 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised 4D Cardiac Motion Tracking with Spatiotemporal Optical Flow Networks
Jul 05, 2024Cardiac motion tracking from echocardiography can be used to estimate and quantify myocardial motion within a cardiac cycle. It is a cost-efficient and effective approach for assessing myocardial function. However, ultrasound imaging has the inherent characteristics of spatially low resolution and temporally random noise, which leads to difficulties in obtaining reliable annotation. Thus it is difficult to perform supervised learning for motion tracking. In addition, there is no end-to-end unsupervised method currently in the literature. This paper presents a motion tracking method where unsupervised optical flow networks are designed with spatial reconstruction loss and temporal-consistency loss. Our proposed loss functions make use of the pair-wise and temporal correlation to estimate cardiac motion from noisy background. Experiments using a synthetic 4D echocardiography dataset has shown the effectiveness of our approach, and its superiority over existing methods on both accuracy and running speed. To the best of our knowledge, this is the first work performed that uses unsupervised end-to-end deep learning optical flow network for 4D cardiac motion tracking.
Binary Neural Networks as a general-propose compute paradigm for on-device computer vision
Feb 08, 2022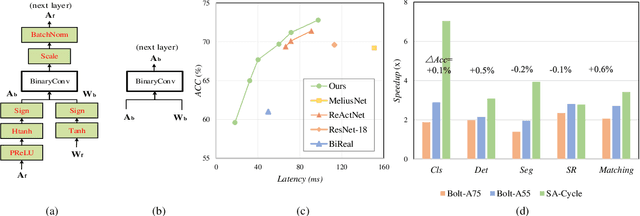

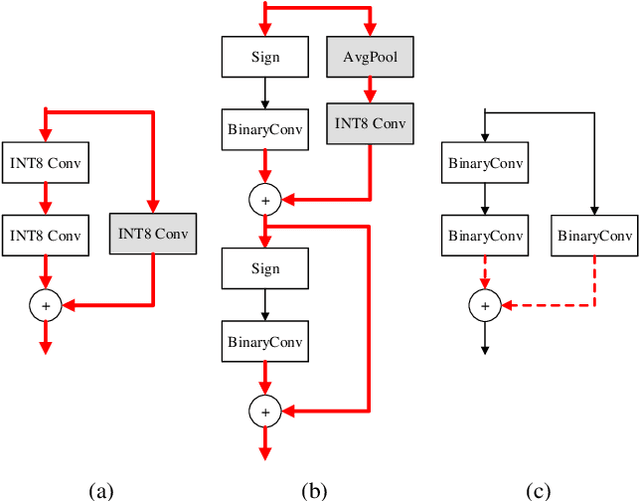
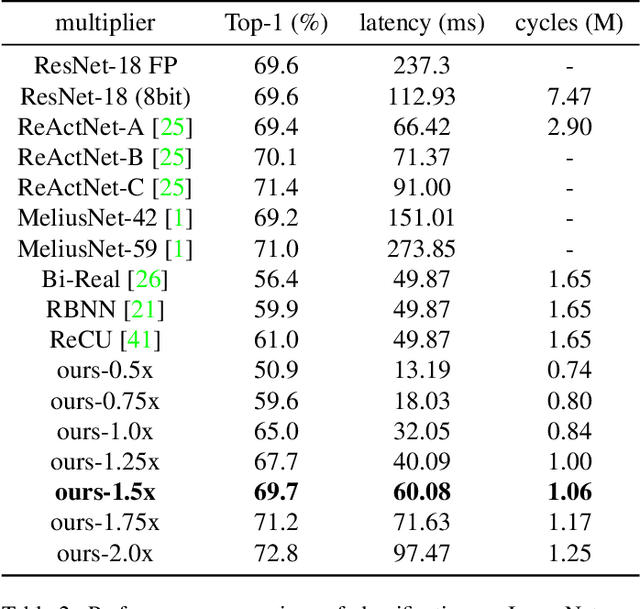
For binary neural networks (BNNs) to become the mainstream on-device computer vision algorithm, they must achieve a superior speed-vs-accuracy tradeoff than 8-bit quantization and establish a similar degree of general applicability in vision tasks. To this end, we propose a BNN framework comprising 1) a minimalistic inference scheme for hardware-friendliness, 2) an over-parameterized training scheme for high accuracy, and 3) a simple procedure to adapt to different vision tasks. The resultant framework overtakes 8-bit quantization in the speed-vs-accuracy tradeoff for classification, detection, segmentation, super-resolution and matching: our BNNs not only retain the accuracy levels of their 8-bit baselines but also showcase 1.3-2.4$\times$ faster FPS on mobile CPUs. Similar conclusions can be drawn for prototypical systolic-array-based AI accelerators, where our BNNs promise 2.8-7$\times$ fewer execution cycles than 8-bit and 2.1-2.7$\times$ fewer cycles than alternative BNN designs. These results suggest that the time for large-scale BNN adoption could be upon us.
SpotPatch: Parameter-Efficient Transfer Learning for Mobile Object Detection
Jan 04, 2021
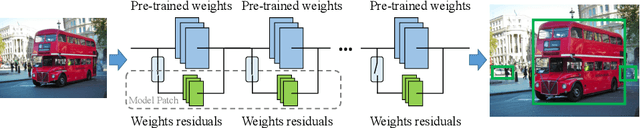
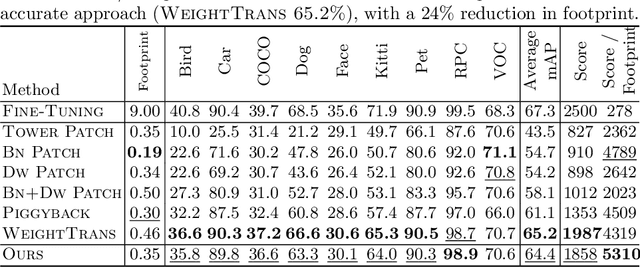
Deep learning based object detectors are commonly deployed on mobile devices to solve a variety of tasks. For maximum accuracy, each detector is usually trained to solve one single specific task, and comes with a completely independent set of parameters. While this guarantees high performance, it is also highly inefficient, as each model has to be separately downloaded and stored. In this paper we address the question: can task-specific detectors be trained and represented as a shared set of weights, plus a very small set of additional weights for each task? The main contributions of this paper are the following: 1) we perform the first systematic study of parameter-efficient transfer learning techniques for object detection problems; 2) we propose a technique to learn a model patch with a size that is dependent on the difficulty of the task to be learned, and validate our approach on 10 different object detection tasks. Our approach achieves similar accuracy as previously proposed approaches, while being significantly more compact.
Rethinking RGB-D Salient Object Detection: Models, Datasets, and Large-Scale Benchmarks
Jul 15, 2019



The use of RGB-D information for salient object detection has been explored in recent years. However, relatively few efforts have been spent in modeling salient object detection over real-world human activity scenes with RGB-D. In this work, we fill the gap by making the following contributions to RGB-D salient object detection. First, we carefully collect a new salient person (SIP) dataset, which consists of 1K high-resolution images that cover diverse real-world scenes from various viewpoints, poses, occlusion, illumination, and background. Second, we conduct a large-scale and so far the most comprehensive benchmark comparing contemporary methods, which has long been missing in the area and can serve as a baseline for future research. We systematically summarized 31 popular models, evaluated 17 state-of-the-art methods over seven datasets with totally about 91K images. Third, we propose a simple baseline architecture, called Deep Depth-Depurator Network (D3Net). It consists of a depth depurator unit and a feature learning module, performing initial low-quality depth map filtering and cross-modal feature learning respectively. These components form a nested structure and are elaborately designed to be learned jointly. D3Net exceeds the performance of any prior contenders across five metrics considered, thus serves as a strong baseline to advance the research frontier. We also demonstrate that D3Net can be used to efficiently extract salient person masks from the real scenes, enabling effective background changed book cover application with 20 fps on a single GPU. All the saliency maps, our new SIP dataset, baseline model, and evaluation tools are made publicly available at https://github.com/DengPingFan/D3NetBenchmark.
Looking Fast and Slow: Memory-Guided Mobile Video Object Detection
Mar 25, 2019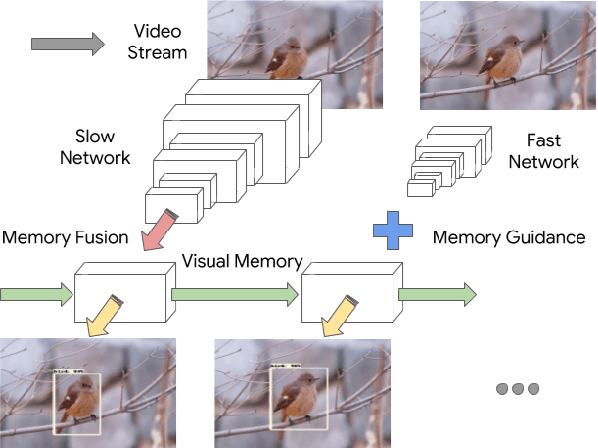
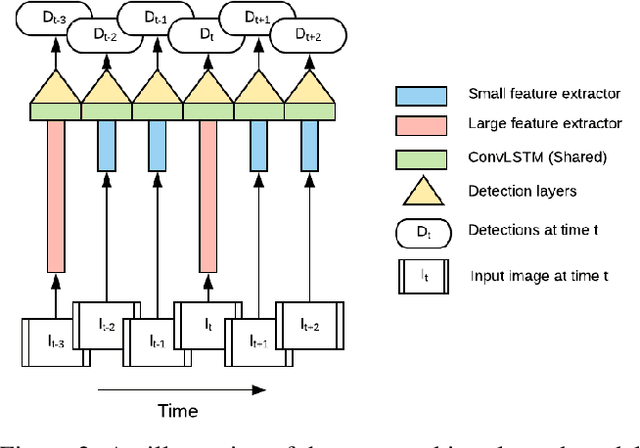
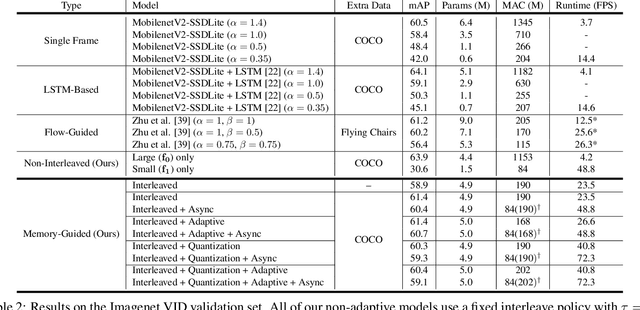
With a single eye fixation lasting a fraction of a second, the human visual system is capable of forming a rich representation of a complex environment, reaching a holistic understanding which facilitates object recognition and detection. This phenomenon is known as recognizing the "gist" of the scene and is accomplished by relying on relevant prior knowledge. This paper addresses the analogous question of whether using memory in computer vision systems can not only improve the accuracy of object detection in video streams, but also reduce the computation time. By interleaving conventional feature extractors with extremely lightweight ones which only need to recognize the gist of the scene, we show that minimal computation is required to produce accurate detections when temporal memory is present. In addition, we show that the memory contains enough information for deploying reinforcement learning algorithms to learn an adaptive inference policy. Our model achieves state-of-the-art performance among mobile methods on the Imagenet VID 2015 dataset, while running at speeds of up to 70+ FPS on a Pixel 3 phone.
Detect-to-Retrieve: Efficient Regional Aggregation for Image Search
Dec 04, 2018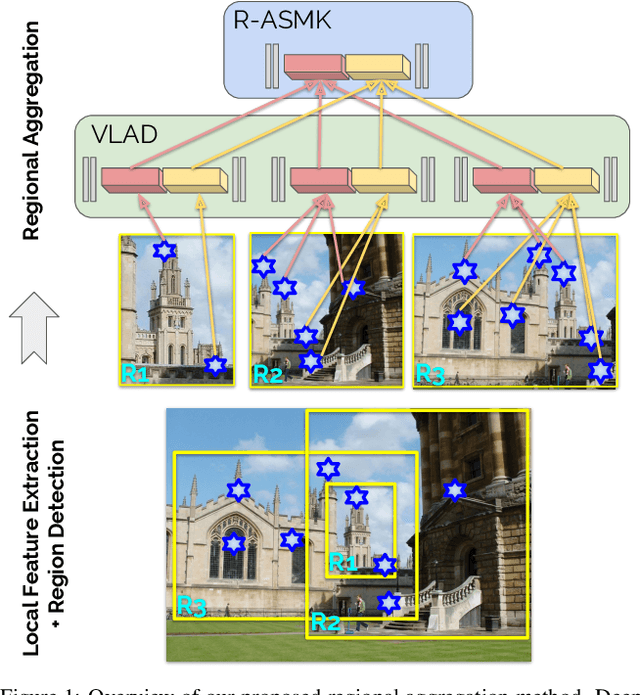
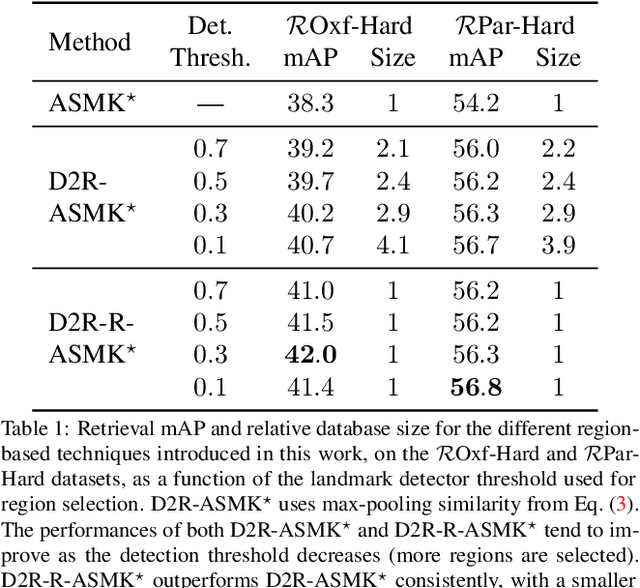

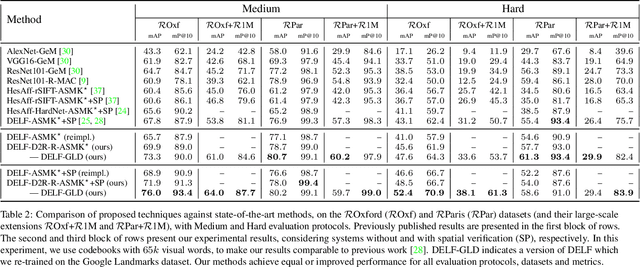
Retrieving object instances among cluttered scenes efficiently requires compact yet comprehensive regional image representations. Intuitively, object semantics can help build the index that focuses on the most relevant regions. However, due to the lack of bounding-box datasets for objects of interest among retrieval benchmarks, most recent work on regional representations has focused on either uniform or class-agnostic region selection. In this paper, we first fill the void by providing a new dataset of landmark bounding boxes, based on the Google Landmarks dataset, that includes $94k$ images with manually curated boxes from $15k$ unique landmarks. Then, we demonstrate how a trained landmark detector, using our new dataset, can be leveraged to index image regions and improve retrieval accuracy while being much more efficient than existing regional methods. In addition, we further introduce a novel regional aggregated selective match kernel (R-ASMK) to effectively combine information from detected regions into an improved holistic image representation. R-ASMK boosts image retrieval accuracy substantially at no additional memory cost, while even outperforming systems that index image regions independently. Our complete image retrieval system improves upon the previous state-of-the-art by significant margins on the Revisited Oxford and Paris datasets. Code and data will be released.
MobileNetV2: Inverted Residuals and Linear Bottlenecks
Apr 02, 2018

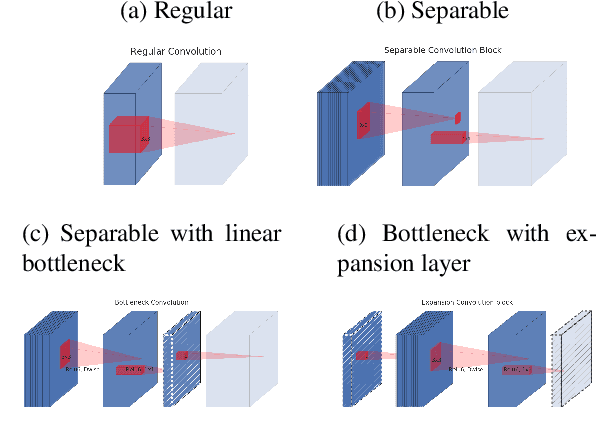
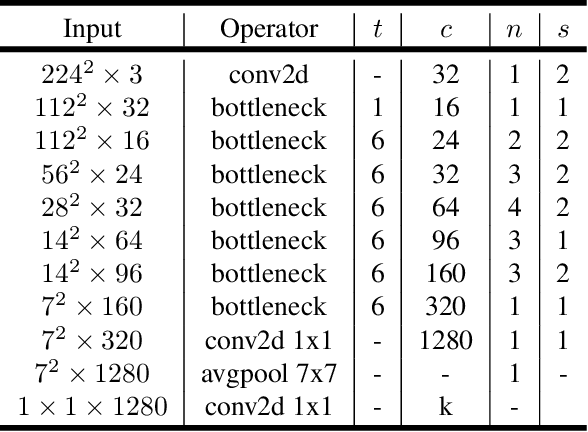
In this paper we describe a new mobile architecture, MobileNetV2, that improves the state of the art performance of mobile models on multiple tasks and benchmarks as well as across a spectrum of different model sizes. We also describe efficient ways of applying these mobile models to object detection in a novel framework we call SSDLite. Additionally, we demonstrate how to build mobile semantic segmentation models through a reduced form of DeepLabv3 which we call Mobile DeepLabv3. The MobileNetV2 architecture is based on an inverted residual structure where the input and output of the residual block are thin bottleneck layers opposite to traditional residual models which use expanded representations in the input an MobileNetV2 uses lightweight depthwise convolutions to filter features in the intermediate expansion layer. Additionally, we find that it is important to remove non-linearities in the narrow layers in order to maintain representational power. We demonstrate that this improves performance and provide an intuition that led to this design. Finally, our approach allows decoupling of the input/output domains from the expressiveness of the transformation, which provides a convenient framework for further analysis. We measure our performance on Imagenet classification, COCO object detection, VOC image segmentation. We evaluate the trade-offs between accuracy, and number of operations measured by multiply-adds (MAdd), as well as the number of parameters
Mobile Video Object Detection with Temporally-Aware Feature Maps
Mar 28, 2018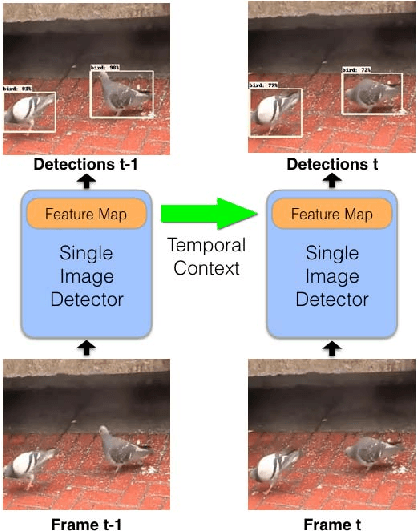
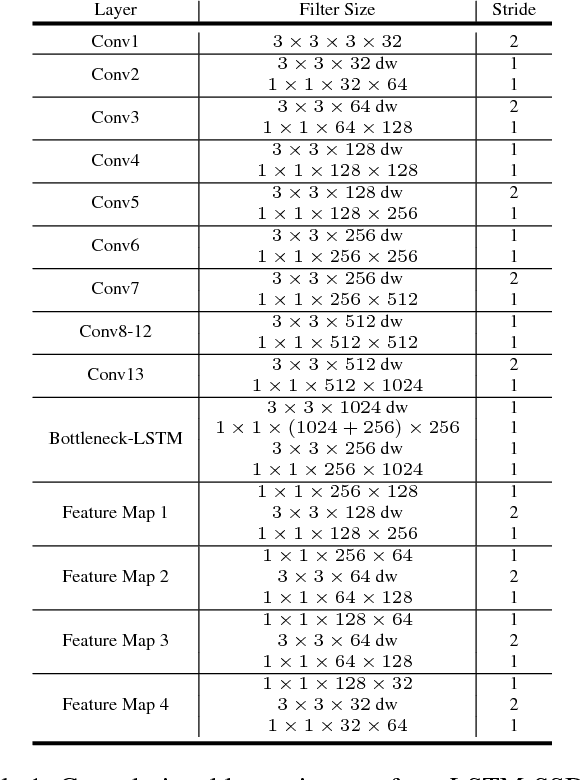
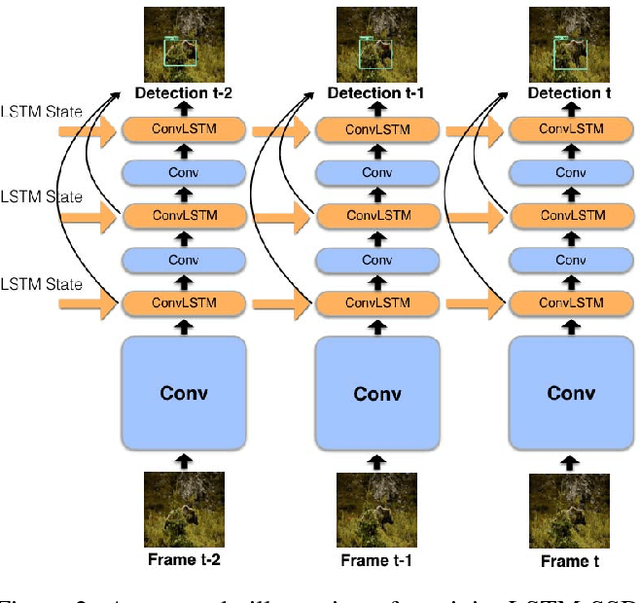

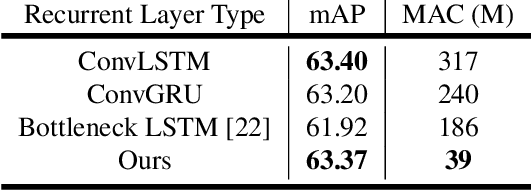
This paper introduces an online model for object detection in videos designed to run in real-time on low-powered mobile and embedded devices. Our approach combines fast single-image object detection with convolutional long short term memory (LSTM) layers to create an interweaved recurrent-convolutional architecture. Additionally, we propose an efficient Bottleneck-LSTM layer that significantly reduces computational cost compared to regular LSTMs. Our network achieves temporal awareness by using Bottleneck-LSTMs to refine and propagate feature maps across frames. This approach is substantially faster than existing detection methods in video, outperforming the fastest single-frame models in model size and computational cost while attaining accuracy comparable to much more expensive single-frame models on the Imagenet VID 2015 dataset. Our model reaches a real-time inference speed of up to 15 FPS on a mobile CPU.
MonoCap: Monocular Human Motion Capture using a CNN Coupled with a Geometric Prior
Mar 09, 2018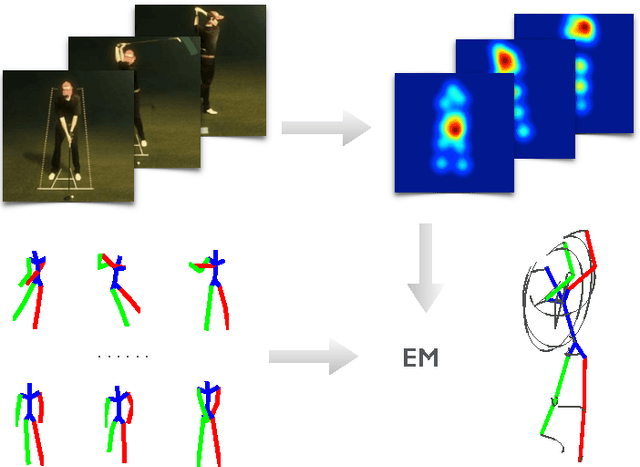



Recovering 3D full-body human pose is a challenging problem with many applications. It has been successfully addressed by motion capture systems with body worn markers and multiple cameras. In this paper, we address the more challenging case of not only using a single camera but also not leveraging markers: going directly from 2D appearance to 3D geometry. Deep learning approaches have shown remarkable abilities to discriminatively learn 2D appearance features. The missing piece is how to integrate 2D, 3D and temporal information to recover 3D geometry and account for the uncertainties arising from the discriminative model. We introduce a novel approach that treats 2D joint locations as latent variables whose uncertainty distributions are given by a deep fully convolutional neural network. The unknown 3D poses are modeled by a sparse representation and the 3D parameter estimates are realized via an Expectation-Maximization algorithm, where it is shown that the 2D joint location uncertainties can be conveniently marginalized out during inference. Extensive evaluation on benchmark datasets shows that the proposed approach achieves greater accuracy over state-of-the-art baselines. Notably, the proposed approach does not require synchronized 2D-3D data for training and is applicable to "in-the-wild" images, which is demonstrated with the MPII dataset.
Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference
Dec 15, 2017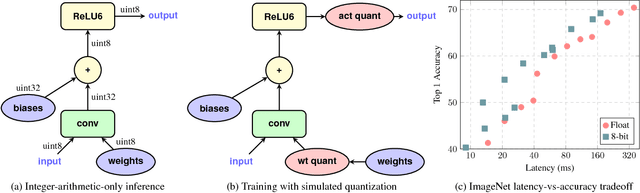

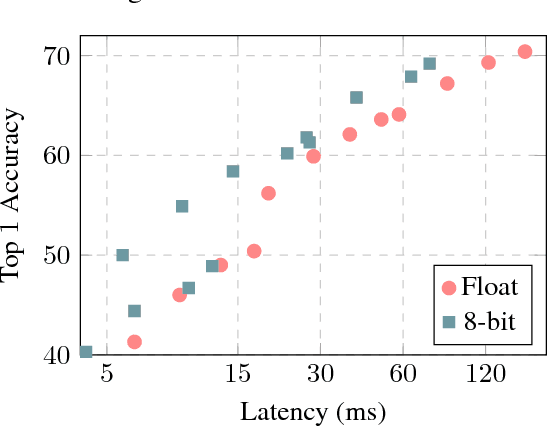
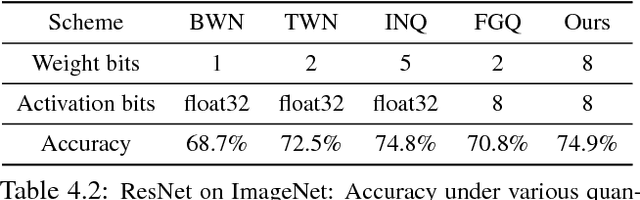
The rising popularity of intelligent mobile devices and the daunting computational cost of deep learning-based models call for efficient and accurate on-device inference schemes. We propose a quantization scheme that allows inference to be carried out using integer-only arithmetic, which can be implemented more efficiently than floating point inference on commonly available integer-only hardware. We also co-design a training procedure to preserve end-to-end model accuracy post quantization. As a result, the proposed quantization scheme improves the tradeoff between accuracy and on-device latency. The improvements are significant even on MobileNets, a model family known for run-time efficiency, and are demonstrated in ImageNet classification and COCO detection on popular CPUs.