 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal Recaptioning Framework to Account for Perceptual Diversity in Multilingual Vision-Language Modeling
Apr 19, 2025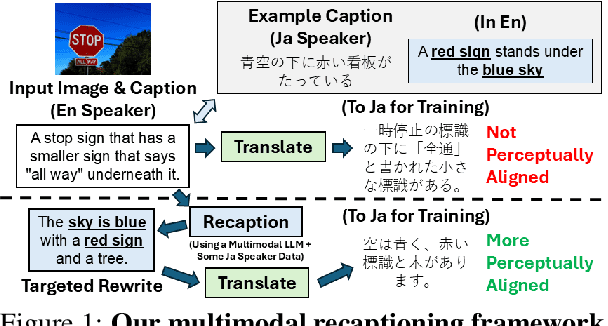


There are many ways to describe, name, and group objects when captioning an image. Differences are evident when speakers come from diverse cultures due to the unique experiences that shape perception. Machine translation of captions has pushed multilingual capabilities in vision-language models (VLMs), but data comes mainly from English speakers, indicating a perceptual bias and lack of model flexibility. In this work, we address this challenge and outline a data-efficient framework to instill multilingual VLMs with greater understanding of perceptual diversity. We specifically propose an LLM-based, multimodal recaptioning strategy that alters the object descriptions of English captions before translation. The greatest benefits are demonstrated in a targeted multimodal mechanism guided by native speaker data. By adding produced rewrites as augmentations in training, we improve on German and Japanese text-image retrieval cases studies (up to +3.5 mean recall overall, +4.7 on non-native error cases). We further propose a mechanism to analyze the specific object description differences across datasets, and we offer insights into cross-dataset and cross-language generalization.
Quantifying the Gaps Between Translation and Native Perception in Training for Multimodal, Multilingual Retrieval
Oct 02, 2024

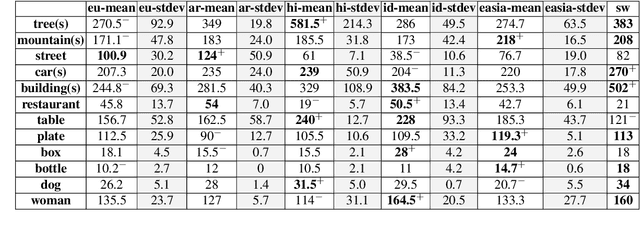
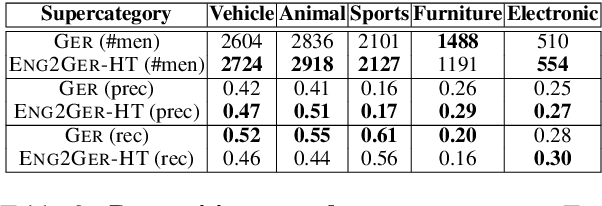
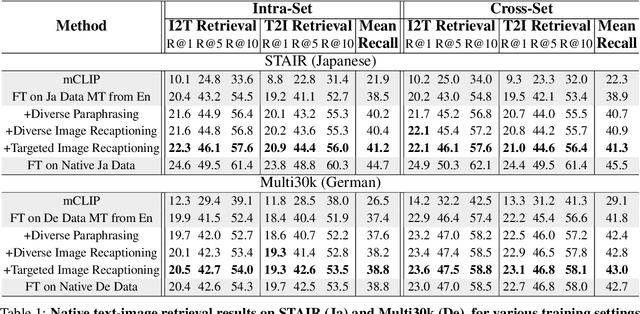
There is a scarcity of multilingual vision-language models that properly account for the perceptual differences that are reflected in image captions across languages and cultures. In this work, through a multimodal, multilingual retrieval case study, we quantify the existing lack of model flexibility. We empirically show performance gaps between training on captions that come from native German perception and captions that have been either machine-translated or human-translated from English into German. To address these gaps, we further propose and evaluate caption augmentation strategies. While we achieve mean recall improvements (+1.3), gaps still remain, indicating an open area of future work for the community.
Incorporating Geo-Diverse Knowledge into Prompting for Increased Geographical Robustness in Object Recognition
Jan 03, 2024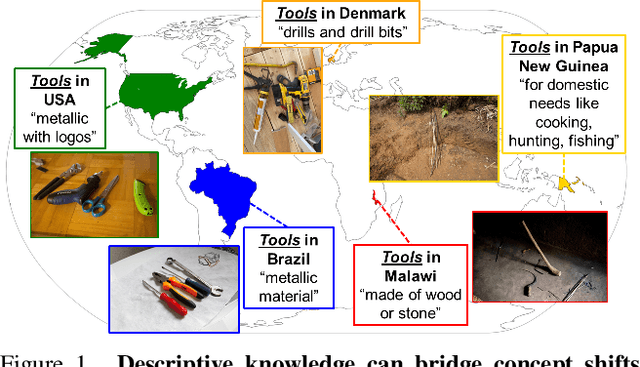
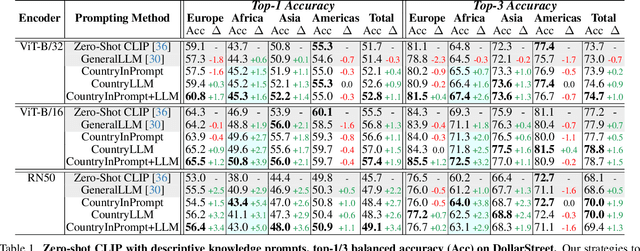
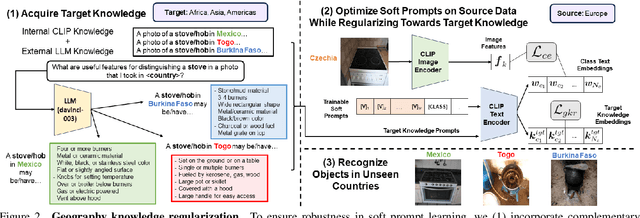
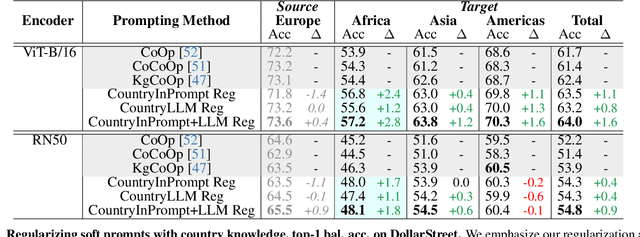
Existing object recognition models have been shown to lack robustness in diverse geographical scenarios due to significant domain shifts in design and context. Class representations need to be adapted to more accurately reflect an object concept under these shifts. In the absence of training data from target geographies, we hypothesize that geography-specific descriptive knowledge of object categories can be leveraged to enhance robustness. For this purpose, we explore the feasibility of probing a large-language model for geography-specific object knowledge, and we investigate integrating knowledge in zero-shot and learnable soft prompting with the CLIP vision-language model. In particular, we propose a geography knowledge regularization method to ensure that soft prompts trained on a source set of geographies generalize to an unseen target set of geographies. Our gains on DollarStreet when generalizing from a model trained only on data from Europe are as large as +2.8 on countries from Africa, and +4.6 on the hardest classes. We further show competitive performance vs. few-shot target training, and provide insights into how descriptive knowledge captures geographical differences.
Enhancing the Role of Context in Region-Word Alignment for Object Detection
Mar 17, 2023

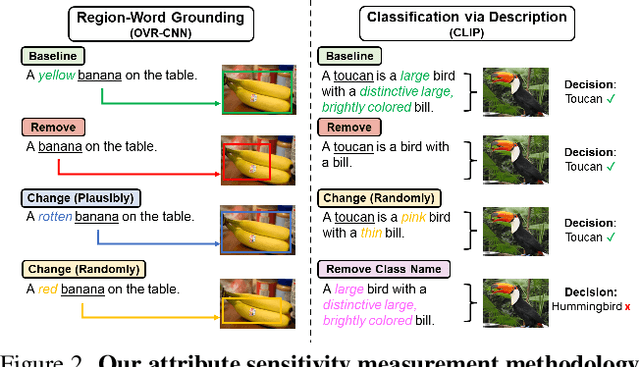

Vision-language pretraining to learn a fine-grained, region-word alignment between image-caption pairs has propelled progress in open-vocabulary object detection. We observe that region-word alignment methods are typically used in detection with respect to only object nouns, and the impact of other rich context in captions, such as attributes, is unclear. In this study, we explore how language context affects downstream object detection and propose to enhance the role of context. In particular, we show how to strategically contextualize the grounding pretraining objective for improved alignment. We further hone in on attributes as especially useful object context and propose a novel adjective and noun-based negative sampling strategy for increasing their focus in contrastive learning. Overall, our methods enhance object detection when compared to the state-of-the-art in region-word pretraining. We also highlight the fine-grained utility of an attribute-sensitive model through text-region retrieval and phrase grounding analysis.
Contrastive View Design Strategies to Enhance Robustness to Domain Shifts in Downstream Object Detection
Dec 09, 2022Contrastive learning has emerged as a competitive pretraining method for object detection. Despite this progress, there has been minimal investigation into the robustness of contrastively pretrained detectors when faced with domain shifts. To address this gap, we conduct an empirical study of contrastive learning and out-of-domain object detection, studying how contrastive view design affects robustness. In particular, we perform a case study of the detection-focused pretext task Instance Localization (InsLoc) and propose strategies to augment views and enhance robustness in appearance-shifted and context-shifted scenarios. Amongst these strategies, we propose changes to cropping such as altering the percentage used, adding IoU constraints, and integrating saliency based object priors. We also explore the addition of shortcut-reducing augmentations such as Poisson blending, texture flattening, and elastic deformation. We benchmark these strategies on abstract, weather, and context domain shifts and illustrate robust ways to combine them, in both pretraining on single-object and multi-object image datasets. Overall, our results and insights show how to ensure robustness through the choice of views in contrastive learning.
Story Understanding in Video Advertisements
Jul 29, 2018
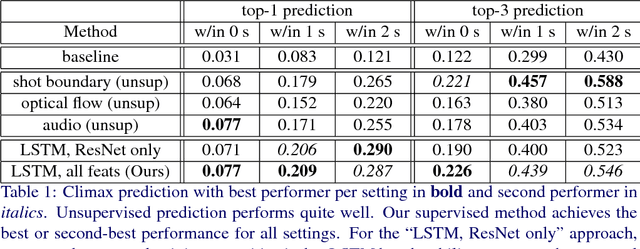


In order to resonate with the viewers, many video advertisements explore creative narrative techniques such as "Freytag's pyramid" where a story begins with exposition, followed by rising action, then climax, concluding with denouement. In the dramatic structure of ads in particular, climax depends on changes in sentiment. We dedicate our study to understand the dynamic structure of video ads automatically. To achieve this, we first crowdsource climax annotations on 1,149 videos from the Video Ads Dataset, which already provides sentiment annotations. We then use both unsupervised and supervised methods to predict the climax. Based on the predicted peak, the low-level visual and audio cues, and semantically meaningful context features, we build a sentiment prediction model that outperforms the current state-of-the-art model of sentiment prediction in video ads by 25%. In our ablation study, we show that using our context features, and modeling dynamics with an LSTM, are both crucial factors for improved performance.