 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImprove Mathematical Reasoning in Language Models by Automated Process Supervision
Jun 05, 2024

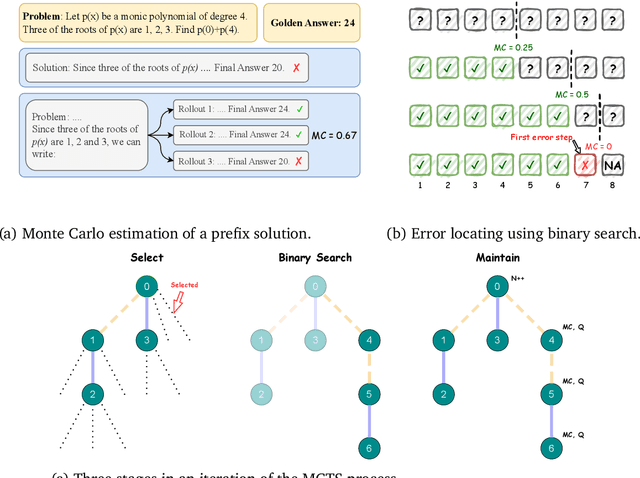
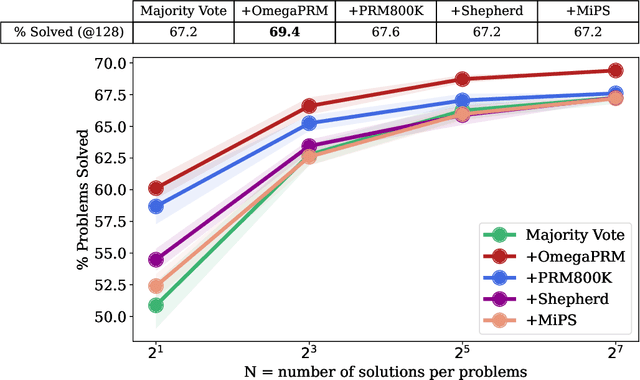
Complex multi-step reasoning tasks, such as solving mathematical problems or generating code, remain a significant hurdle for even the most advanced large language models (LLMs). Verifying LLM outputs with an Outcome Reward Model (ORM) is a standard inference-time technique aimed at enhancing the reasoning performance of LLMs. However, this still proves insufficient for reasoning tasks with a lengthy or multi-hop reasoning chain, where the intermediate outcomes are neither properly rewarded nor penalized. Process supervision addresses this limitation by assigning intermediate rewards during the reasoning process. To date, the methods used to collect process supervision data have relied on either human annotation or per-step Monte Carlo estimation, both prohibitively expensive to scale, thus hindering the broad application of this technique. In response to this challenge, we propose a novel divide-and-conquer style Monte Carlo Tree Search (MCTS) algorithm named \textit{OmegaPRM} for the efficient collection of high-quality process supervision data. This algorithm swiftly identifies the first error in the Chain of Thought (CoT) with binary search and balances the positive and negative examples, thereby ensuring both efficiency and quality. As a result, we are able to collect over 1.5 million process supervision annotations to train a Process Reward Model (PRM). Utilizing this fully automated process supervision alongside the weighted self-consistency algorithm, we have enhanced the instruction tuned Gemini Pro model's math reasoning performance, achieving a 69.4\% success rate on the MATH benchmark, a 36\% relative improvement from the 51\% base model performance. Additionally, the entire process operates without any human intervention, making our method both financially and computationally cost-effective compared to existing methods.
Accelerating Inference of Retrieval-Augmented Generation via Sparse Context Selection
May 25, 2024



Large language models (LLMs) augmented with retrieval exhibit robust performance and extensive versatility by incorporating external contexts. However, the input length grows linearly in the number of retrieved documents, causing a dramatic increase in latency. In this paper, we propose a novel paradigm named Sparse RAG, which seeks to cut computation costs through sparsity. Specifically, Sparse RAG encodes retrieved documents in parallel, which eliminates latency introduced by long-range attention of retrieved documents. Then, LLMs selectively decode the output by only attending to highly relevant caches auto-regressively, which are chosen via prompting LLMs with special control tokens. It is notable that Sparse RAG combines the assessment of each individual document and the generation of the response into a single process. The designed sparse mechanism in a RAG system can facilitate the reduction of the number of documents loaded during decoding for accelerating the inference of the RAG system. Additionally, filtering out undesirable contexts enhances the model's focus on relevant context, inherently improving its generation quality. Evaluation results of two datasets show that Sparse RAG can strike an optimal balance between generation quality and computational efficiency, demonstrating its generalizability across both short- and long-form generation tasks.
Multi-step Problem Solving Through a Verifier: An Empirical Analysis on Model-induced Process Supervision
Feb 05, 2024



Process supervision, using a trained verifier to evaluate the intermediate steps generated by reasoner, has demonstrated significant improvements in multi-step problem solving. In this paper, to avoid expensive human annotation effort on the verifier training data, we introduce Model-induced Process Supervision (MiPS), a novel method for automating data curation. MiPS annotates an intermediate step by sampling completions of this solution through the reasoning model, and obtaining an accuracy defined as the proportion of correct completions. Errors in the reasoner would cause MiPS to underestimate the accuracy of intermediate steps, therefore, we suggest and empirically show that verification focusing on high predicted scores of the verifier shall be preferred over that of low predicted scores, contrary to prior work. Our approach significantly improves the performance of PaLM 2 on math and coding tasks (accuracy +0.67% on GSM8K, +4.16% on MATH, +0.92% on MBPP compared with an output supervision trained verifier). Additionally, our study demonstrates that the verifier exhibits strong generalization ability across different reasoning models.
SiRA: Sparse Mixture of Low Rank Adaptation
Nov 15, 2023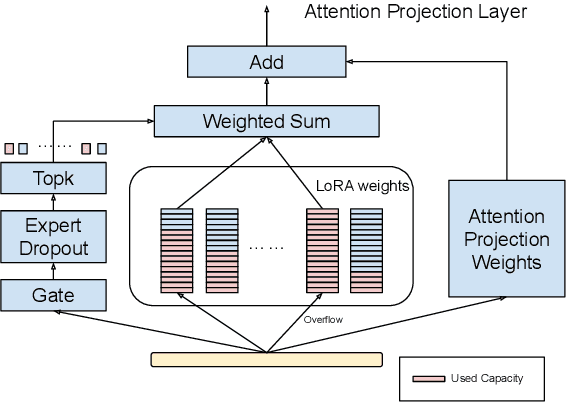



Parameter Efficient Tuning has been an prominent approach to adapt the Large Language Model to downstream tasks. Most previous works considers adding the dense trainable parameters, where all parameters are used to adapt certain task. We found this less effective empirically using the example of LoRA that introducing more trainable parameters does not help. Motivated by this we investigate the importance of leveraging "sparse" computation and propose SiRA: sparse mixture of low rank adaption. SiRA leverages the Sparse Mixture of Expert(SMoE) to boost the performance of LoRA. Specifically it enforces the top $k$ experts routing with a capacity limit restricting the maximum number of tokens each expert can process. We propose a novel and simple expert dropout on top of gating network to reduce the over-fitting issue. Through extensive experiments, we verify SiRA performs better than LoRA and other mixture of expert approaches across different single tasks and multitask settings.
Fusion-Eval: Integrating Evaluators with LLMs
Nov 15, 2023
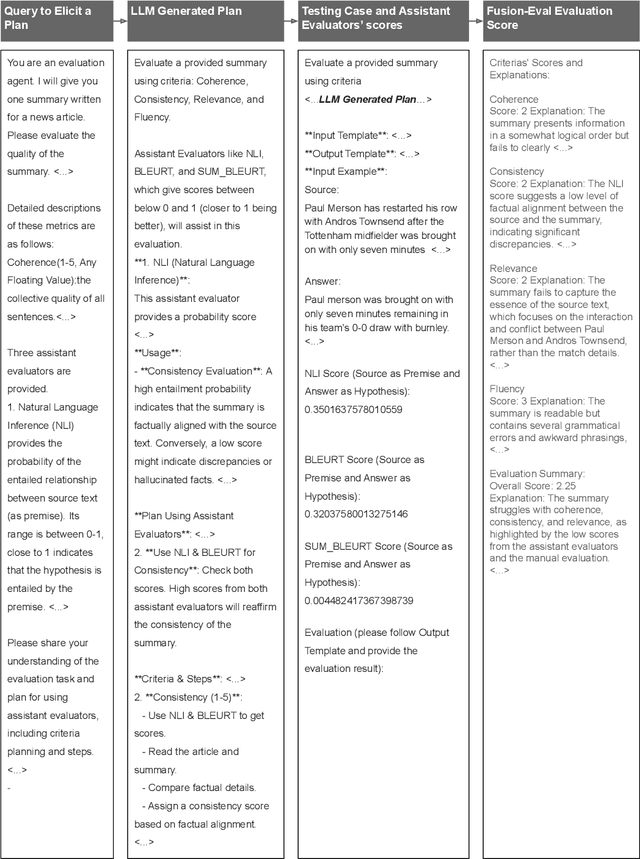
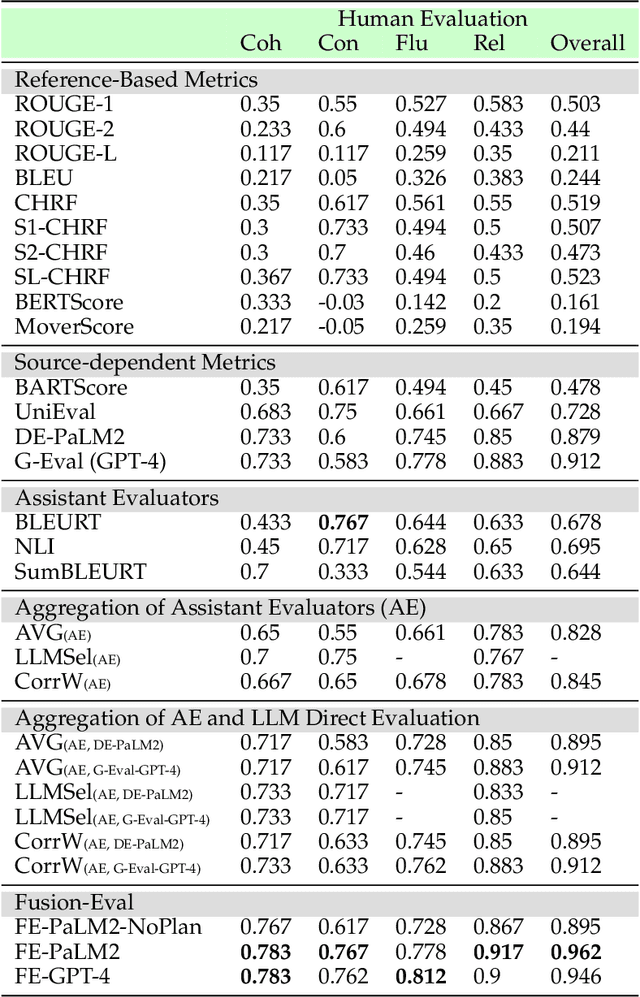
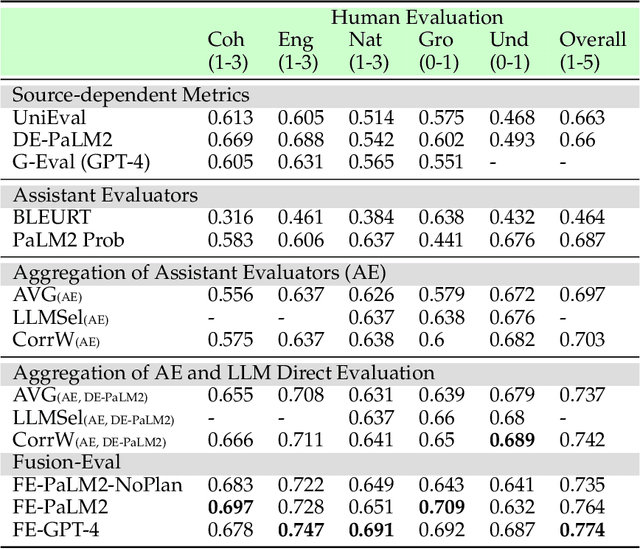
Evaluating Large Language Models (LLMs) is a complex task, especially considering the intricacies of natural language understanding and the expectations for high-level reasoning. Traditional evaluations typically lean on human-based, model-based, or automatic-metrics-based paradigms, each with its own advantages and shortcomings. We introduce "Fusion-Eval", a system that employs LLMs not solely for direct evaluations, but to skillfully integrate insights from diverse evaluators. This gives Fusion-Eval flexibility, enabling it to work effectively across diverse tasks and make optimal use of multiple references. In testing on the SummEval dataset, Fusion-Eval achieved a Spearman correlation of 0.96, outperforming other evaluators. The success of Fusion-Eval underscores the potential of LLMs to produce evaluations that closely align human perspectives, setting a new standard in the field of LLM evaluation.
Critique Ability of Large Language Models
Oct 07, 2023

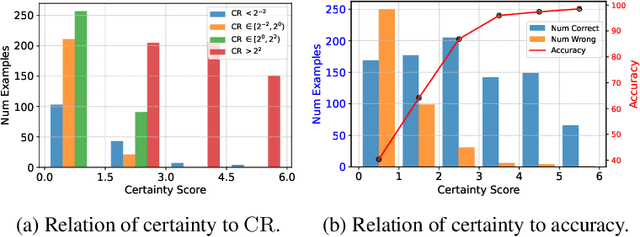

Critical thinking is essential for rational decision-making and problem-solving. This skill hinges on the ability to provide precise and reasoned critiques and is a hallmark of human intelligence. In the era of large language models (LLMs), this study explores the ability of LLMs to deliver accurate critiques across various tasks. We are interested in this topic as a capable critic model could not only serve as a reliable evaluator, but also as a source of supervised signals for model tuning. Particularly, if a model can self-critique, it has the potential for autonomous self-improvement. To examine this, we introduce a unified evaluation framework for assessing the critique abilities of LLMs. We develop a benchmark called CriticBench, which comprises 3K high-quality natural language queries and corresponding model responses; and annotate the correctness of these responses. The benchmark cover tasks such as math problem-solving, code completion, and question answering. We evaluate multiple LLMs on the collected dataset and our analysis reveals several noteworthy insights: (1) Critique is generally challenging for most LLMs, and this capability often emerges only when models are sufficiently large. (2) In particular, self-critique is especially difficult. Even top-performing LLMs struggle to achieve satisfactory performance. (3) Models tend to have lower critique accuracy on problems where they are most uncertain. To this end, we introduce a simple yet effective baseline named self-check, which leverages self-critique to improve task performance for various models. We hope this study serves as an initial exploration into understanding the critique abilities of LLMs, and aims to inform future research, including the development of more proficient critic models and the application of critiques across diverse tasks.
Towards an On-device Agent for Text Rewriting
Aug 22, 2023



Large Language Models (LLMs) have demonstrated impressive capabilities for text rewriting. Nonetheless, the large sizes of these models make them impractical for on-device inference, which would otherwise allow for enhanced privacy and economical inference. Creating a smaller yet potent language model for text rewriting presents a formidable challenge because it requires balancing the need for a small size with the need to retain the emergent capabilities of the LLM, that requires costly data collection. To address the above challenge, we introduce a new instruction tuning approach for building a mobile-centric text rewriting model. Our strategies enable the generation of high quality training data without any human labeling. In addition, we propose a heuristic reinforcement learning framework which substantially enhances performance without requiring preference data. To further bridge the performance gap with the larger server-side model, we propose an effective approach that combines the mobile rewrite agent with the server model using a cascade. To tailor the text rewriting tasks to mobile scenarios, we introduce MessageRewriteEval, a benchmark that focuses on text rewriting for messages through natural language instructions. Through empirical experiments, we demonstrate that our on-device model surpasses the current state-of-the-art LLMs in text rewriting while maintaining a significantly reduced model size. Notably, we show that our proposed cascading approach improves model performance.
RewriteLM: An Instruction-Tuned Large Language Model for Text Rewriting
May 25, 2023



Large Language Models (LLMs) have demonstrated impressive zero-shot capabilities in long-form text generation tasks expressed through natural language instructions. However, user expectations for long-form text rewriting is high, and unintended rewrites (''hallucinations'') produced by the model can negatively impact its overall performance. Existing evaluation benchmarks primarily focus on limited rewriting styles and sentence-level rewriting rather than long-form open-ended rewriting.We introduce OpenRewriteEval, a novel benchmark that covers a wide variety of rewriting types expressed through natural language instructions. It is specifically designed to facilitate the evaluation of open-ended rewriting of long-form texts. In addition, we propose a strong baseline model, RewriteLM, an instruction-tuned large language model for long-form text rewriting. We develop new strategies that facilitate the generation of diverse instructions and preference data with minimal human intervention. We conduct empirical experiments and demonstrate that our model outperforms the current state-of-the-art LLMs in text rewriting. Specifically, it excels in preserving the essential content and meaning of the source text, minimizing the generation of ''hallucinated'' content, while showcasing the ability to generate rewrites with diverse wording and structures.
Bridging the Gap Between Object Detection and User Intent via Query-Modulation
Jun 18, 2021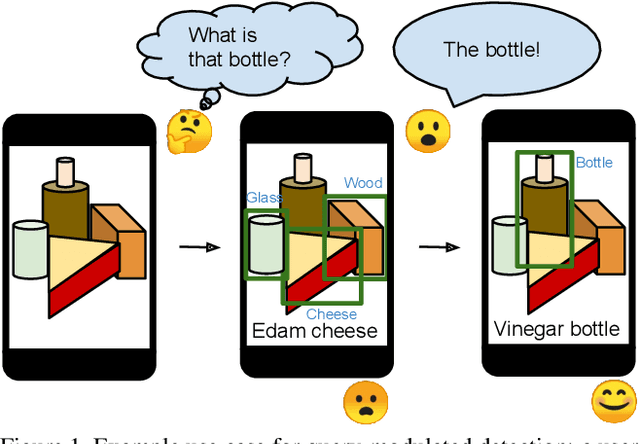

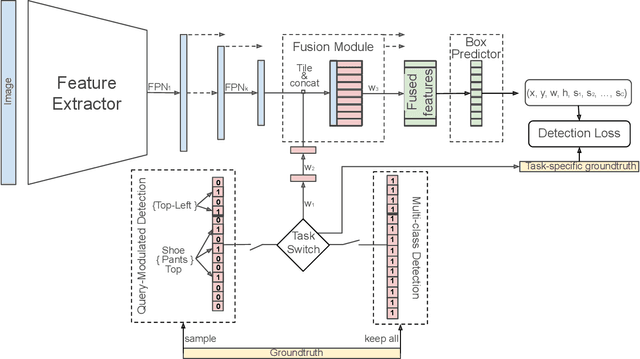
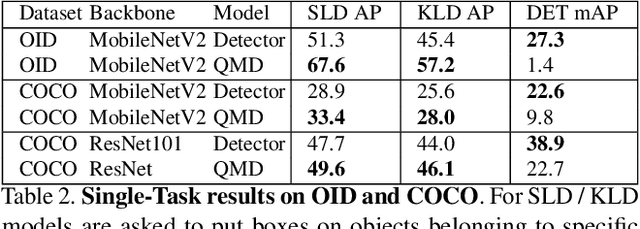
When interacting with objects through cameras, or pictures, users often have a specific intent. For example, they may want to perform a visual search. However, most object detection models ignore the user intent, relying on image pixels as their only input. This often leads to incorrect results, such as lack of a high-confidence detection on the object of interest, or detection with a wrong class label. In this paper we investigate techniques to modulate standard object detectors to explicitly account for the user intent, expressed as an embedding of a simple query. Compared to standard object detectors, query-modulated detectors show superior performance at detecting objects for a given label of interest. Thanks to large-scale training data synthesized from standard object detection annotations, query-modulated detectors can also outperform specialized referring expression recognition systems. Furthermore, they can be simultaneously trained to solve for both query-modulated detection and standard object detection.
Large-Scale Generative Data-Free Distillation
Dec 10, 2020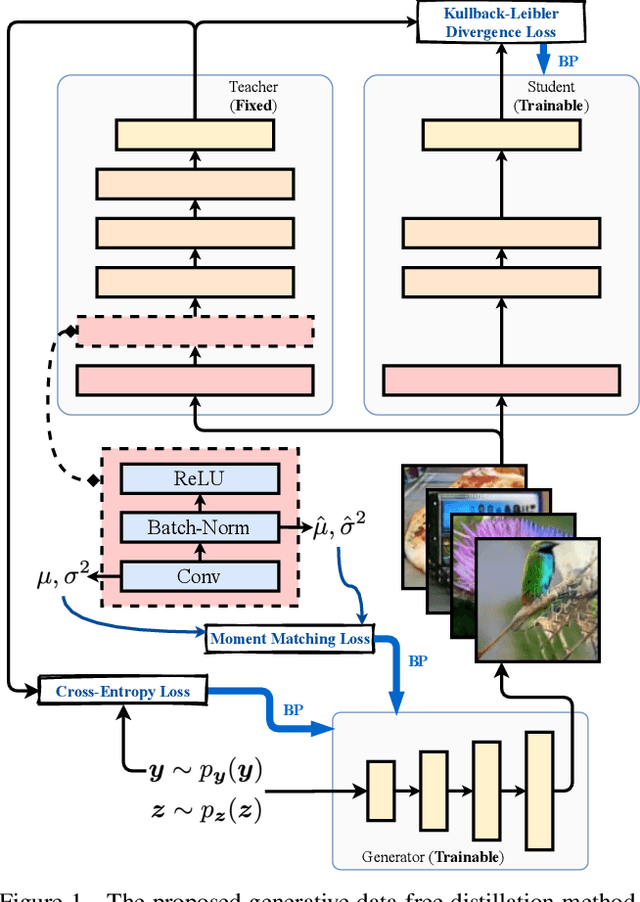
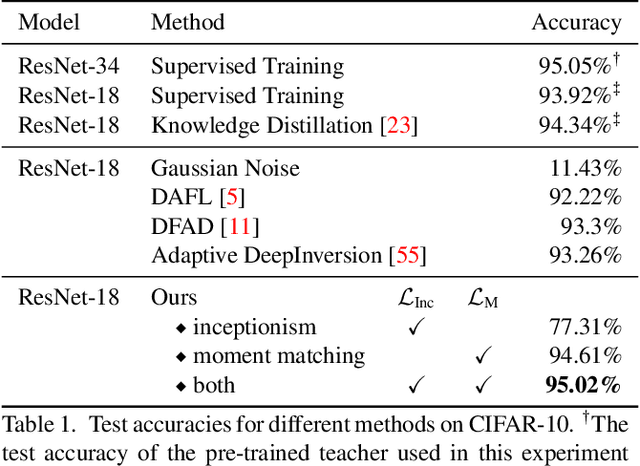

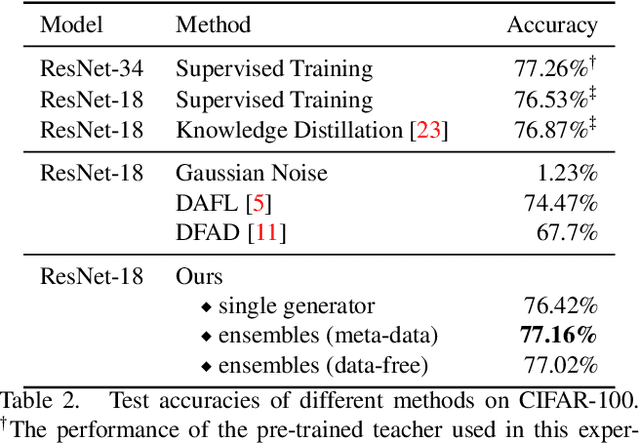
Knowledge distillation is one of the most popular and effective techniques for knowledge transfer, model compression and semi-supervised learning. Most existing distillation approaches require the access to original or augmented training samples. But this can be problematic in practice due to privacy, proprietary and availability concerns. Recent work has put forward some methods to tackle this problem, but they are either highly time-consuming or unable to scale to large datasets. To this end, we propose a new method to train a generative image model by leveraging the intrinsic normalization layers' statistics of the trained teacher network. This enables us to build an ensemble of generators without training data that can efficiently produce substitute inputs for subsequent distillation. The proposed method pushes forward the data-free distillation performance on CIFAR-10 and CIFAR-100 to 95.02% and 77.02% respectively. Furthermore, we are able to scale it to ImageNet dataset, which to the best of our knowledge, has never been done using generative models in a data-free setting.