 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMassive Sound Embedding Benchmark (MSEB)
Feb 06, 2026Audio is a critical component of multimodal perception, and any truly intelligent system must demonstrate a wide range of auditory capabilities. These capabilities include transcription, classification, retrieval, reasoning, segmentation, clustering, reranking, and reconstruction. Fundamentally, each task involves transforming a raw audio signal into a meaningful 'embedding' - be it a single vector, a sequence of continuous or discrete representations, or another structured form - which then serves as the basis for generating the task's final response. To accelerate progress towards robust machine auditory intelligence, we present the Massive Sound Embedding Benchmark (MSEB): an extensible framework designed to evaluate the auditory components of any multimodal system. In its first release, MSEB offers a comprehensive suite of eight core tasks, with more planned for the future, supported by diverse datasets, including the new, large-scale Simple Voice Questions (SVQ) dataset. Our initial experiments establish clear performance headrooms, highlighting the significant opportunity to improve real-world multimodal experiences where audio is a core signal. We encourage the research community to use MSEB to assess their algorithms and contribute to its growth. The library is publicly hosted at github.
Retrieval Augmented Question Answering: When Should LLMs Admit Ignorance?
Dec 29, 2025The success of expanded context windows in Large Language Models (LLMs) has driven increased use of broader context in retrieval-augmented generation. We investigate the use of LLMs for retrieval augmented question answering. While longer contexts make it easier to incorporate targeted knowledge, they introduce more irrelevant information that hinders the model's generation process and degrades its performance. To address the issue, we design an adaptive prompting strategy which involves splitting the retrieved information into smaller chunks and sequentially prompting a LLM to answer the question using each chunk. Adjusting the chunk size allows a trade-off between incorporating relevant information and reducing irrelevant information. Experimental results on three open-domain question answering datasets demonstrate that the adaptive strategy matches the performance of standard prompting while using fewer tokens. Our analysis reveals that when encountering insufficient information, the LLM often generates incorrect answers instead of declining to respond, which constitutes a major source of error. This finding highlights the need for further research into enhancing LLMs' ability to effectively decline requests when faced with inadequate information.
Predicting Compact Phrasal Rewrites with Large Language Models for ASR Post Editing
Jan 23, 2025



Large Language Models (LLMs) excel at rewriting tasks such as text style transfer and grammatical error correction. While there is considerable overlap between the inputs and outputs in these tasks, the decoding cost still increases with output length, regardless of the amount of overlap. By leveraging the overlap between the input and the output, Kaneko and Okazaki (2023) proposed model-agnostic edit span representations to compress the rewrites to save computation. They reported an output length reduction rate of nearly 80% with minimal accuracy impact in four rewriting tasks. In this paper, we propose alternative edit phrase representations inspired by phrase-based statistical machine translation. We systematically compare our phrasal representations with their span representations. We apply the LLM rewriting model to the task of Automatic Speech Recognition (ASR) post editing and show that our target-phrase-only edit representation has the best efficiency-accuracy trade-off. On the LibriSpeech test set, our method closes 50-60% of the WER gap between the edit span model and the full rewrite model while losing only 10-20% of the length reduction rate of the edit span model.
Dynamic Subset Tuning: Expanding the Operational Range of Parameter-Efficient Training for Large Language Models
Nov 13, 2024



We propose a novel parameter-efficient training (PET) method for large language models that adapts models to downstream tasks by optimizing a small subset of the existing model parameters. Unlike prior methods, this subset is not fixed in location but rather which parameters are modified evolves over the course of training. This dynamic parameter selection can yield good performance with many fewer parameters than extant methods. Our method enables a seamless scaling of the subset size across an arbitrary proportion of the total model size, while popular PET approaches like prompt tuning and LoRA cover only a small part of this spectrum. We match or outperform prompt tuning and LoRA in most cases on a variety of NLP tasks (MT, QA, GSM8K, SuperGLUE) for a given parameter budget across different model families and sizes.
Spelling Correction through Rewriting of Non-Autoregressive ASR Lattices
Sep 24, 2024



For end-to-end Automatic Speech Recognition (ASR) models, recognizing personal or rare phrases can be hard. A promising way to improve accuracy is through spelling correction (or rewriting) of the ASR lattice, where potentially misrecognized phrases are replaced with acoustically similar and contextually relevant alternatives. However, rewriting is challenging for ASR models trained with connectionist temporal classification (CTC) due to noisy hypotheses produced by a non-autoregressive, context-independent beam search. We present a finite-state transducer (FST) technique for rewriting wordpiece lattices generated by Transformer-based CTC models. Our algorithm performs grapheme-to-phoneme (G2P) conversion directly from wordpieces into phonemes, avoiding explicit word representations and exploiting the richness of the CTC lattice. Our approach requires no retraining or modification of the ASR model. We achieved up to a 15.2% relative reduction in sentence error rate (SER) on a test set with contextually relevant entities.
Long-Form Speech Translation through Segmentation with Finite-State Decoding Constraints on Large Language Models
Oct 23, 2023



One challenge in speech translation is that plenty of spoken content is long-form, but short units are necessary for obtaining high-quality translations. To address this mismatch, we adapt large language models (LLMs) to split long ASR transcripts into segments that can be independently translated so as to maximize the overall translation quality. We overcome the tendency of hallucination in LLMs by incorporating finite-state constraints during decoding; these eliminate invalid outputs without requiring additional training. We discover that LLMs are adaptable to transcripts containing ASR errors through prompt-tuning or fine-tuning. Relative to a state-of-the-art automatic punctuation baseline, our best LLM improves the average BLEU by 2.9 points for English-German, English-Spanish, and English-Arabic TED talk translation in 9 test sets, just by improving segmentation.
Heterogeneous Federated Learning Using Knowledge Codistillation
Oct 04, 2023



Federated Averaging, and many federated learning algorithm variants which build upon it, have a limitation: all clients must share the same model architecture. This results in unused modeling capacity on many clients, which limits model performance. To address this issue, we propose a method that involves training a small model on the entire pool and a larger model on a subset of clients with higher capacity. The models exchange information bidirectionally via knowledge distillation, utilizing an unlabeled dataset on a server without sharing parameters. We present two variants of our method, which improve upon federated averaging on image classification and language modeling tasks. We show this technique can be useful even if only out-of-domain or limited in-domain distillation data is available. Additionally, the bi-directional knowledge distillation allows for domain transfer between the models when different pool populations introduce domain shift.
Towards an On-device Agent for Text Rewriting
Aug 22, 2023



Large Language Models (LLMs) have demonstrated impressive capabilities for text rewriting. Nonetheless, the large sizes of these models make them impractical for on-device inference, which would otherwise allow for enhanced privacy and economical inference. Creating a smaller yet potent language model for text rewriting presents a formidable challenge because it requires balancing the need for a small size with the need to retain the emergent capabilities of the LLM, that requires costly data collection. To address the above challenge, we introduce a new instruction tuning approach for building a mobile-centric text rewriting model. Our strategies enable the generation of high quality training data without any human labeling. In addition, we propose a heuristic reinforcement learning framework which substantially enhances performance without requiring preference data. To further bridge the performance gap with the larger server-side model, we propose an effective approach that combines the mobile rewrite agent with the server model using a cascade. To tailor the text rewriting tasks to mobile scenarios, we introduce MessageRewriteEval, a benchmark that focuses on text rewriting for messages through natural language instructions. Through empirical experiments, we demonstrate that our on-device model surpasses the current state-of-the-art LLMs in text rewriting while maintaining a significantly reduced model size. Notably, we show that our proposed cascading approach improves model performance.
Semantic Segmentation with Bidirectional Language Models Improves Long-form ASR
May 28, 2023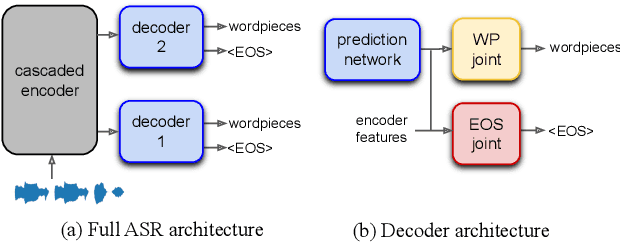
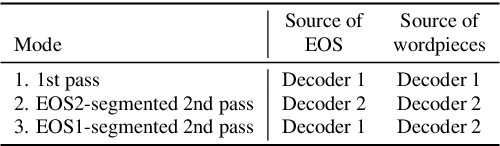
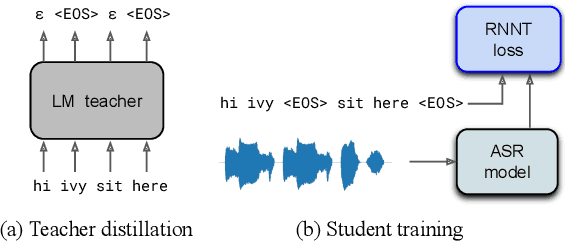
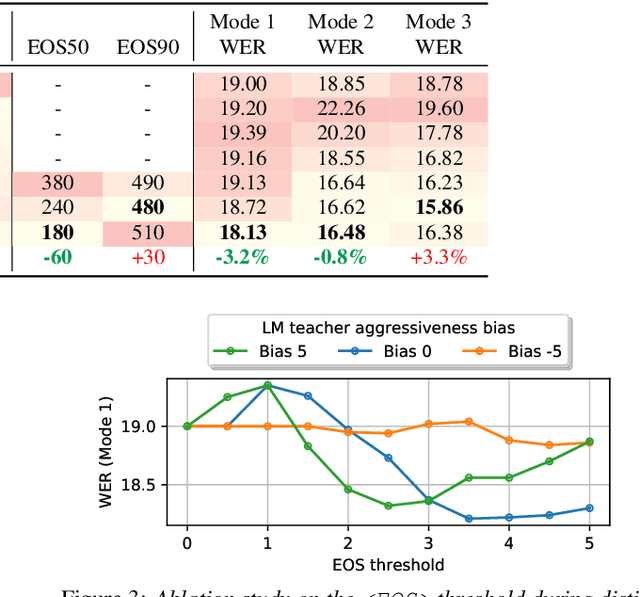
We propose a method of segmenting long-form speech by separating semantically complete sentences within the utterance. This prevents the ASR decoder from needlessly processing faraway context while also preventing it from missing relevant context within the current sentence. Semantically complete sentence boundaries are typically demarcated by punctuation in written text; but unfortunately, spoken real-world utterances rarely contain punctuation. We address this limitation by distilling punctuation knowledge from a bidirectional teacher language model (LM) trained on written, punctuated text. We compare our segmenter, which is distilled from the LM teacher, against a segmenter distilled from a acoustic-pause-based teacher used in other works, on a streaming ASR pipeline. The pipeline with our segmenter achieves a 3.2% relative WER gain along with a 60 ms median end-of-segment latency reduction on a YouTube captioning task.
Measuring Re-identification Risk
Apr 12, 2023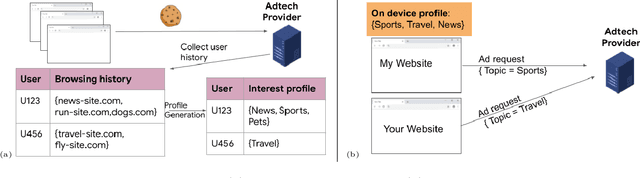
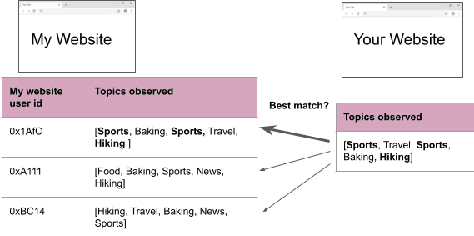
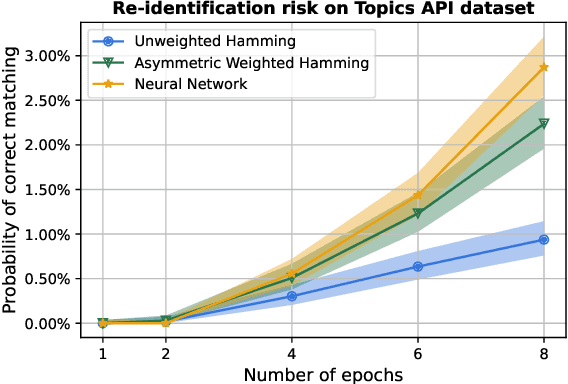
Compact user representations (such as embeddings) form the backbone of personalization services. In this work, we present a new theoretical framework to measure re-identification risk in such user representations. Our framework, based on hypothesis testing, formally bounds the probability that an attacker may be able to obtain the identity of a user from their representation. As an application, we show how our framework is general enough to model important real-world applications such as the Chrome's Topics API for interest-based advertising. We complement our theoretical bounds by showing provably good attack algorithms for re-identification that we use to estimate the re-identification risk in the Topics API. We believe this work provides a rigorous and interpretable notion of re-identification risk and a framework to measure it that can be used to inform real-world applications.