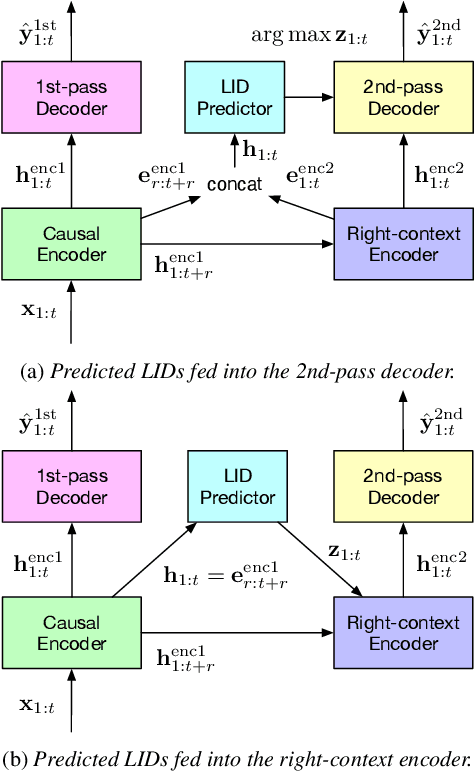


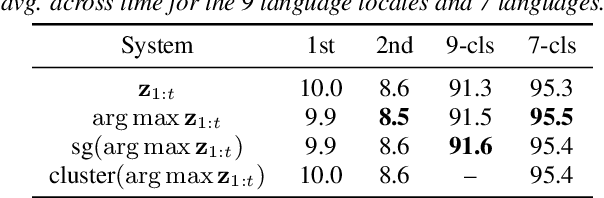
Language identification is critical for many downstream tasks in automatic speech recognition (ASR), and is beneficial to integrate into multilingual end-to-end ASR as an additional task. In this paper, we propose to modify the structure of the cascaded-encoder-based recurrent neural network transducer (RNN-T) model by integrating a per-frame language identifier (LID) predictor. RNN-T with cascaded encoders can achieve streaming ASR with low latency using first-pass decoding with no right-context, and achieve lower word error rates (WERs) using second-pass decoding with longer right-context. By leveraging such differences in the right-contexts and a streaming implementation of statistics pooling, the proposed method can achieve accurate streaming LID prediction with little extra test-time cost. Experimental results on a voice search dataset with 9 language locales shows that the proposed method achieves an average of 96.2% LID prediction accuracy and the same second-pass WER as that obtained by including oracle LID in the input.
A Language Agnostic Multilingual Streaming On-Device ASR System
Aug 29, 2022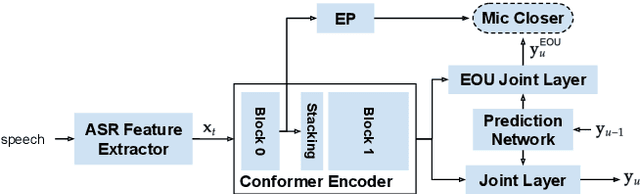
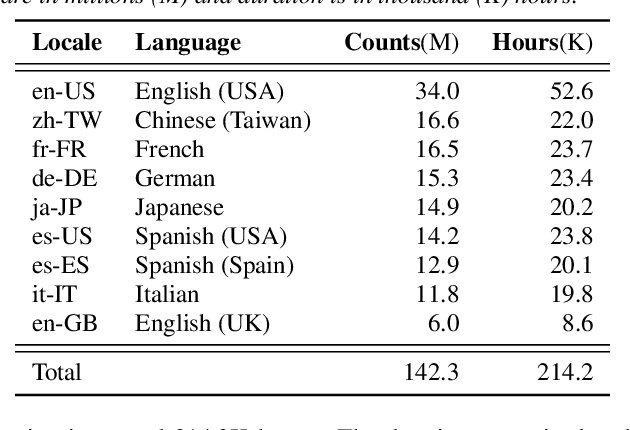
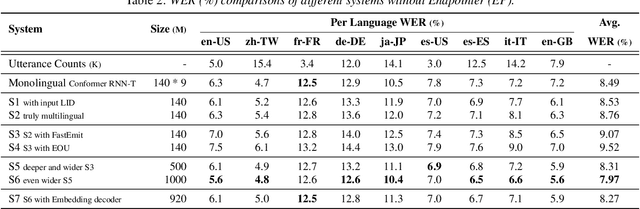
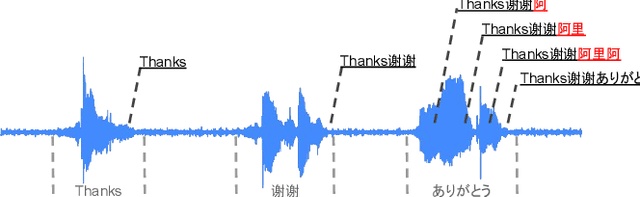
On-device end-to-end (E2E) models have shown improvements over a conventional model on English Voice Search tasks in both quality and latency. E2E models have also shown promising results for multilingual automatic speech recognition (ASR). In this paper, we extend our previous capacity solution to streaming applications and present a streaming multilingual E2E ASR system that runs fully on device with comparable quality and latency to individual monolingual models. To achieve that, we propose an Encoder Endpointer model and an End-of-Utterance (EOU) Joint Layer for a better quality and latency trade-off. Our system is built in a language agnostic manner allowing it to natively support intersentential code switching in real time. To address the feasibility concerns on large models, we conducted on-device profiling and replaced the time consuming LSTM decoder with the recently developed Embedding decoder. With these changes, we managed to run such a system on a mobile device in less than real time.