 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Gap Between Object Detection and User Intent via Query-Modulation
Jun 18, 2021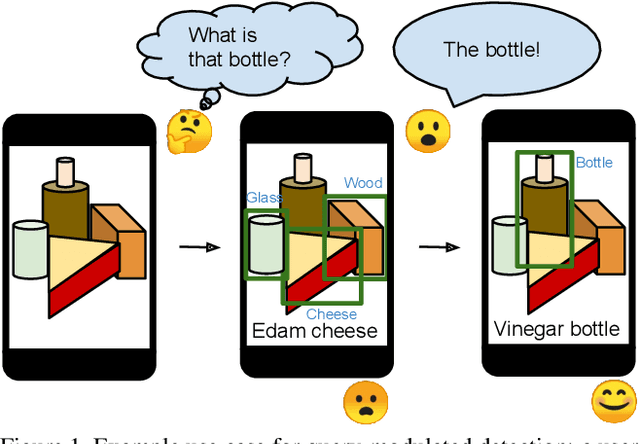

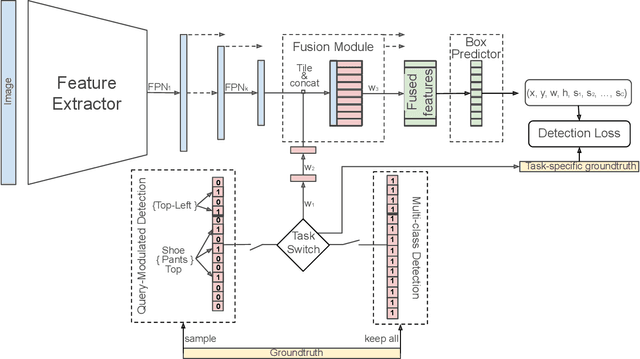
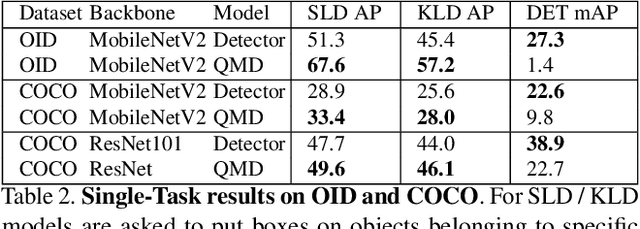
When interacting with objects through cameras, or pictures, users often have a specific intent. For example, they may want to perform a visual search. However, most object detection models ignore the user intent, relying on image pixels as their only input. This often leads to incorrect results, such as lack of a high-confidence detection on the object of interest, or detection with a wrong class label. In this paper we investigate techniques to modulate standard object detectors to explicitly account for the user intent, expressed as an embedding of a simple query. Compared to standard object detectors, query-modulated detectors show superior performance at detecting objects for a given label of interest. Thanks to large-scale training data synthesized from standard object detection annotations, query-modulated detectors can also outperform specialized referring expression recognition systems. Furthermore, they can be simultaneously trained to solve for both query-modulated detection and standard object detection.