 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobileNetV4 -- Universal Models for the Mobile Ecosystem
Apr 16, 2024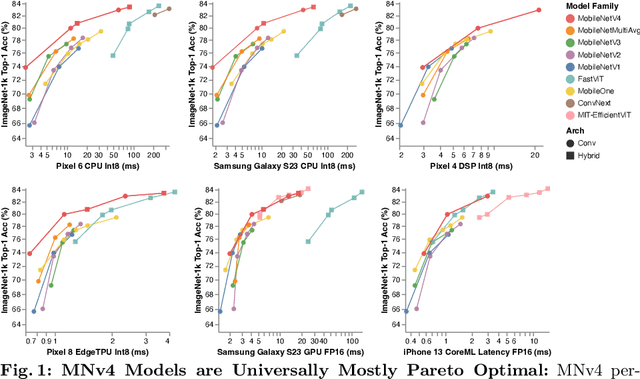
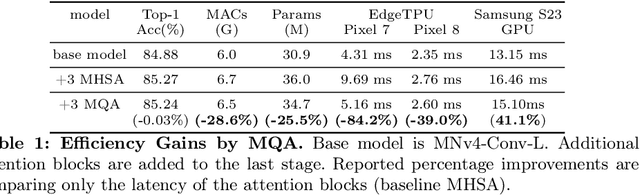
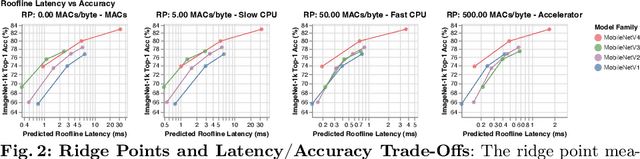
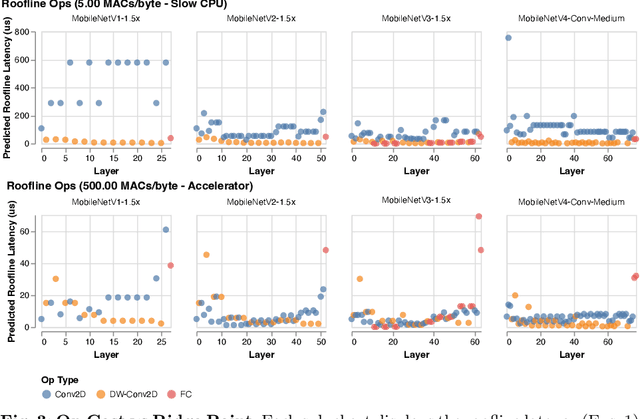
We present the latest generation of MobileNets, known as MobileNetV4 (MNv4), featuring universally efficient architecture designs for mobile devices. At its core, we introduce the Universal Inverted Bottleneck (UIB) search block, a unified and flexible structure that merges Inverted Bottleneck (IB), ConvNext, Feed Forward Network (FFN), and a novel Extra Depthwise (ExtraDW) variant. Alongside UIB, we present Mobile MQA, an attention block tailored for mobile accelerators, delivering a significant 39% speedup. An optimized neural architecture search (NAS) recipe is also introduced which improves MNv4 search effectiveness. The integration of UIB, Mobile MQA and the refined NAS recipe results in a new suite of MNv4 models that are mostly Pareto optimal across mobile CPUs, DSPs, GPUs, as well as specialized accelerators like Apple Neural Engine and Google Pixel EdgeTPU - a characteristic not found in any other models tested. Finally, to further boost accuracy, we introduce a novel distillation technique. Enhanced by this technique, our MNv4-Hybrid-Large model delivers 87% ImageNet-1K accuracy, with a Pixel 8 EdgeTPU runtime of just 3.8ms.
Improving Object Detection with Selective Self-supervised Self-training
Jul 24, 2020
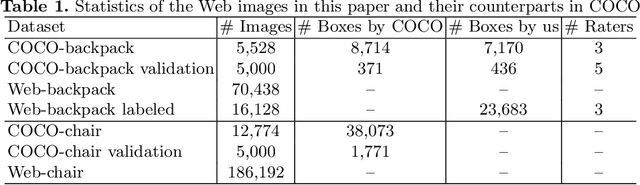


We study how to leverage Web images to augment human-curated object detection datasets. Our approach is two-pronged. On the one hand, we retrieve Web images by image-to-image search, which incurs less domain shift from the curated data than other search methods. The Web images are diverse, supplying a wide variety of object poses, appearances, their interactions with the context, etc. On the other hand, we propose a novel learning method motivated by two parallel lines of work that explore unlabeled data for image classification: self-training and self-supervised learning. They fail to improve object detectors in their vanilla forms due to the domain gap between the Web images and curated datasets. To tackle this challenge, we propose a selective net to rectify the supervision signals in Web images. It not only identifies positive bounding boxes but also creates a safe zone for mining hard negative boxes. We report state-of-the-art results on detecting backpacks and chairs from everyday scenes, along with other challenging object classes.
Cap2Det: Learning to Amplify Weak Caption Supervision for Object Detection
Aug 16, 2019
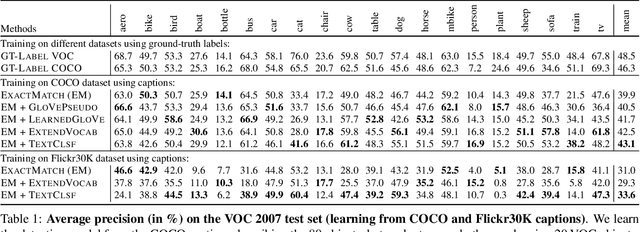

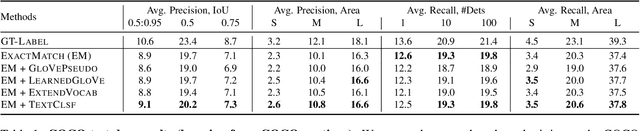
Learning to localize and name object instances is a fundamental problem in vision, but state-of-the-art approaches rely on expensive bounding box supervision. While weakly supervised detection (WSOD) methods relax the need for boxes to that of image-level annotations, even cheaper supervision is naturally available in the form of unstructured textual descriptions that users may freely provide when uploading image content. However, straightforward approaches to using such data for WSOD wastefully discard captions that do not exactly match object names. Instead, we show how to squeeze the most information out of these captions by training a text-only classifier that generalizes beyond dataset boundaries. Our discovery provides an opportunity for learning detection models from noisy but more abundant and freely-available caption data. We also validate our model on three classic object detection benchmarks and achieve state-of-the-art WSOD performance. Our code is available at https://github.com/yekeren/Cap2Det.
Learning to discover and localize visual objects with open vocabulary
Nov 25, 2018

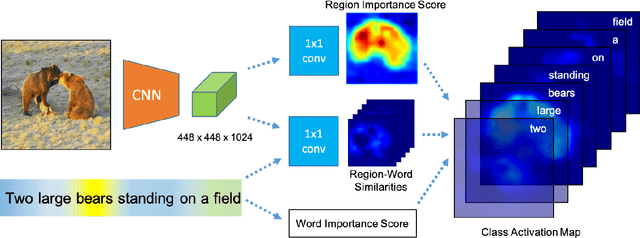

To alleviate the cost of obtaining accurate bounding boxes for training today's state-of-the-art object detection models, recent weakly supervised detection work has proposed techniques to learn from image-level labels. However, requiring discrete image-level labels is both restrictive and suboptimal. Real-world "supervision" usually consists of more unstructured text, such as captions. In this work we learn association maps between images and captions. We then use a novel objectness criterion to rank the resulting candidate boxes, such that high-ranking boxes have strong gradients along all edges. Thus, we can detect objects beyond a fixed object category vocabulary, if those objects are frequent and distinctive enough. We show that our objectness criterion improves the proposed bounding boxes in relation to prior weakly supervised detection methods. Further, we show encouraging results on object detection from image-level captions only.