 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniRes: Universal Image Restoration for Complex Degradations
Jun 05, 2025Real-world image restoration is hampered by diverse degradations stemming from varying capture conditions, capture devices and post-processing pipelines. Existing works make improvements through simulating those degradations and leveraging image generative priors, however generalization to in-the-wild data remains an unresolved problem. In this paper, we focus on complex degradations, i.e., arbitrary mixtures of multiple types of known degradations, which is frequently seen in the wild. A simple yet flexible diffusionbased framework, named UniRes, is proposed to address such degradations in an end-to-end manner. It combines several specialized models during the diffusion sampling steps, hence transferring the knowledge from several well-isolated restoration tasks to the restoration of complex in-the-wild degradations. This only requires well-isolated training data for several degradation types. The framework is flexible as extensions can be added through a unified formulation, and the fidelity-quality trade-off can be adjusted through a new paradigm. Our proposed method is evaluated on both complex-degradation and single-degradation image restoration datasets. Extensive qualitative and quantitative experimental results show consistent performance gain especially for images with complex degradations.
TextSR: Diffusion Super-Resolution with Multilingual OCR Guidance
May 29, 2025While recent advancements in Image Super-Resolution (SR) using diffusion models have shown promise in improving overall image quality, their application to scene text images has revealed limitations. These models often struggle with accurate text region localization and fail to effectively model image and multilingual character-to-shape priors. This leads to inconsistencies, the generation of hallucinated textures, and a decrease in the perceived quality of the super-resolved text. To address these issues, we introduce TextSR, a multimodal diffusion model specifically designed for Multilingual Scene Text Image Super-Resolution. TextSR leverages a text detector to pinpoint text regions within an image and then employs Optical Character Recognition (OCR) to extract multilingual text from these areas. The extracted text characters are then transformed into visual shapes using a UTF-8 based text encoder and cross-attention. Recognizing that OCR may sometimes produce inaccurate results in real-world scenarios, we have developed two innovative methods to enhance the robustness of our model. By integrating text character priors with the low-resolution text images, our model effectively guides the super-resolution process, enhancing fine details within the text and improving overall legibility. The superior performance of our model on both the TextZoom and TextVQA datasets sets a new benchmark for STISR, underscoring the efficacy of our approach.
Reference-Guided Identity Preserving Face Restoration
May 28, 2025Preserving face identity is a critical yet persistent challenge in diffusion-based image restoration. While reference faces offer a path forward, existing reference-based methods often fail to fully exploit their potential. This paper introduces a novel approach that maximizes reference face utility for improved face restoration and identity preservation. Our method makes three key contributions: 1) Composite Context, a comprehensive representation that fuses multi-level (high- and low-level) information from the reference face, offering richer guidance than prior singular representations. 2) Hard Example Identity Loss, a novel loss function that leverages the reference face to address the identity learning inefficiencies found in the existing identity loss. 3) A training-free method to adapt the model to multi-reference inputs during inference. The proposed method demonstrably restores high-quality faces and achieves state-of-the-art identity preserving restoration on benchmarks such as FFHQ-Ref and CelebA-Ref-Test, consistently outperforming previous work.
ArtVLM: Attribute Recognition Through Vision-Based Prefix Language Modeling
Aug 07, 2024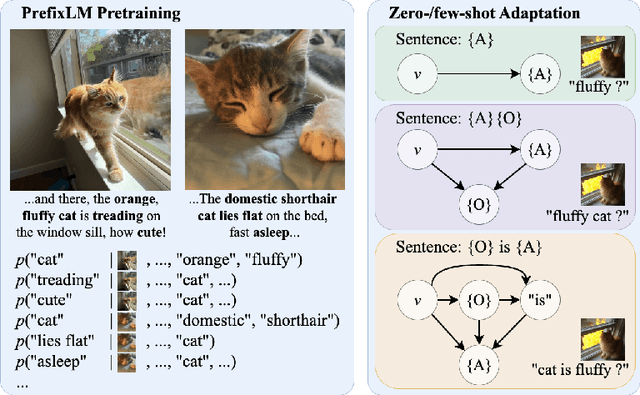

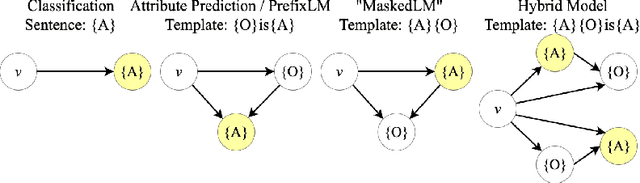

Recognizing and disentangling visual attributes from objects is a foundation to many computer vision applications. While large vision language representations like CLIP had largely resolved the task of zero-shot object recognition, zero-shot visual attribute recognition remains a challenge because CLIP's contrastively-learned vision-language representation cannot effectively capture object-attribute dependencies. In this paper, we target this weakness and propose a sentence generation-based retrieval formulation for attribute recognition that is novel in 1) explicitly modeling a to-be-measured and retrieved object-attribute relation as a conditional probability graph, which converts the recognition problem into a dependency-sensitive language-modeling problem, and 2) applying a large pretrained Vision-Language Model (VLM) on this reformulation and naturally distilling its knowledge of image-object-attribute relations to use towards attribute recognition. Specifically, for each attribute to be recognized on an image, we measure the visual-conditioned probability of generating a short sentence encoding the attribute's relation to objects on the image. Unlike contrastive retrieval, which measures likelihood by globally aligning elements of the sentence to the image, generative retrieval is sensitive to the order and dependency of objects and attributes in the sentence. We demonstrate through experiments that generative retrieval consistently outperforms contrastive retrieval on two visual reasoning datasets, Visual Attribute in the Wild (VAW), and our newly-proposed Visual Genome Attribute Ranking (VGARank).
TIP: Text-Driven Image Processing with Semantic and Restoration Instructions
Dec 18, 2023Text-driven diffusion models have become increasingly popular for various image editing tasks, including inpainting, stylization, and object replacement. However, it still remains an open research problem to adopt this language-vision paradigm for more fine-level image processing tasks, such as denoising, super-resolution, deblurring, and compression artifact removal. In this paper, we develop TIP, a Text-driven Image Processing framework that leverages natural language as a user-friendly interface to control the image restoration process. We consider the capacity of text information in two dimensions. First, we use content-related prompts to enhance the semantic alignment, effectively alleviating identity ambiguity in the restoration outcomes. Second, our approach is the first framework that supports fine-level instruction through language-based quantitative specification of the restoration strength, without the need for explicit task-specific design. In addition, we introduce a novel fusion mechanism that augments the existing ControlNet architecture by learning to rescale the generative prior, thereby achieving better restoration fidelity. Our extensive experiments demonstrate the superior restoration performance of TIP compared to the state of the arts, alongside offering the flexibility of text-based control over the restoration effects.
VILA: Learning Image Aesthetics from User Comments with Vision-Language Pretraining
Mar 24, 2023



Assessing the aesthetics of an image is challenging, as it is influenced by multiple factors including composition, color, style, and high-level semantics. Existing image aesthetic assessment (IAA) methods primarily rely on human-labeled rating scores, which oversimplify the visual aesthetic information that humans perceive. Conversely, user comments offer more comprehensive information and are a more natural way to express human opinions and preferences regarding image aesthetics. In light of this, we propose learning image aesthetics from user comments, and exploring vision-language pretraining methods to learn multimodal aesthetic representations. Specifically, we pretrain an image-text encoder-decoder model with image-comment pairs, using contrastive and generative objectives to learn rich and generic aesthetic semantics without human labels. To efficiently adapt the pretrained model for downstream IAA tasks, we further propose a lightweight rank-based adapter that employs text as an anchor to learn the aesthetic ranking concept. Our results show that our pretrained aesthetic vision-language model outperforms prior works on image aesthetic captioning over the AVA-Captions dataset, and it has powerful zero-shot capability for aesthetic tasks such as zero-shot style classification and zero-shot IAA, surpassing many supervised baselines. With only minimal finetuning parameters using the proposed adapter module, our model achieves state-of-the-art IAA performance over the AVA dataset.
Weakly-Supervised Action Detection Guided by Audio Narration
May 12, 2022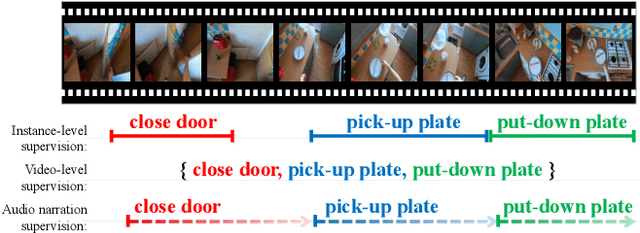
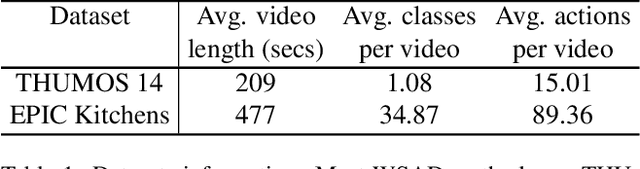
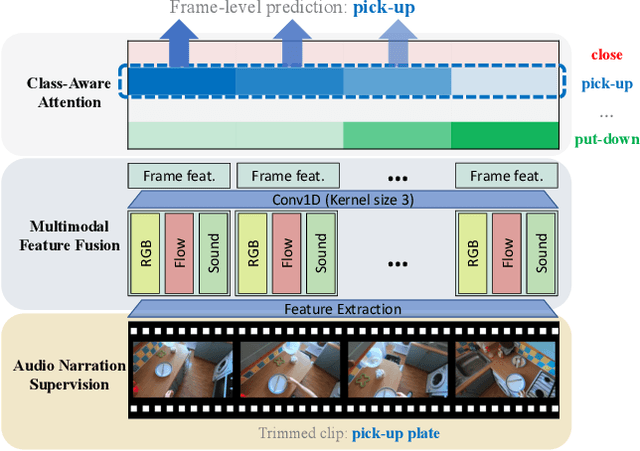

Videos are more well-organized curated data sources for visual concept learning than images. Unlike the 2-dimensional images which only involve the spatial information, the additional temporal dimension bridges and synchronizes multiple modalities. However, in most video detection benchmarks, these additional modalities are not fully utilized. For example, EPIC Kitchens is the largest dataset in first-person (egocentric) vision, yet it still relies on crowdsourced information to refine the action boundaries to provide instance-level action annotations. We explored how to eliminate the expensive annotations in video detection data which provide refined boundaries. We propose a model to learn from the narration supervision and utilize multimodal features, including RGB, motion flow, and ambient sound. Our model learns to attend to the frames related to the narration label while suppressing the irrelevant frames from being used. Our experiments show that noisy audio narration suffices to learn a good action detection model, thus reducing annotation expenses.
Linguistic Structures as Weak Supervision for Visual Scene Graph Generation
May 28, 2021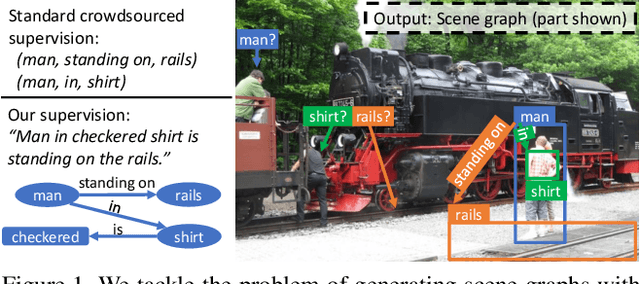

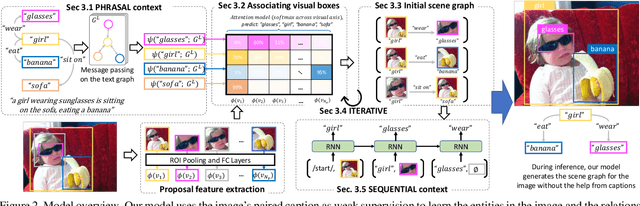
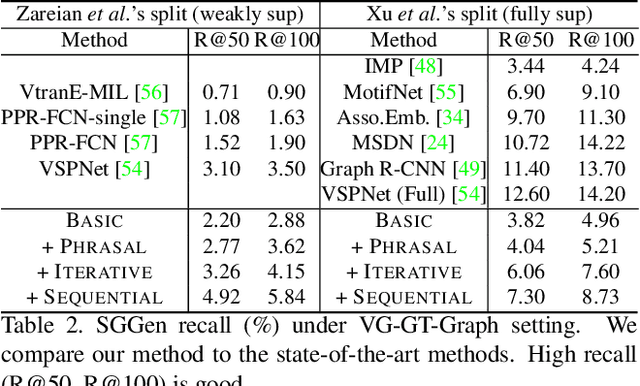
Prior work in scene graph generation requires categorical supervision at the level of triplets - subjects and objects, and predicates that relate them, either with or without bounding box information. However, scene graph generation is a holistic task: thus holistic, contextual supervision should intuitively improve performance. In this work, we explore how linguistic structures in captions can benefit scene graph generation. Our method captures the information provided in captions about relations between individual triplets, and context for subjects and objects (e.g. visual properties are mentioned). Captions are a weaker type of supervision than triplets since the alignment between the exhaustive list of human-annotated subjects and objects in triplets, and the nouns in captions, is weak. However, given the large and diverse sources of multimodal data on the web (e.g. blog posts with images and captions), linguistic supervision is more scalable than crowdsourced triplets. We show extensive experimental comparisons against prior methods which leverage instance- and image-level supervision, and ablate our method to show the impact of leveraging phrasal and sequential context, and techniques to improve localization of subjects and objects.
SpotPatch: Parameter-Efficient Transfer Learning for Mobile Object Detection
Jan 04, 2021
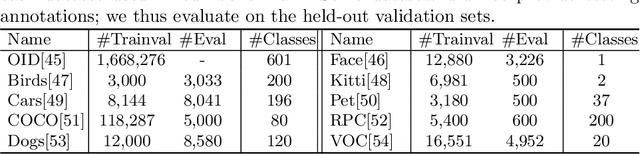
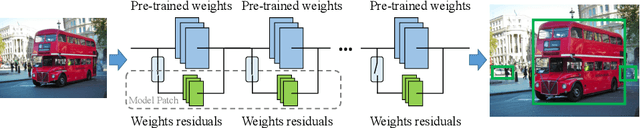
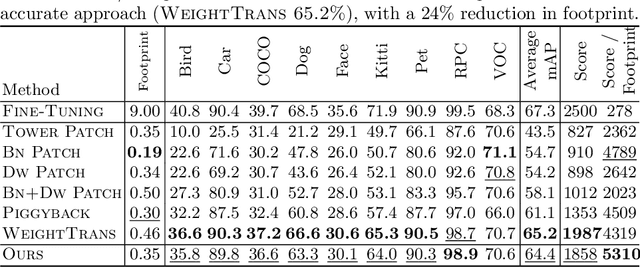
Deep learning based object detectors are commonly deployed on mobile devices to solve a variety of tasks. For maximum accuracy, each detector is usually trained to solve one single specific task, and comes with a completely independent set of parameters. While this guarantees high performance, it is also highly inefficient, as each model has to be separately downloaded and stored. In this paper we address the question: can task-specific detectors be trained and represented as a shared set of weights, plus a very small set of additional weights for each task? The main contributions of this paper are the following: 1) we perform the first systematic study of parameter-efficient transfer learning techniques for object detection problems; 2) we propose a technique to learn a model patch with a size that is dependent on the difficulty of the task to be learned, and validate our approach on 10 different object detection tasks. Our approach achieves similar accuracy as previously proposed approaches, while being significantly more compact.
Cap2Det: Learning to Amplify Weak Caption Supervision for Object Detection
Aug 16, 2019
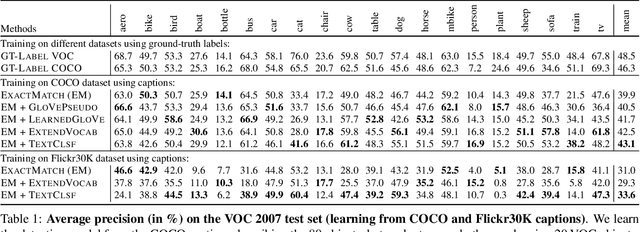

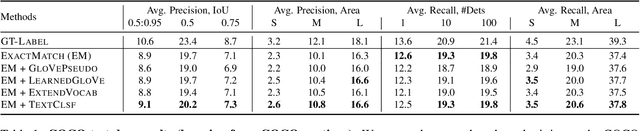
Learning to localize and name object instances is a fundamental problem in vision, but state-of-the-art approaches rely on expensive bounding box supervision. While weakly supervised detection (WSOD) methods relax the need for boxes to that of image-level annotations, even cheaper supervision is naturally available in the form of unstructured textual descriptions that users may freely provide when uploading image content. However, straightforward approaches to using such data for WSOD wastefully discard captions that do not exactly match object names. Instead, we show how to squeeze the most information out of these captions by training a text-only classifier that generalizes beyond dataset boundaries. Our discovery provides an opportunity for learning detection models from noisy but more abundant and freely-available caption data. We also validate our model on three classic object detection benchmarks and achieve state-of-the-art WSOD performance. Our code is available at https://github.com/yekeren/Cap2Det.