 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset for Semantic Segmentation in the Presence of Unknowns
Mar 28, 2025Before deployment in the real-world deep neural networks require thorough evaluation of how they handle both knowns, inputs represented in the training data, and unknowns (anomalies). This is especially important for scene understanding tasks with safety critical applications, such as in autonomous driving. Existing datasets allow evaluation of only knowns or unknowns - but not both, which is required to establish "in the wild" suitability of deep neural network models. To bridge this gap, we propose a novel anomaly segmentation dataset, ISSU, that features a diverse set of anomaly inputs from cluttered real-world environments. The dataset is twice larger than existing anomaly segmentation datasets, and provides a training, validation and test set for controlled in-domain evaluation. The test set consists of a static and temporal part, with the latter comprised of videos. The dataset provides annotations for both closed-set (knowns) and anomalies, enabling closed-set and open-set evaluation. The dataset covers diverse conditions, such as domain and cross-sensor shift, illumination variation and allows ablation of anomaly detection methods with respect to these variations. Evaluation results of current state-of-the-art methods confirm the need for improvements especially in domain-generalization, small and large object segmentation.
Calibrated Out-of-Distribution Detection with a Generic Representation
Mar 23, 2023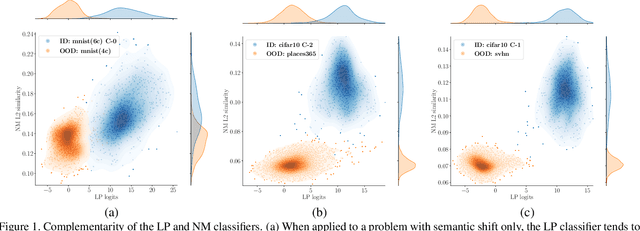
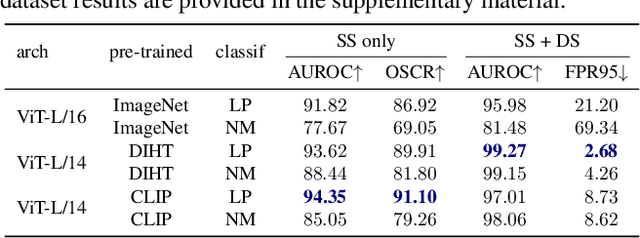
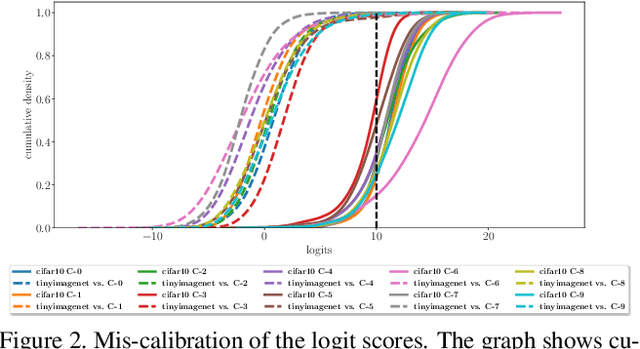
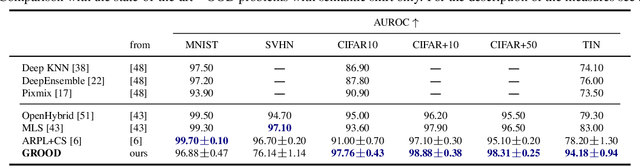
Out-of-distribution detection is a common issue in deploying vision models in practice and solving it is an essential building block in safety critical applications. Existing OOD detection solutions focus on improving the OOD robustness of a classification model trained exclusively on in-distribution (ID) data. In this work, we take a different approach and propose to leverage generic pre-trained representations. We first investigate the behaviour of simple classifiers built on top of such representations and show striking performance gains compared to the ID trained representations. We propose a novel OOD method, called GROOD, that achieves excellent performance, predicated by the use of a good generic representation. Only a trivial training process is required for adapting GROOD to a particular problem. The method is simple, general, efficient, calibrated and with only a few hyper-parameters. The method achieves state-of-the-art performance on a number of OOD benchmarks, reaching near perfect performance on several of them. The source code is available at https://github.com/vojirt/GROOD.
Large Scale Joint Semantic Re-Localisation and Scene Understanding via Globally Unique Instance Coordinate Regression
Sep 23, 2019
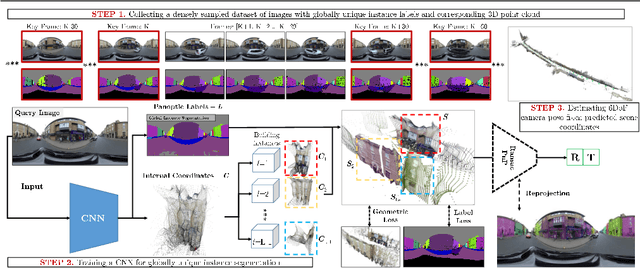

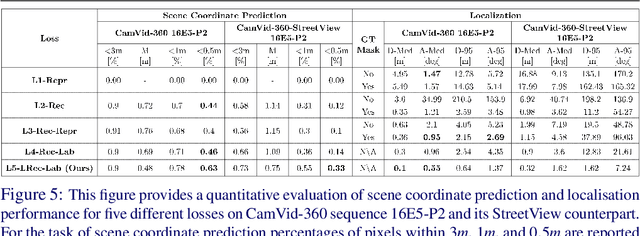
In this work we present a novel approach to joint semantic localisation and scene understanding. Our work is motivated by the need for localisation algorithms which not only predict 6-DoF camera pose but also simultaneously recognise surrounding objects and estimate 3D geometry. Such capabilities are crucial for computer vision guided systems which interact with the environment: autonomous driving, augmented reality and robotics. In particular, we propose a two step procedure. During the first step we train a convolutional neural network to jointly predict per-pixel globally unique instance labels and corresponding local coordinates for each instance of a static object (e.g. a building). During the second step we obtain scene coordinates by combining object center coordinates and local coordinates and use them to perform 6-DoF camera pose estimation. We evaluate our approach on real world (CamVid-360) and artificial (SceneCity) autonomous driving datasets. We obtain smaller mean distance and angular errors than state-of-the-art 6-DoF pose estimation algorithms based on direct pose regression and pose estimation from scene coordinates on all datasets. Our contributions include: (i) a novel formulation of scene coordinate regression as two separate tasks of object instance recognition and local coordinate regression and a demonstration that our proposed solution allows to predict accurate 3D geometry of static objects and estimate 6-DoF pose of camera on (ii) maps larger by several orders of magnitude than previously attempted by scene coordinate regression methods, as well as on (iii) lightweight, approximate 3D maps built from 3D primitives such as building-aligned cuboids.
Online Adaptive Hidden Markov Model for Multi-Tracker Fusion
Mar 04, 2016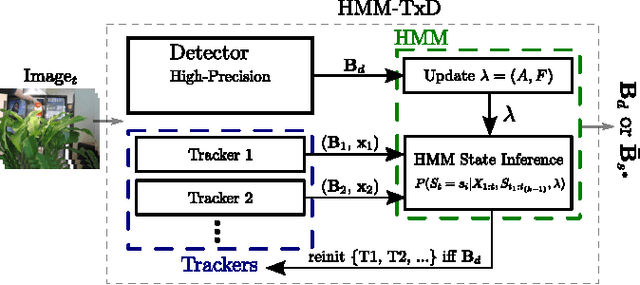
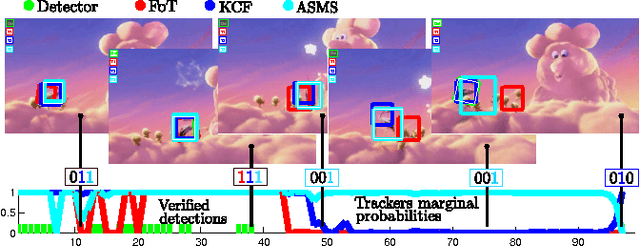
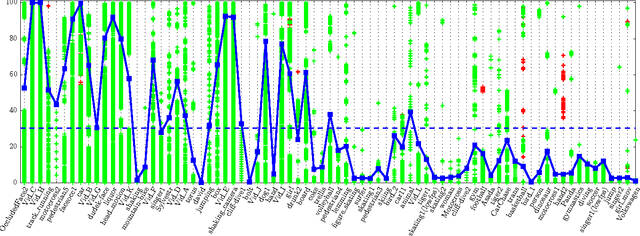
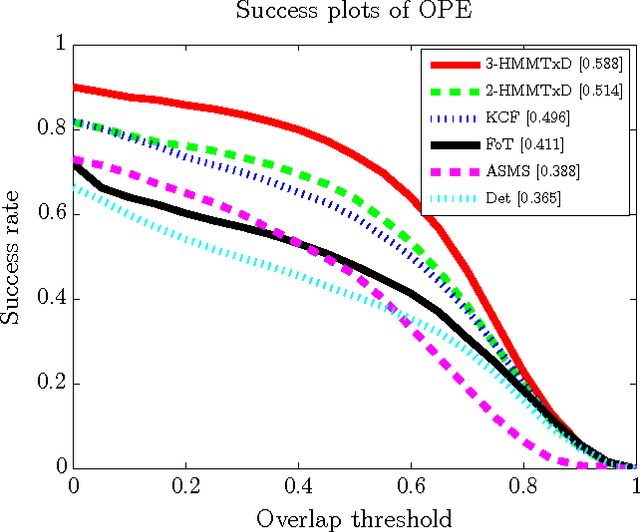
In this paper, we propose a novel method for visual object tracking called HMMTxD. The method fuses observations from complementary out-of-the box trackers and a detector by utilizing a hidden Markov model whose latent states correspond to a binary vector expressing the failure of individual trackers. The Markov model is trained in an unsupervised way, relying on an online learned detector to provide a source of tracker-independent information for a modified Baum- Welch algorithm that updates the model w.r.t. the partially annotated data. We show the effectiveness of the proposed method on combination of two and three tracking algorithms. The performance of HMMTxD is evaluated on two standard benchmarks (CVPR2013 and VOT) and on a rich collection of 77 publicly available sequences. The HMMTxD outperforms the state-of-the-art, often significantly, on all datasets in almost all criteria.
A Novel Performance Evaluation Methodology for Single-Target Trackers
Jan 08, 2016
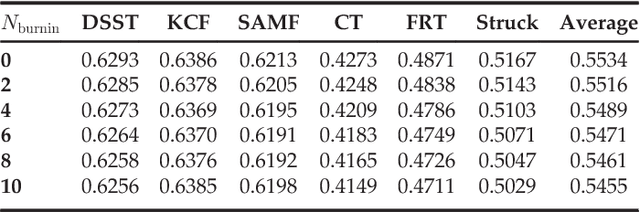
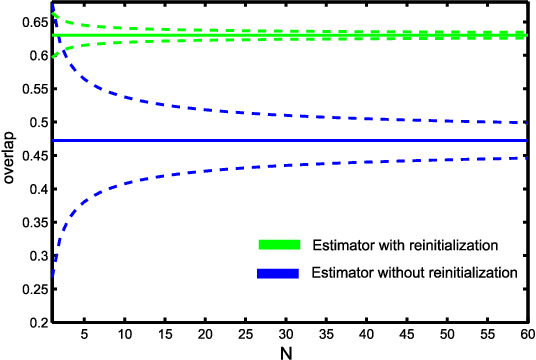
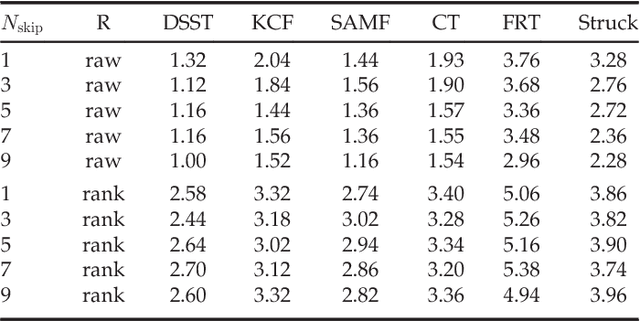
This paper addresses the problem of single-target tracker performance evaluation. We consider the performance measures, the dataset and the evaluation system to be the most important components of tracker evaluation and propose requirements for each of them. The requirements are the basis of a new evaluation methodology that aims at a simple and easily interpretable tracker comparison. The ranking-based methodology addresses tracker equivalence in terms of statistical significance and practical differences. A fully-annotated dataset with per-frame annotations with several visual attributes is introduced. The diversity of its visual properties is maximized in a novel way by clustering a large number of videos according to their visual attributes. This makes it the most sophistically constructed and annotated dataset to date. A multi-platform evaluation system allowing easy integration of third-party trackers is presented as well. The proposed evaluation methodology was tested on the VOT2014 challenge on the new dataset and 38 trackers, making it the largest benchmark to date. Most of the tested trackers are indeed state-of-the-art since they outperform the standard baselines, resulting in a highly-challenging benchmark. An exhaustive analysis of the dataset from the perspective of tracking difficulty is carried out. To facilitate tracker comparison a new performance visualization technique is proposed.