 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Consistent Temporal Grounding between Related Tasks in Sports Coaching
Mar 19, 2026Video-LLMs often attend to irrelevant frames, which is especially detrimental for sports coaching tasks requiring precise temporal grounding. Yet obtaining frame-level supervision is challenging: expensive to collect from humans and unreliable from other models. We improve temporal grounding without additional annotations by exploiting the observation that related tasks, such as generation and verification, must attend to the same frames. We enforce this via a self-consistency objective over select visual attention maps of tightly-related tasks. Using VidDiffBench, which provides ground-truth keyframe annotations, we first validate that attention misallocation is a significant bottleneck. We then show that training with our objective yields gains of +3.0%, +14.1% accuracy and +0.9 BERTScore over supervised finetuning across three sports coaching tasks: Exact, FitnessQA, and ExpertAF, even surpassing closed-source models.
Generalizing Sports Feedback Generation by Watching Competitions and Reading Books: A Rock Climbing Case Study
Feb 09, 2026While there is rapid progress in video-LLMs with advanced reasoning capabilities, prior work shows that these models struggle on the challenging task of sports feedback generation and require expensive and difficult-to-collect finetuning feedback data for each sport. This limitation is evident from the poor generalization to sports unseen during finetuning. Furthermore, traditional text generation evaluation metrics (e.g., BLEU-4, METEOR, ROUGE-L, BERTScore), originally developed for machine translation and summarization, fail to capture the unique aspects of sports feedback quality. To address the first problem, using rock climbing as our case study, we propose using auxiliary freely-available web data from the target domain, such as competition videos and coaching manuals, in addition to existing sports feedback from a disjoint, source domain to improve sports feedback generation performance on the target domain. To improve evaluation, we propose two evaluation metrics: (1) specificity and (2) actionability. Together, our approach enables more meaningful and practical generation of sports feedback under limited annotations.
Culture in Action: Evaluating Text-to-Image Models through Social Activities
Nov 07, 2025Text-to-image (T2I) diffusion models achieve impressive photorealism by training on large-scale web data, but models inherit cultural biases and fail to depict underrepresented regions faithfully. Existing cultural benchmarks focus mainly on object-centric categories (e.g., food, attire, and architecture), overlooking the social and daily activities that more clearly reflect cultural norms. Few metrics exist for measuring cultural faithfulness. We introduce CULTIVate, a benchmark for evaluating T2I models on cross-cultural activities (e.g., greetings, dining, games, traditional dances, and cultural celebrations). CULTIVate spans 16 countries with 576 prompts and more than 19,000 images, and provides an explainable descriptor-based evaluation framework across multiple cultural dimensions, including background, attire, objects, and interactions. We propose four metrics to measure cultural alignment, hallucination, exaggerated elements, and diversity. Our findings reveal systematic disparities: models perform better for global north countries than for the global south, with distinct failure modes across T2I systems. Human studies confirm that our metrics correlate more strongly with human judgments than existing text-image metrics.
A Multimodal Recaptioning Framework to Account for Perceptual Diversity in Multilingual Vision-Language Modeling
Apr 19, 2025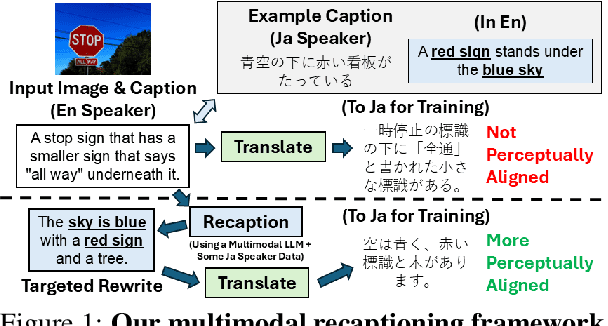
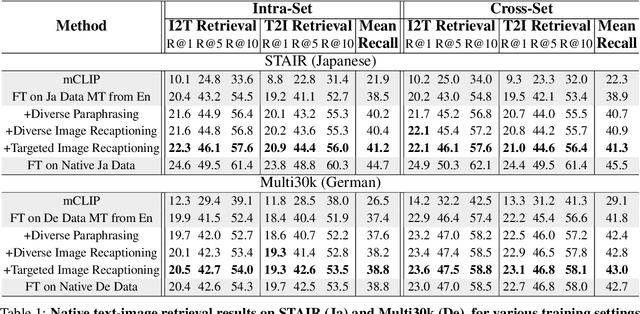


There are many ways to describe, name, and group objects when captioning an image. Differences are evident when speakers come from diverse cultures due to the unique experiences that shape perception. Machine translation of captions has pushed multilingual capabilities in vision-language models (VLMs), but data comes mainly from English speakers, indicating a perceptual bias and lack of model flexibility. In this work, we address this challenge and outline a data-efficient framework to instill multilingual VLMs with greater understanding of perceptual diversity. We specifically propose an LLM-based, multimodal recaptioning strategy that alters the object descriptions of English captions before translation. The greatest benefits are demonstrated in a targeted multimodal mechanism guided by native speaker data. By adding produced rewrites as augmentations in training, we improve on German and Japanese text-image retrieval cases studies (up to +3.5 mean recall overall, +4.7 on non-native error cases). We further propose a mechanism to analyze the specific object description differences across datasets, and we offer insights into cross-dataset and cross-language generalization.
Investigating and Improving Counter-Stereotypical Action Relation in Text-to-Image Diffusion Models
Mar 13, 2025Text-to-image diffusion models consistently fail at generating counter-stereotypical action relationships (e.g., "mouse chasing cat"), defaulting to frequent stereotypes even when explicitly prompted otherwise. Through systematic investigation, we discover this limitation stems from distributional biases rather than inherent model constraints. Our key insight reveals that while models fail on rare compositions when their inversions are common, they can successfully generate similar intermediate compositions (e.g., "mouse chasing boy"). To test this hypothesis, we develop a Role-Bridging Decomposition framework that leverages these intermediates to gradually teach rare relationships without architectural modifications. We introduce ActionBench, a comprehensive benchmark specifically designed to evaluate action-based relationship generation across stereotypical and counter-stereotypical configurations. Our experiments validate that intermediate compositions indeed facilitate counter-stereotypical generation, with both automatic metrics and human evaluations showing significant improvements over existing approaches. This work not only identifies fundamental biases in current text-to-image systems but demonstrates a promising direction for addressing them through compositional reasoning.
Towards Generalization of Tactile Image Generation: Reference-Free Evaluation in a Leakage-Free Setting
Mar 10, 2025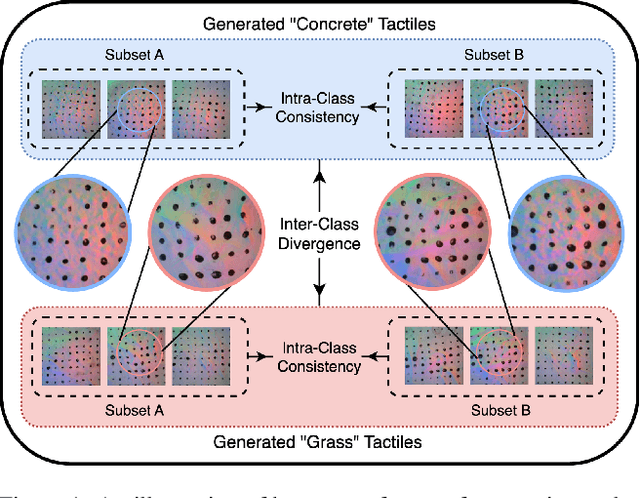
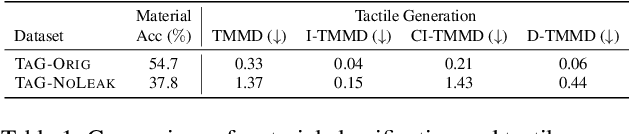
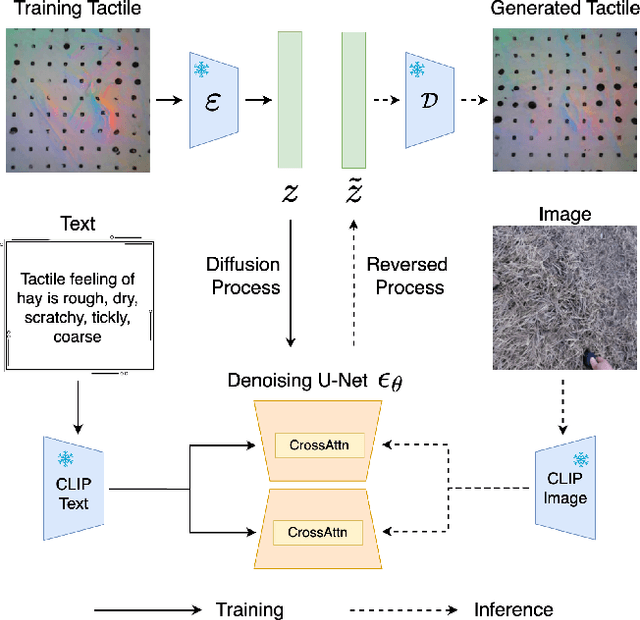

Tactile sensing, which relies on direct physical contact, is critical for human perception and underpins applications in computer vision, robotics, and multimodal learning. Because tactile data is often scarce and costly to acquire, generating synthetic tactile images provides a scalable solution to augment real-world measurements. However, ensuring robust generalization in synthesizing tactile images-capturing subtle, material-specific contact features-remains challenging. We demonstrate that overlapping training and test samples in commonly used datasets inflate performance metrics, obscuring the true generalizability of tactile models. To address this, we propose a leakage-free evaluation protocol coupled with novel, reference-free metrics-TMMD, I-TMMD, CI-TMMD, and D-TMMD-tailored for tactile generation. Moreover, we propose a vision-to-touch generation method that leverages text as an intermediate modality by incorporating concise, material-specific descriptions during training to better capture essential tactile features. Experiments on two popular visuo-tactile datasets, Touch and Go and HCT, show that our approach achieves superior performance and enhanced generalization in a leakage-free setting.
CAP: Evaluation of Persuasive and Creative Image Generation
Dec 10, 2024
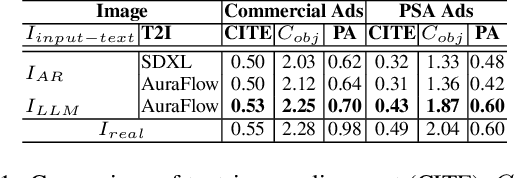
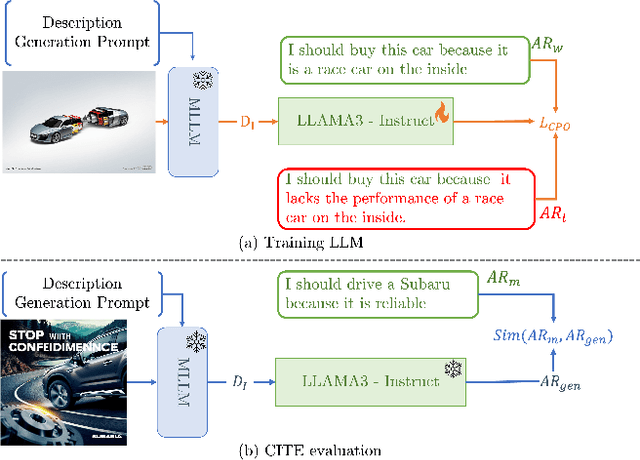
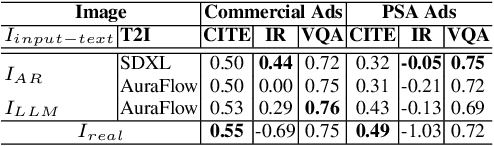
We address the task of advertisement image generation and introduce three evaluation metrics to assess Creativity, prompt Alignment, and Persuasiveness (CAP) in generated advertisement images. Despite recent advancements in Text-to-Image (T2I) generation and their performance in generating high-quality images for explicit descriptions, evaluating these models remains challenging. Existing evaluation methods focus largely on assessing alignment with explicit, detailed descriptions, but evaluating alignment with visually implicit prompts remains an open problem. Additionally, creativity and persuasiveness are essential qualities that enhance the effectiveness of advertisement images, yet are seldom measured. To address this, we propose three novel metrics for evaluating the creativity, alignment, and persuasiveness of generated images. Our findings reveal that current T2I models struggle with creativity, persuasiveness, and alignment when the input text is implicit messages. We further introduce a simple yet effective approach to enhance T2I models' capabilities in producing images that are better aligned, more creative, and more persuasive.
Quantifying the Gaps Between Translation and Native Perception in Training for Multimodal, Multilingual Retrieval
Oct 02, 2024

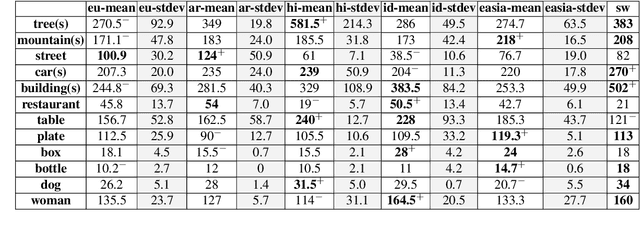
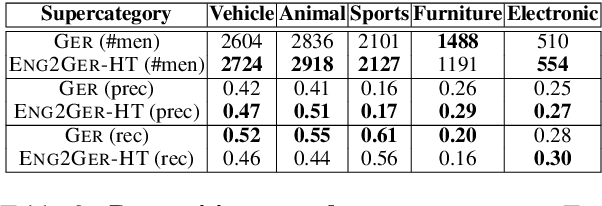
There is a scarcity of multilingual vision-language models that properly account for the perceptual differences that are reflected in image captions across languages and cultures. In this work, through a multimodal, multilingual retrieval case study, we quantify the existing lack of model flexibility. We empirically show performance gaps between training on captions that come from native German perception and captions that have been either machine-translated or human-translated from English into German. To address these gaps, we further propose and evaluate caption augmentation strategies. While we achieve mean recall improvements (+1.3), gaps still remain, indicating an open area of future work for the community.
Benchmarking VLMs' Reasoning About Persuasive Atypical Images
Sep 16, 2024



Vision language models (VLMs) have shown strong zero-shot generalization across various tasks, especially when integrated with large language models (LLMs). However, their ability to comprehend rhetorical and persuasive visual media, such as advertisements, remains understudied. Ads often employ atypical imagery, using surprising object juxtapositions to convey shared properties. For example, Fig. 1 (e) shows a beer with a feather-like texture. This requires advanced reasoning to deduce that this atypical representation signifies the beer's lightness. We introduce three novel tasks, Multi-label Atypicality Classification, Atypicality Statement Retrieval, and Aypical Object Recognition, to benchmark VLMs' understanding of atypicality in persuasive images. We evaluate how well VLMs use atypicality to infer an ad's message and test their reasoning abilities by employing semantically challenging negatives. Finally, we pioneer atypicality-aware verbalization by extracting comprehensive image descriptions sensitive to atypical elements. Our findings reveal that: (1) VLMs lack advanced reasoning capabilities compared to LLMs; (2) simple, effective strategies can extract atypicality-aware information, leading to comprehensive image verbalization; (3) atypicality aids persuasive advertisement understanding. Code and data will be made available.
Enhancing Weakly-Supervised Object Detection on Static Images through (Hallucinated) Motion
Sep 15, 2024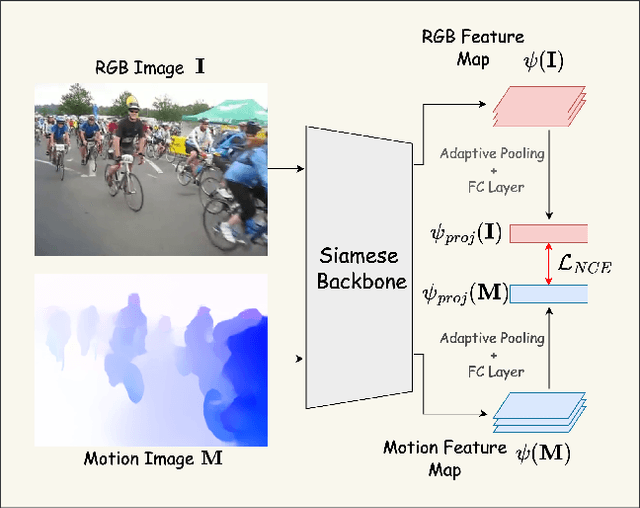
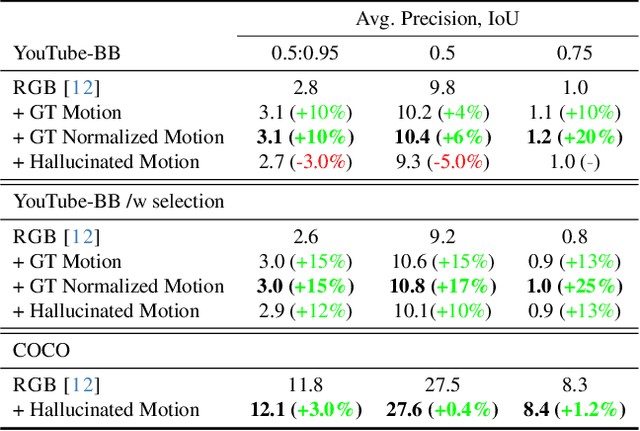


While motion has garnered attention in various tasks, its potential as a modality for weakly-supervised object detection (WSOD) in static images remains unexplored. Our study introduces an approach to enhance WSOD methods by integrating motion information. This method involves leveraging hallucinated motion from static images to improve WSOD on image datasets, utilizing a Siamese network for enhanced representation learning with motion, addressing camera motion through motion normalization, and selectively training images based on object motion. Experimental validation on the COCO and YouTube-BB datasets demonstrates improvements over a state-of-the-art method.