 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Learning for Image-based Detection of Molecular Alterations in Digital Pathology
Jun 30, 2022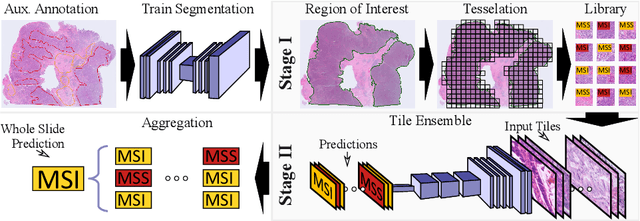
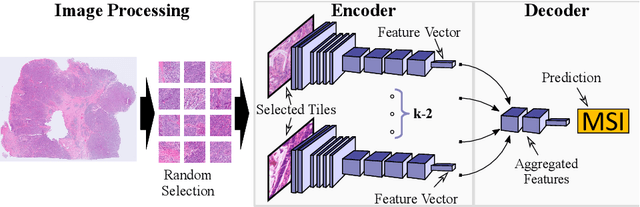
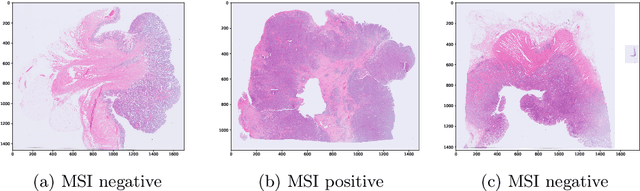
Current approaches for classification of whole slide images (WSI) in digital pathology predominantly utilize a two-stage learning pipeline. The first stage identifies areas of interest (e.g. tumor tissue), while the second stage processes cropped tiles from these areas in a supervised fashion. During inference, a large number of tiles are combined into a unified prediction for the entire slide. A major drawback of such approaches is the requirement for task-specific auxiliary labels which are not acquired in clinical routine. We propose a novel learning pipeline for WSI classification that is trainable end-to-end and does not require any auxiliary annotations. We apply our approach to predict molecular alterations for a number of different use-cases, including detection of microsatellite instability in colorectal tumors and prediction of specific mutations for colon, lung, and breast cancer cases from The Cancer Genome Atlas. Results reach AUC scores of up to 94% and are shown to be competitive with state of the art two-stage pipelines. We believe our approach can facilitate future research in digital pathology and contribute to solve a large range of problems around the prediction of cancer phenotypes, hopefully enabling personalized therapies for more patients in future.
Large Scale Joint Semantic Re-Localisation and Scene Understanding via Globally Unique Instance Coordinate Regression
Sep 23, 2019
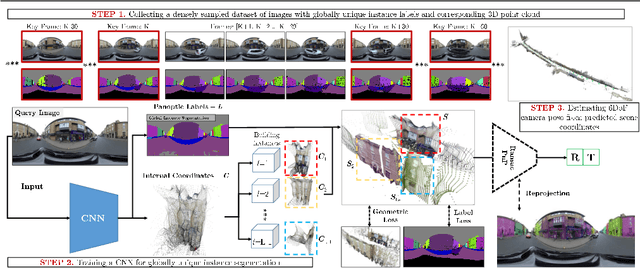

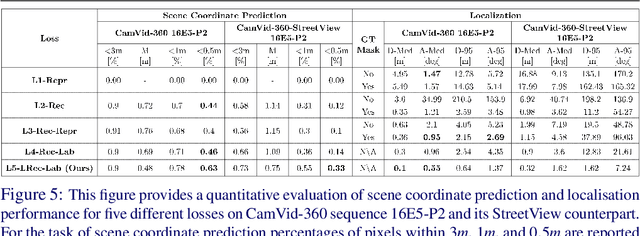
In this work we present a novel approach to joint semantic localisation and scene understanding. Our work is motivated by the need for localisation algorithms which not only predict 6-DoF camera pose but also simultaneously recognise surrounding objects and estimate 3D geometry. Such capabilities are crucial for computer vision guided systems which interact with the environment: autonomous driving, augmented reality and robotics. In particular, we propose a two step procedure. During the first step we train a convolutional neural network to jointly predict per-pixel globally unique instance labels and corresponding local coordinates for each instance of a static object (e.g. a building). During the second step we obtain scene coordinates by combining object center coordinates and local coordinates and use them to perform 6-DoF camera pose estimation. We evaluate our approach on real world (CamVid-360) and artificial (SceneCity) autonomous driving datasets. We obtain smaller mean distance and angular errors than state-of-the-art 6-DoF pose estimation algorithms based on direct pose regression and pose estimation from scene coordinates on all datasets. Our contributions include: (i) a novel formulation of scene coordinate regression as two separate tasks of object instance recognition and local coordinate regression and a demonstration that our proposed solution allows to predict accurate 3D geometry of static objects and estimate 6-DoF pose of camera on (ii) maps larger by several orders of magnitude than previously attempted by scene coordinate regression methods, as well as on (iii) lightweight, approximate 3D maps built from 3D primitives such as building-aligned cuboids.
Detect-to-Retrieve: Efficient Regional Aggregation for Image Search
Dec 04, 2018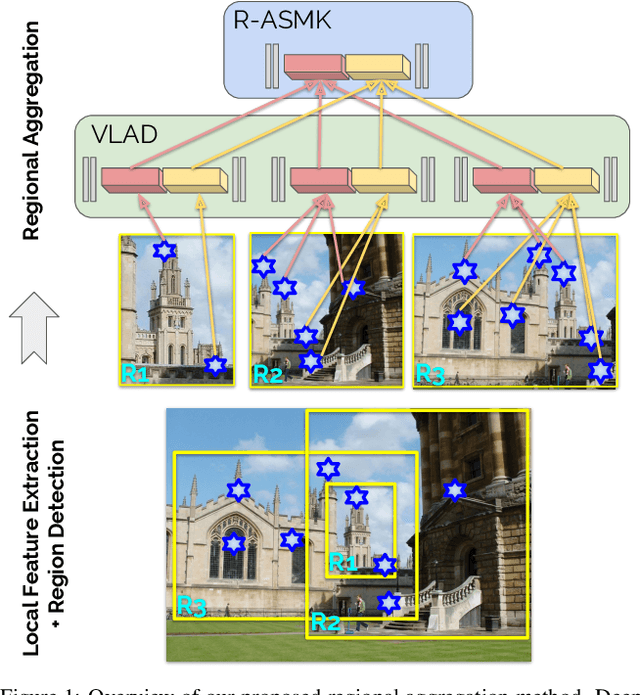
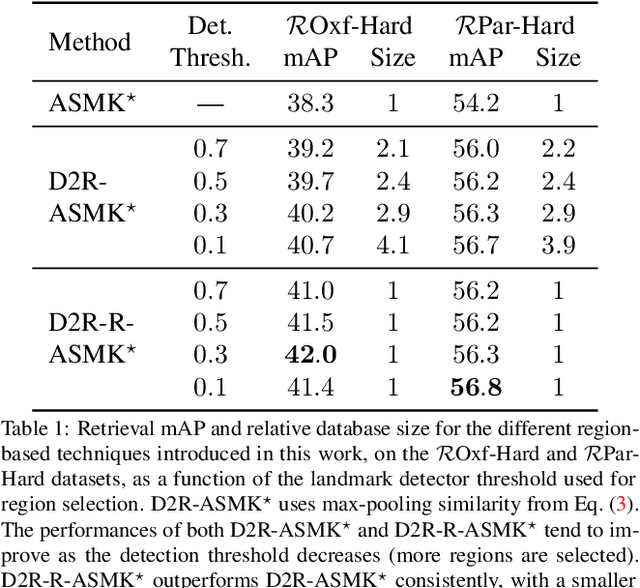

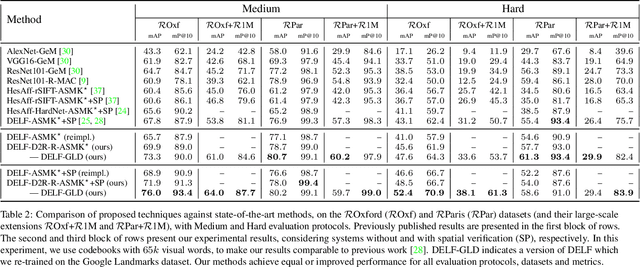
Retrieving object instances among cluttered scenes efficiently requires compact yet comprehensive regional image representations. Intuitively, object semantics can help build the index that focuses on the most relevant regions. However, due to the lack of bounding-box datasets for objects of interest among retrieval benchmarks, most recent work on regional representations has focused on either uniform or class-agnostic region selection. In this paper, we first fill the void by providing a new dataset of landmark bounding boxes, based on the Google Landmarks dataset, that includes $94k$ images with manually curated boxes from $15k$ unique landmarks. Then, we demonstrate how a trained landmark detector, using our new dataset, can be leveraged to index image regions and improve retrieval accuracy while being much more efficient than existing regional methods. In addition, we further introduce a novel regional aggregated selective match kernel (R-ASMK) to effectively combine information from detected regions into an improved holistic image representation. R-ASMK boosts image retrieval accuracy substantially at no additional memory cost, while even outperforming systems that index image regions independently. Our complete image retrieval system improves upon the previous state-of-the-art by significant margins on the Revisited Oxford and Paris datasets. Code and data will be released.
MultiNet: Real-time Joint Semantic Reasoning for Autonomous Driving
May 08, 2018
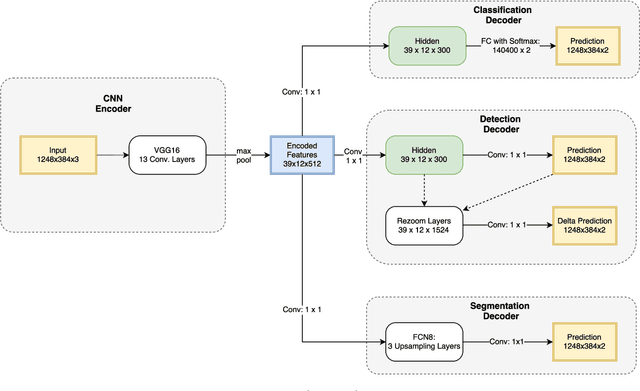
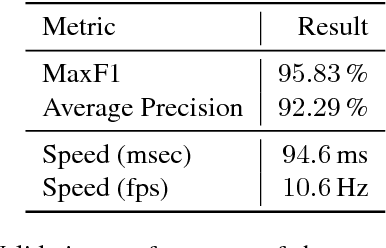
While most approaches to semantic reasoning have focused on improving performance, in this paper we argue that computational times are very important in order to enable real time applications such as autonomous driving. Towards this goal, we present an approach to joint classification, detection and semantic segmentation via a unified architecture where the encoder is shared amongst the three tasks. Our approach is very simple, can be trained end-to-end and performs extremely well in the challenging KITTI dataset, outperforming the state-of-the-art in the road segmentation task. Our approach is also very efficient, taking less than 100 ms to perform all tasks.
Comparative evaluation of instrument segmentation and tracking methods in minimally invasive surgery
May 07, 2018
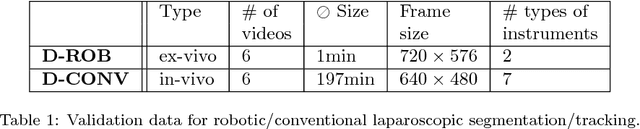

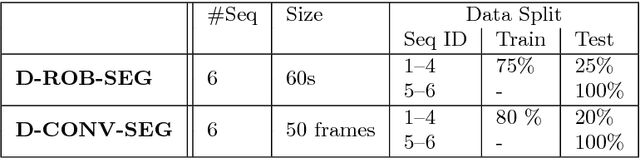
Intraoperative segmentation and tracking of minimally invasive instruments is a prerequisite for computer- and robotic-assisted surgery. Since additional hardware like tracking systems or the robot encoders are cumbersome and lack accuracy, surgical vision is evolving as promising techniques to segment and track the instruments using only the endoscopic images. However, what is missing so far are common image data sets for consistent evaluation and benchmarking of algorithms against each other. The paper presents a comparative validation study of different vision-based methods for instrument segmentation and tracking in the context of robotic as well as conventional laparoscopic surgery. The contribution of the paper is twofold: we introduce a comprehensive validation data set that was provided to the study participants and present the results of the comparative validation study. Based on the results of the validation study, we arrive at the conclusion that modern deep learning approaches outperform other methods in instrument segmentation tasks, but the results are still not perfect. Furthermore, we show that merging results from different methods actually significantly increases accuracy in comparison to the best stand-alone method. On the other hand, the results of the instrument tracking task show that this is still an open challenge, especially during challenging scenarios in conventional laparoscopic surgery.
Pixel-wise Segmentation of Street with Neural Networks
Nov 02, 2015



Pixel-wise street segmentation of photographs taken from a drivers perspective is important for self-driving cars and can also support other object recognition tasks. A framework called SST was developed to examine the accuracy and execution time of different neural networks. The best neural network achieved an $F_1$-score of 89.5% with a simple feedforward neural network which trained to solve a regression task.