 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Training of Neural Networks at Arbitrary Precision and Sparsity
Sep 14, 2024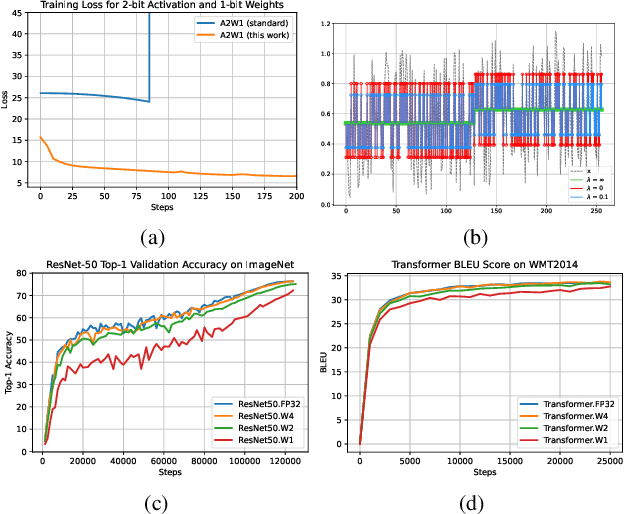

The discontinuous operations inherent in quantization and sparsification introduce obstacles to backpropagation. This is particularly challenging when training deep neural networks in ultra-low precision and sparse regimes. We propose a novel, robust, and universal solution: a denoising affine transform that stabilizes training under these challenging conditions. By formulating quantization and sparsification as perturbations during training, we derive a perturbation-resilient approach based on ridge regression. Our solution employs a piecewise constant backbone model to ensure a performance lower bound and features an inherent noise reduction mechanism to mitigate perturbation-induced corruption. This formulation allows existing models to be trained at arbitrarily low precision and sparsity levels with off-the-shelf recipes. Furthermore, our method provides a novel perspective on training temporal binary neural networks, contributing to ongoing efforts to narrow the gap between artificial and biological neural networks.
Custom Gradient Estimators are Straight-Through Estimators in Disguise
May 08, 2024Quantization-aware training comes with a fundamental challenge: the derivative of quantization functions such as rounding are zero almost everywhere and nonexistent elsewhere. Various differentiable approximations of quantization functions have been proposed to address this issue. In this paper, we prove that when the learning rate is sufficiently small, a large class of weight gradient estimators is equivalent with the straight through estimator (STE). Specifically, after swapping in the STE and adjusting both the weight initialization and the learning rate in SGD, the model will train in almost exactly the same way as it did with the original gradient estimator. Moreover, we show that for adaptive learning rate algorithms like Adam, the same result can be seen without any modifications to the weight initialization and learning rate. We experimentally show that these results hold for both a small convolutional model trained on the MNIST dataset and for a ResNet50 model trained on ImageNet.
MobileNetV4 -- Universal Models for the Mobile Ecosystem
Apr 16, 2024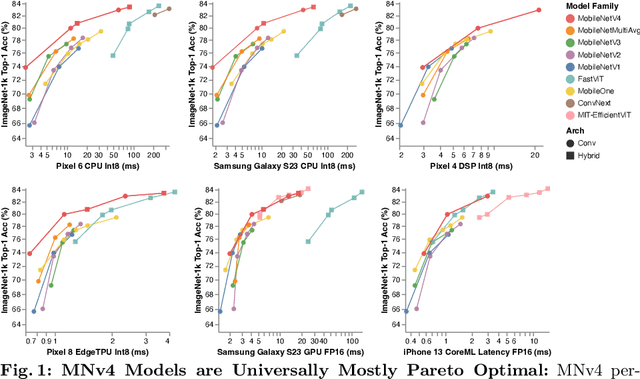
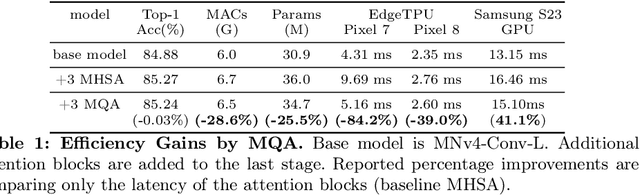
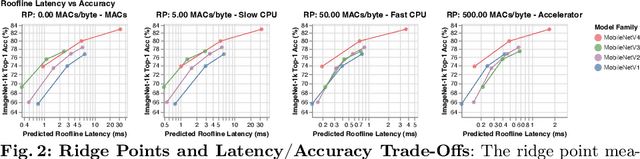
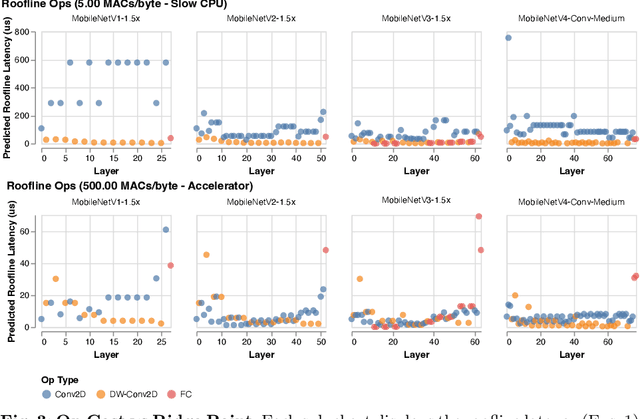
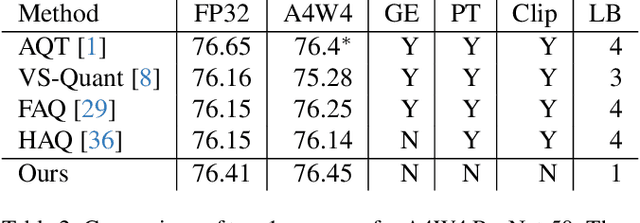
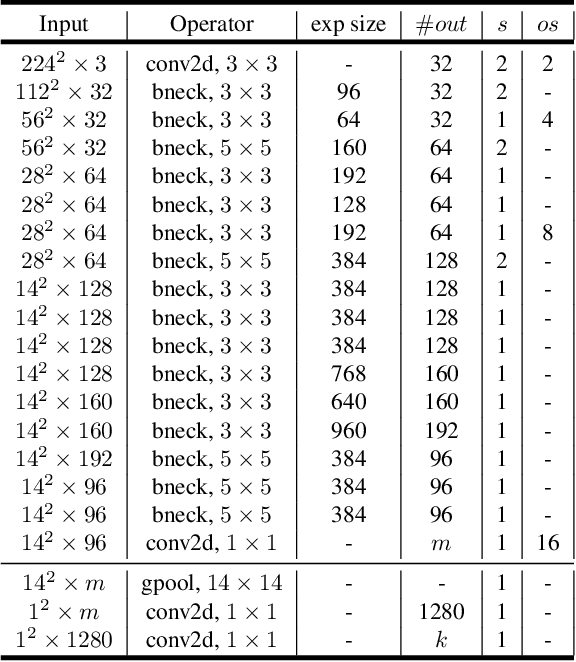
We present the latest generation of MobileNets, known as MobileNetV4 (MNv4), featuring universally efficient architecture designs for mobile devices. At its core, we introduce the Universal Inverted Bottleneck (UIB) search block, a unified and flexible structure that merges Inverted Bottleneck (IB), ConvNext, Feed Forward Network (FFN), and a novel Extra Depthwise (ExtraDW) variant. Alongside UIB, we present Mobile MQA, an attention block tailored for mobile accelerators, delivering a significant 39% speedup. An optimized neural architecture search (NAS) recipe is also introduced which improves MNv4 search effectiveness. The integration of UIB, Mobile MQA and the refined NAS recipe results in a new suite of MNv4 models that are mostly Pareto optimal across mobile CPUs, DSPs, GPUs, as well as specialized accelerators like Apple Neural Engine and Google Pixel EdgeTPU - a characteristic not found in any other models tested. Finally, to further boost accuracy, we introduce a novel distillation technique. Enhanced by this technique, our MNv4-Hybrid-Large model delivers 87% ImageNet-1K accuracy, with a Pixel 8 EdgeTPU runtime of just 3.8ms.
ReMaX: Relaxing for Better Training on Efficient Panoptic Segmentation
Jun 29, 2023



This paper presents a new mechanism to facilitate the training of mask transformers for efficient panoptic segmentation, democratizing its deployment. We observe that due to its high complexity, the training objective of panoptic segmentation will inevitably lead to much higher false positive penalization. Such unbalanced loss makes the training process of the end-to-end mask-transformer based architectures difficult, especially for efficient models. In this paper, we present ReMaX that adds relaxation to mask predictions and class predictions during training for panoptic segmentation. We demonstrate that via these simple relaxation techniques during training, our model can be consistently improved by a clear margin \textbf{without} any extra computational cost on inference. By combining our method with efficient backbones like MobileNetV3-Small, our method achieves new state-of-the-art results for efficient panoptic segmentation on COCO, ADE20K and Cityscapes. Code and pre-trained checkpoints will be available at \url{https://github.com/google-research/deeplab2}.
On Label Granularity and Object Localization
Jul 20, 2022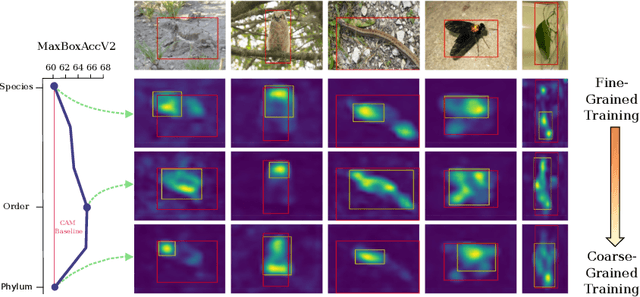

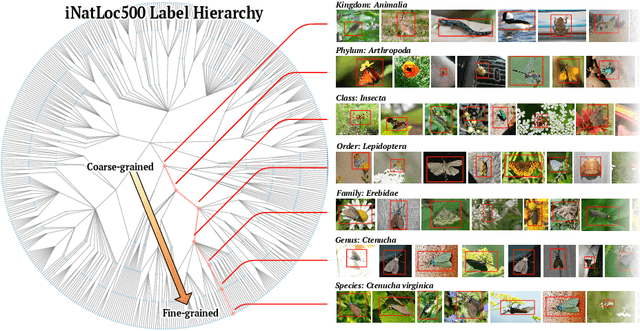
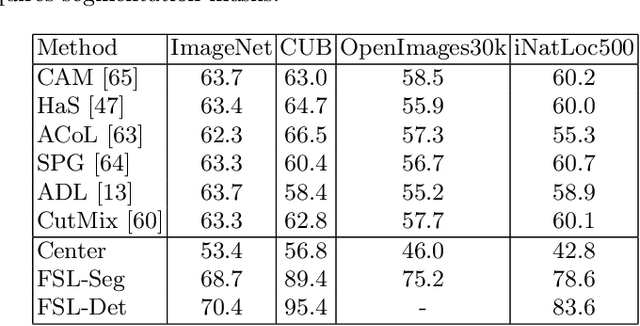
Weakly supervised object localization (WSOL) aims to learn representations that encode object location using only image-level category labels. However, many objects can be labeled at different levels of granularity. Is it an animal, a bird, or a great horned owl? Which image-level labels should we use? In this paper we study the role of label granularity in WSOL. To facilitate this investigation we introduce iNatLoc500, a new large-scale fine-grained benchmark dataset for WSOL. Surprisingly, we find that choosing the right training label granularity provides a much larger performance boost than choosing the best WSOL algorithm. We also show that changing the label granularity can significantly improve data efficiency.
MOSAIC: Mobile Segmentation via decoding Aggregated Information and encoded Context
Dec 22, 2021
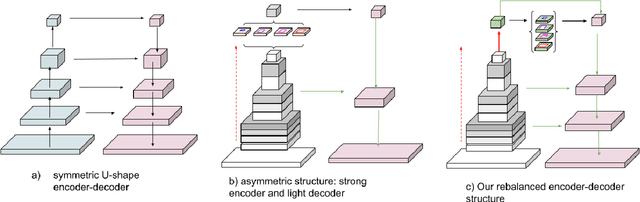
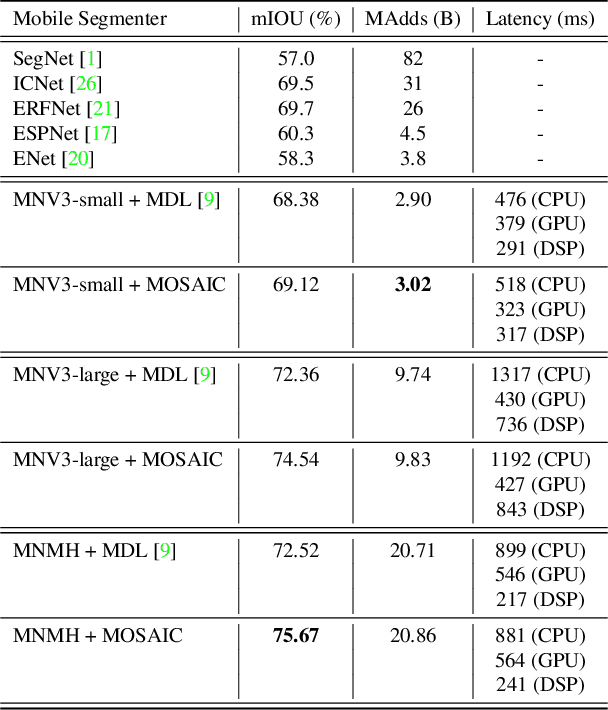
We present a next-generation neural network architecture, MOSAIC, for efficient and accurate semantic image segmentation on mobile devices. MOSAIC is designed using commonly supported neural operations by diverse mobile hardware platforms for flexible deployment across various mobile platforms. With a simple asymmetric encoder-decoder structure which consists of an efficient multi-scale context encoder and a light-weight hybrid decoder to recover spatial details from aggregated information, MOSAIC achieves new state-of-the-art performance while balancing accuracy and computational cost. Deployed on top of a tailored feature extraction backbone based on a searched classification network, MOSAIC achieves a 5% absolute accuracy gain surpassing the current industry standard MLPerf models and state-of-the-art architectures.
Bridging the Gap Between Object Detection and User Intent via Query-Modulation
Jun 18, 2021

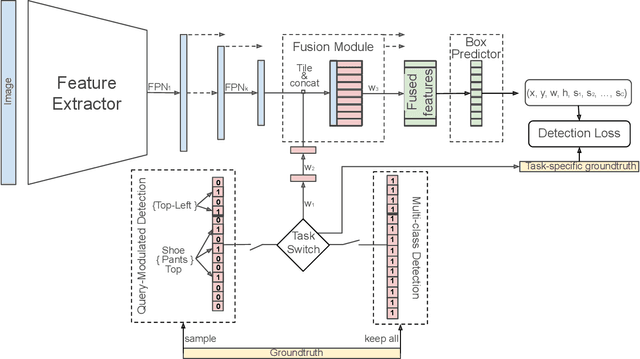
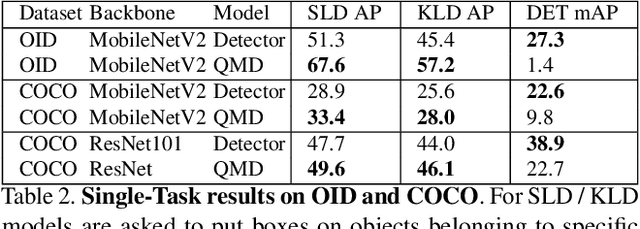
When interacting with objects through cameras, or pictures, users often have a specific intent. For example, they may want to perform a visual search. However, most object detection models ignore the user intent, relying on image pixels as their only input. This often leads to incorrect results, such as lack of a high-confidence detection on the object of interest, or detection with a wrong class label. In this paper we investigate techniques to modulate standard object detectors to explicitly account for the user intent, expressed as an embedding of a simple query. Compared to standard object detectors, query-modulated detectors show superior performance at detecting objects for a given label of interest. Thanks to large-scale training data synthesized from standard object detection annotations, query-modulated detectors can also outperform specialized referring expression recognition systems. Furthermore, they can be simultaneously trained to solve for both query-modulated detection and standard object detection.
BasisNet: Two-stage Model Synthesis for Efficient Inference
May 07, 2021
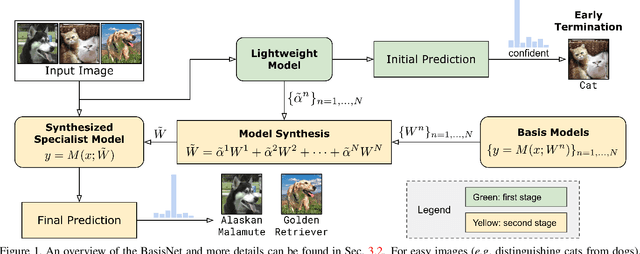

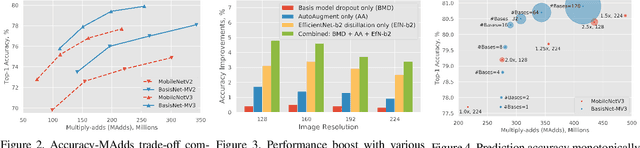
In this work, we present BasisNet which combines recent advancements in efficient neural network architectures, conditional computation, and early termination in a simple new form. Our approach incorporates a lightweight model to preview the input and generate input-dependent combination coefficients, which later controls the synthesis of a more accurate specialist model to make final prediction. The two-stage model synthesis strategy can be applied to any network architectures and both stages are jointly trained. We also show that proper training recipes are critical for increasing generalizability for such high capacity neural networks. On ImageNet classification benchmark, our BasisNet with MobileNets as backbone demonstrated clear advantage on accuracy-efficiency trade-off over several strong baselines. Specifically, BasisNet-MobileNetV3 obtained 80.3% top-1 accuracy with only 290M Multiply-Add operations, halving the computational cost of previous state-of-the-art without sacrificing accuracy. With early termination, the average cost can be further reduced to 198M MAdds while maintaining accuracy of 80.0% on ImageNet.
SpotPatch: Parameter-Efficient Transfer Learning for Mobile Object Detection
Jan 04, 2021
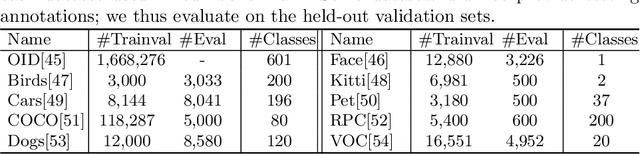
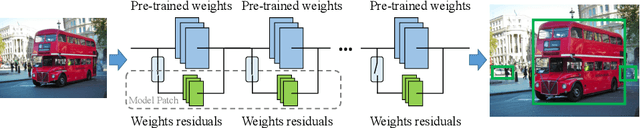
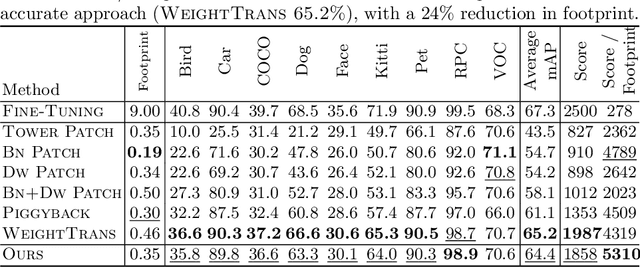
Deep learning based object detectors are commonly deployed on mobile devices to solve a variety of tasks. For maximum accuracy, each detector is usually trained to solve one single specific task, and comes with a completely independent set of parameters. While this guarantees high performance, it is also highly inefficient, as each model has to be separately downloaded and stored. In this paper we address the question: can task-specific detectors be trained and represented as a shared set of weights, plus a very small set of additional weights for each task? The main contributions of this paper are the following: 1) we perform the first systematic study of parameter-efficient transfer learning techniques for object detection problems; 2) we propose a technique to learn a model patch with a size that is dependent on the difficulty of the task to be learned, and validate our approach on 10 different object detection tasks. Our approach achieves similar accuracy as previously proposed approaches, while being significantly more compact.
Large-Scale Generative Data-Free Distillation
Dec 10, 2020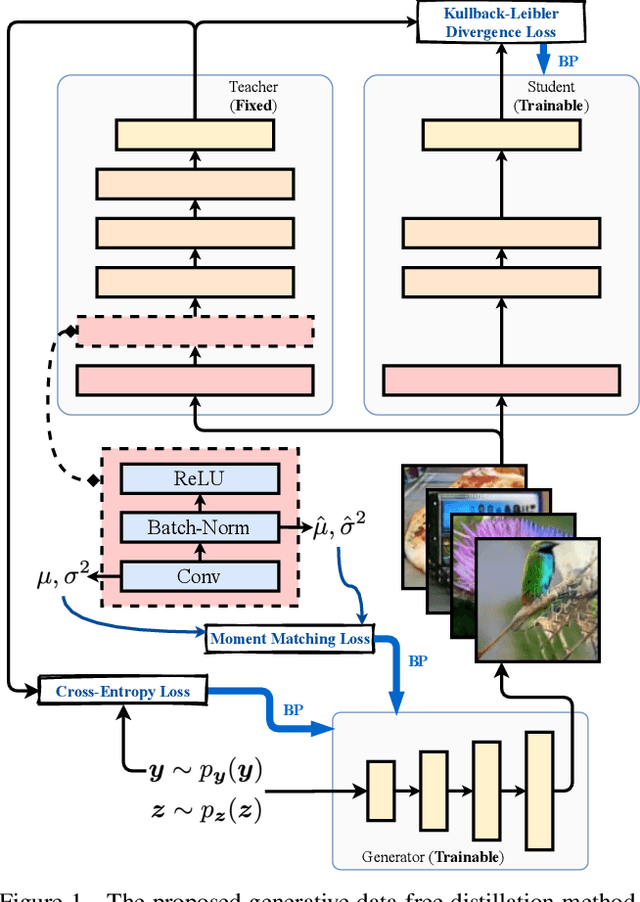
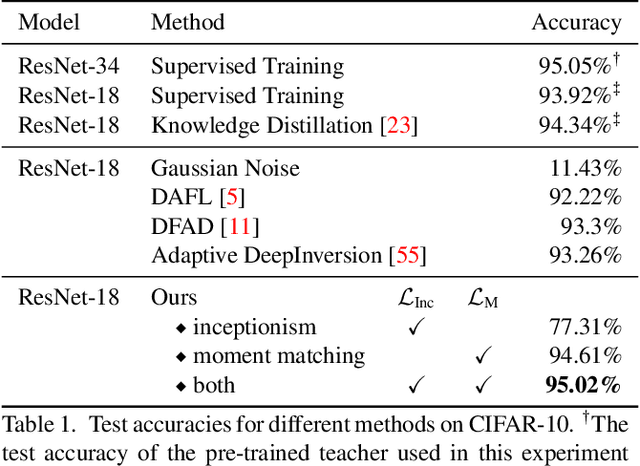

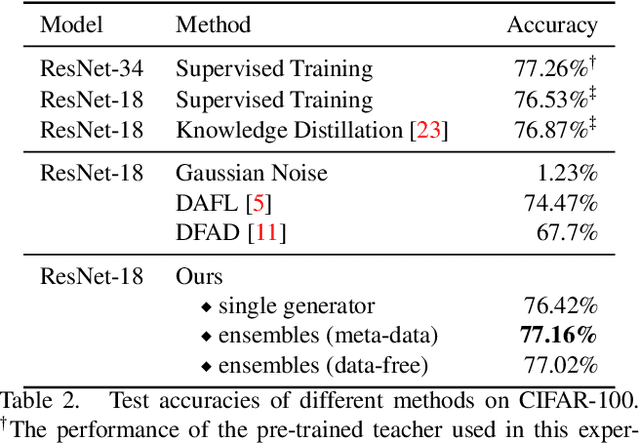
Knowledge distillation is one of the most popular and effective techniques for knowledge transfer, model compression and semi-supervised learning. Most existing distillation approaches require the access to original or augmented training samples. But this can be problematic in practice due to privacy, proprietary and availability concerns. Recent work has put forward some methods to tackle this problem, but they are either highly time-consuming or unable to scale to large datasets. To this end, we propose a new method to train a generative image model by leveraging the intrinsic normalization layers' statistics of the trained teacher network. This enables us to build an ensemble of generators without training data that can efficiently produce substitute inputs for subsequent distillation. The proposed method pushes forward the data-free distillation performance on CIFAR-10 and CIFAR-100 to 95.02% and 77.02% respectively. Furthermore, we are able to scale it to ImageNet dataset, which to the best of our knowledge, has never been done using generative models in a data-free setting.