 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCulture in Action: Evaluating Text-to-Image Models through Social Activities
Nov 07, 2025Text-to-image (T2I) diffusion models achieve impressive photorealism by training on large-scale web data, but models inherit cultural biases and fail to depict underrepresented regions faithfully. Existing cultural benchmarks focus mainly on object-centric categories (e.g., food, attire, and architecture), overlooking the social and daily activities that more clearly reflect cultural norms. Few metrics exist for measuring cultural faithfulness. We introduce CULTIVate, a benchmark for evaluating T2I models on cross-cultural activities (e.g., greetings, dining, games, traditional dances, and cultural celebrations). CULTIVate spans 16 countries with 576 prompts and more than 19,000 images, and provides an explainable descriptor-based evaluation framework across multiple cultural dimensions, including background, attire, objects, and interactions. We propose four metrics to measure cultural alignment, hallucination, exaggerated elements, and diversity. Our findings reveal systematic disparities: models perform better for global north countries than for the global south, with distinct failure modes across T2I systems. Human studies confirm that our metrics correlate more strongly with human judgments than existing text-image metrics.
Investigating and Improving Counter-Stereotypical Action Relation in Text-to-Image Diffusion Models
Mar 13, 2025Text-to-image diffusion models consistently fail at generating counter-stereotypical action relationships (e.g., "mouse chasing cat"), defaulting to frequent stereotypes even when explicitly prompted otherwise. Through systematic investigation, we discover this limitation stems from distributional biases rather than inherent model constraints. Our key insight reveals that while models fail on rare compositions when their inversions are common, they can successfully generate similar intermediate compositions (e.g., "mouse chasing boy"). To test this hypothesis, we develop a Role-Bridging Decomposition framework that leverages these intermediates to gradually teach rare relationships without architectural modifications. We introduce ActionBench, a comprehensive benchmark specifically designed to evaluate action-based relationship generation across stereotypical and counter-stereotypical configurations. Our experiments validate that intermediate compositions indeed facilitate counter-stereotypical generation, with both automatic metrics and human evaluations showing significant improvements over existing approaches. This work not only identifies fundamental biases in current text-to-image systems but demonstrates a promising direction for addressing them through compositional reasoning.
Benchmarking VLMs' Reasoning About Persuasive Atypical Images
Sep 16, 2024



Vision language models (VLMs) have shown strong zero-shot generalization across various tasks, especially when integrated with large language models (LLMs). However, their ability to comprehend rhetorical and persuasive visual media, such as advertisements, remains understudied. Ads often employ atypical imagery, using surprising object juxtapositions to convey shared properties. For example, Fig. 1 (e) shows a beer with a feather-like texture. This requires advanced reasoning to deduce that this atypical representation signifies the beer's lightness. We introduce three novel tasks, Multi-label Atypicality Classification, Atypicality Statement Retrieval, and Aypical Object Recognition, to benchmark VLMs' understanding of atypicality in persuasive images. We evaluate how well VLMs use atypicality to infer an ad's message and test their reasoning abilities by employing semantically challenging negatives. Finally, we pioneer atypicality-aware verbalization by extracting comprehensive image descriptions sensitive to atypical elements. Our findings reveal that: (1) VLMs lack advanced reasoning capabilities compared to LLMs; (2) simple, effective strategies can extract atypicality-aware information, leading to comprehensive image verbalization; (3) atypicality aids persuasive advertisement understanding. Code and data will be made available.
Incorporating Geo-Diverse Knowledge into Prompting for Increased Geographical Robustness in Object Recognition
Jan 03, 2024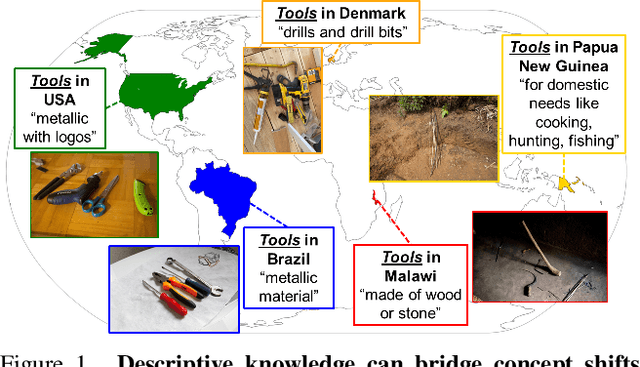
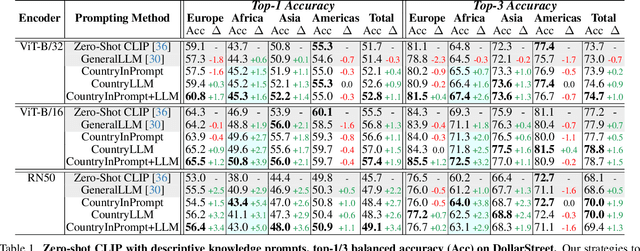
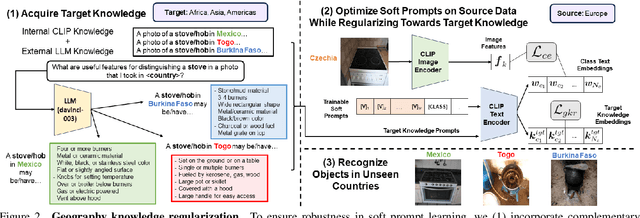
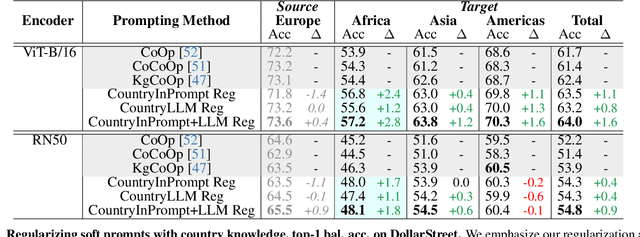
Existing object recognition models have been shown to lack robustness in diverse geographical scenarios due to significant domain shifts in design and context. Class representations need to be adapted to more accurately reflect an object concept under these shifts. In the absence of training data from target geographies, we hypothesize that geography-specific descriptive knowledge of object categories can be leveraged to enhance robustness. For this purpose, we explore the feasibility of probing a large-language model for geography-specific object knowledge, and we investigate integrating knowledge in zero-shot and learnable soft prompting with the CLIP vision-language model. In particular, we propose a geography knowledge regularization method to ensure that soft prompts trained on a source set of geographies generalize to an unseen target set of geographies. Our gains on DollarStreet when generalizing from a model trained only on data from Europe are as large as +2.8 on countries from Africa, and +4.6 on the hardest classes. We further show competitive performance vs. few-shot target training, and provide insights into how descriptive knowledge captures geographical differences.
Semi-Supervised Domain Generalization for Object Detection via Language-Guided Feature Alignment
Sep 24, 2023



Existing domain adaptation (DA) and generalization (DG) methods in object detection enforce feature alignment in the visual space but face challenges like object appearance variability and scene complexity, which make it difficult to distinguish between objects and achieve accurate detection. In this paper, we are the first to address the problem of semi-supervised domain generalization by exploring vision-language pre-training and enforcing feature alignment through the language space. We employ a novel Cross-Domain Descriptive Multi-Scale Learning (CDDMSL) aiming to maximize the agreement between descriptions of an image presented with different domain-specific characteristics in the embedding space. CDDMSL significantly outperforms existing methods, achieving 11.7% and 7.5% improvement in DG and DA settings, respectively. Comprehensive analysis and ablation studies confirm the effectiveness of our method, positioning CDDMSL as a promising approach for domain generalization in object detection tasks.