 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Geo-Diverse Knowledge into Prompting for Increased Geographical Robustness in Object Recognition
Paper and Code
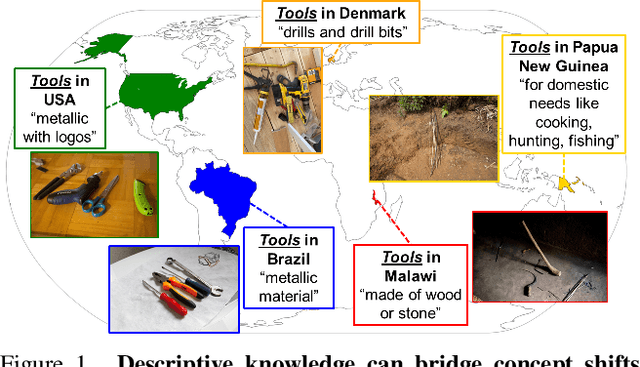
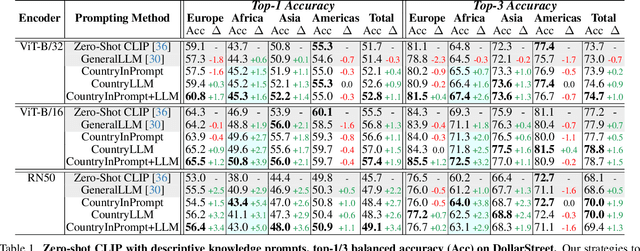
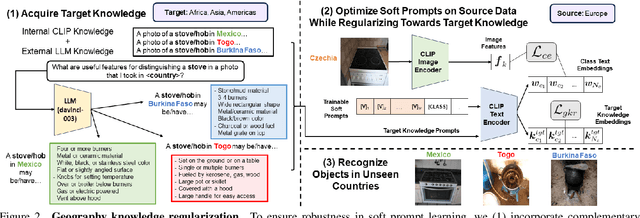
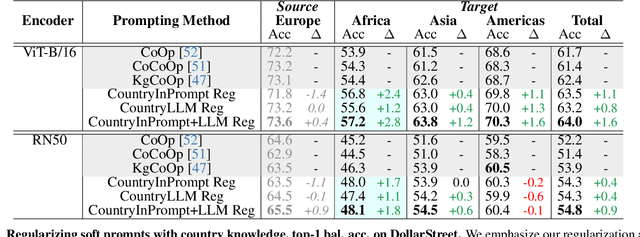
Existing object recognition models have been shown to lack robustness in diverse geographical scenarios due to significant domain shifts in design and context. Class representations need to be adapted to more accurately reflect an object concept under these shifts. In the absence of training data from target geographies, we hypothesize that geography-specific descriptive knowledge of object categories can be leveraged to enhance robustness. For this purpose, we explore the feasibility of probing a large-language model for geography-specific object knowledge, and we investigate integrating knowledge in zero-shot and learnable soft prompting with the CLIP vision-language model. In particular, we propose a geography knowledge regularization method to ensure that soft prompts trained on a source set of geographies generalize to an unseen target set of geographies. Our gains on DollarStreet when generalizing from a model trained only on data from Europe are as large as +2.8 on countries from Africa, and +4.6 on the hardest classes. We further show competitive performance vs. few-shot target training, and provide insights into how descriptive knowledge captures geographical differences.