 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4th Workshop on Maritime Computer Vision (MaCVi): Challenge Overview
Apr 14, 2026The 4th Workshop on Maritime Computer Vision (MaCVi) is organized as part of CVPR 2026. This edition features five benchmark challenges with emphasis on both predictive accuracy and embedded real-time feasibility. This report summarizes the MaCVi 2026 challenge setup, evaluation protocols, datasets, and benchmark tracks, and presents quantitative results, qualitative comparisons, and cross-challenge analyses of emerging method trends. We also include technical reports from top-performing teams to highlight practical design choices and lessons learned across the benchmark suite. Datasets, leaderboards, and challenge resources are available at https://macvi.org/workshop/cvpr26.
Mitigating Objectness Bias and Region-to-Text Misalignment for Open-Vocabulary Panoptic Segmentation
Mar 22, 2026Open-vocabulary panoptic segmentation remains hindered by two coupled issues: (i) mask selection bias, where objectness heads trained on closed vocabularies suppress masks of categories not observed in training, and (ii) limited regional understanding in vision-language models such as CLIP, which were optimized for global image classification rather than localized segmentation. We introduce OVRCOAT, a simple, modular framework that tackles both. First, a CLIP-conditioned objectness adjustment (COAT) updates background/foreground probabilities, preserving high-quality masks for out-of-vocabulary objects. Second, an open-vocabulary mask-to-text refinement (OVR) strengthens CLIP's region-level alignment to improve classification of both seen and unseen classes with markedly lower memory cost than prior fine-tuning schemes. The two components combine to jointly improve objectness estimation and mask recognition, yielding consistent panoptic gains. Despite its simplicity, OVRCOAT sets a new state of the art on ADE20K (+5.5% PQ) and delivers clear gains on Mapillary Vistas and Cityscapes (+7.1% and +3% PQ, respectively). The code is available at: https://github.com/nickormushev/OVRCOAT
CoDi -- an exemplar-conditioned diffusion model for low-shot counting
Dec 23, 2025Low-shot object counting addresses estimating the number of previously unobserved objects in an image using only few or no annotated test-time exemplars. A considerable challenge for modern low-shot counters are dense regions with small objects. While total counts in such situations are typically well addressed by density-based counters, their usefulness is limited by poor localization capabilities. This is better addressed by point-detection-based counters, which are based on query-based detectors. However, due to limited number of pre-trained queries, they underperform on images with very large numbers of objects, and resort to ad-hoc techniques like upsampling and tiling. We propose CoDi, the first latent diffusion-based low-shot counter that produces high-quality density maps on which object locations can be determined by non-maxima suppression. Our core contribution is the new exemplar-based conditioning module that extracts and adjusts the object prototypes to the intermediate layers of the denoising network, leading to accurate object location estimation. On FSC benchmark, CoDi outperforms state-of-the-art by 15% MAE, 13% MAE and 10% MAE in the few-shot, one-shot, and reference-less scenarios, respectively, and sets a new state-of-the-art on MCAC benchmark by outperforming the top method by 44% MAE. The code is available at https://github.com/gsustar/CoDi.
Generalized-Scale Object Counting with Gradual Query Aggregation
Nov 11, 2025Few-shot detection-based counters estimate the number of instances in the image specified only by a few test-time exemplars. A common approach to localize objects across multiple sizes is to merge backbone features of different resolutions. Furthermore, to enable small object detection in densely populated regions, the input image is commonly upsampled and tiling is applied to cope with the increased computational and memory requirements. Because of these ad-hoc solutions, existing counters struggle with images containing diverse-sized objects and densely populated regions of small objects. We propose GECO2, an end-to-end few-shot counting and detection method that explicitly addresses the object scale issues. A new dense query representation gradually aggregates exemplar-specific feature information across scales that leads to high-resolution dense queries that enable detection of large as well as small objects. GECO2 surpasses state-of-the-art few-shot counters in counting as well as detection accuracy by 10% while running 3x times faster at smaller GPU memory footprint.
Distractor-Aware Memory-Based Visual Object Tracking
Sep 17, 2025
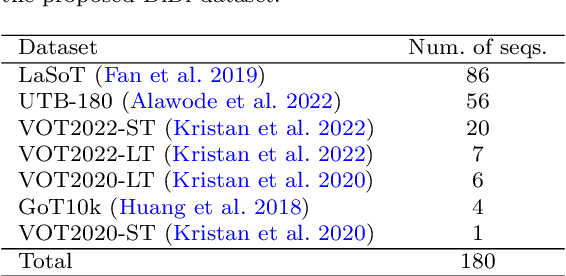

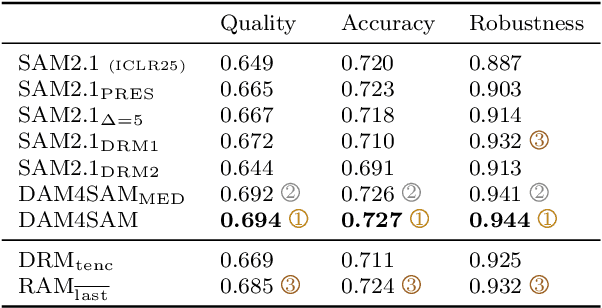
Recent emergence of memory-based video segmentation methods such as SAM2 has led to models with excellent performance in segmentation tasks, achieving leading results on numerous benchmarks. However, these modes are not fully adjusted for visual object tracking, where distractors (i.e., objects visually similar to the target) pose a key challenge. In this paper we propose a distractor-aware drop-in memory module and introspection-based management method for SAM2, leading to DAM4SAM. Our design effectively reduces the tracking drift toward distractors and improves redetection capability after object occlusion. To facilitate the analysis of tracking in the presence of distractors, we construct DiDi, a Distractor-Distilled dataset. DAM4SAM outperforms SAM2.1 on thirteen benchmarks and sets new state-of-the-art results on ten. Furthermore, integrating the proposed distractor-aware memory into a real-time tracker EfficientTAM leads to 11% improvement and matches tracking quality of the non-real-time SAM2.1-L on multiple tracking and segmentation benchmarks, while integration with edge-based tracker EdgeTAM delivers 4% performance boost, demonstrating a very good generalization across architectures.
What Holds Back Open-Vocabulary Segmentation?
Aug 06, 2025Standard segmentation setups are unable to deliver models that can recognize concepts outside the training taxonomy. Open-vocabulary approaches promise to close this gap through language-image pretraining on billions of image-caption pairs. Unfortunately, we observe that the promise is not delivered due to several bottlenecks that have caused the performance to plateau for almost two years. This paper proposes novel oracle components that identify and decouple these bottlenecks by taking advantage of the groundtruth information. The presented validation experiments deliver important empirical findings that provide a deeper insight into the failures of open-vocabulary models and suggest prominent approaches to unlock the future research.
3rd Workshop on Maritime Computer Vision (MaCVi) 2025: Challenge Results
Jan 17, 2025The 3rd Workshop on Maritime Computer Vision (MaCVi) 2025 addresses maritime computer vision for Unmanned Surface Vehicles (USV) and underwater. This report offers a comprehensive overview of the findings from the challenges. We provide both statistical and qualitative analyses, evaluating trends from over 700 submissions. All datasets, evaluation code, and the leaderboard are available to the public at https://macvi.org/workshop/macvi25.
PanSR: An Object-Centric Mask Transformer for Panoptic Segmentation
Dec 13, 2024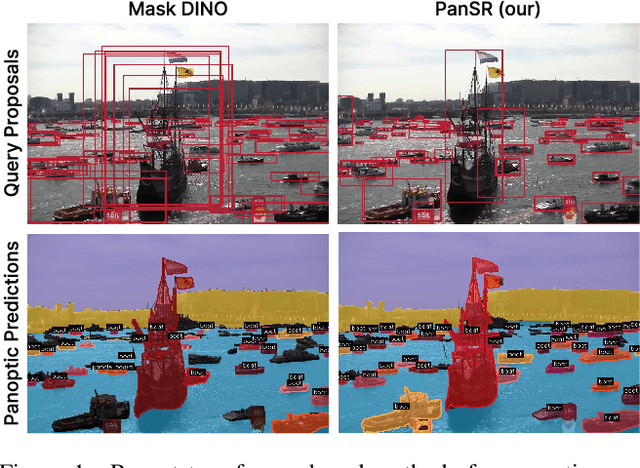
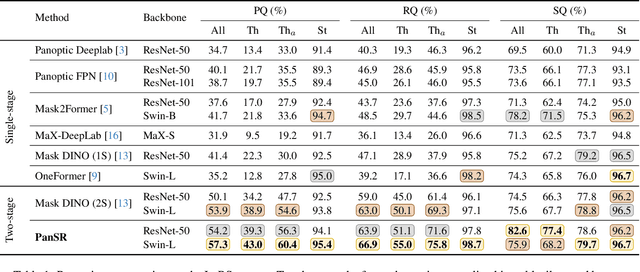
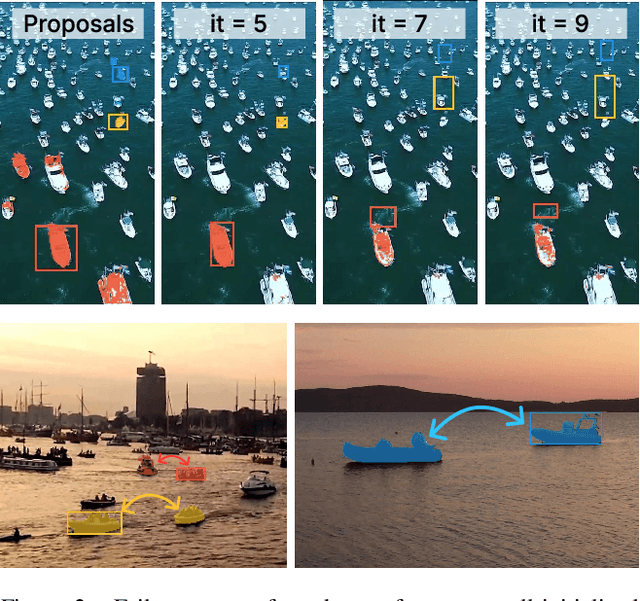

Panoptic segmentation is a fundamental task in computer vision and a crucial component for perception in autonomous vehicles. Recent mask-transformer-based methods achieve impressive performance on standard benchmarks but face significant challenges with small objects, crowded scenes and scenes exhibiting a wide range of object scales. We identify several fundamental shortcomings of the current approaches: (i) the query proposal generation process is biased towards larger objects, resulting in missed smaller objects, (ii) initially well-localized queries may drift to other objects, resulting in missed detections, (iii) spatially well-separated instances may be merged into a single mask causing inconsistent and false scene interpretations. To address these issues, we rethink the individual components of the network and its supervision, and propose a novel method for panoptic segmentation PanSR. PanSR effectively mitigates instance merging, enhances small-object detection and increases performance in crowded scenes, delivering a notable +3.4 PQ improvement over state-of-the-art on the challenging LaRS benchmark, while reaching state-of-the-art performance on Cityscapes. The code and models will be publicly available at https://github.com/lojzezust/PanSR.
A Distractor-Aware Memory for Visual Object Tracking with SAM2
Nov 26, 2024Memory-based trackers are video object segmentation methods that form the target model by concatenating recently tracked frames into a memory buffer and localize the target by attending the current image to the buffered frames. While already achieving top performance on many benchmarks, it was the recent release of SAM2 that placed memory-based trackers into focus of the visual object tracking community. Nevertheless, modern trackers still struggle in the presence of distractors. We argue that a more sophisticated memory model is required, and propose a new distractor-aware memory model for SAM2 and an introspection-based update strategy that jointly addresses the segmentation accuracy as well as tracking robustness. The resulting tracker is denoted as SAM2.1++. We also propose a new distractor-distilled DiDi dataset to study the distractor problem better. SAM2.1++ outperforms SAM2.1 and related SAM memory extensions on seven benchmarks and sets a solid new state-of-the-art on six of them.
A Novel Unified Architecture for Low-Shot Counting by Detection and Segmentation
Sep 27, 2024Low-shot object counters estimate the number of objects in an image using few or no annotated exemplars. Objects are localized by matching them to prototypes, which are constructed by unsupervised image-wide object appearance aggregation. Due to potentially diverse object appearances, the existing approaches often lead to overgeneralization and false positive detections. Furthermore, the best-performing methods train object localization by a surrogate loss, that predicts a unit Gaussian at each object center. This loss is sensitive to annotation error, hyperparameters and does not directly optimize the detection task, leading to suboptimal counts. We introduce GeCo, a novel low-shot counter that achieves accurate object detection, segmentation, and count estimation in a unified architecture. GeCo robustly generalizes the prototypes across objects appearances through a novel dense object query formulation. In addition, a novel counting loss is proposed, that directly optimizes the detection task and avoids the issues of the standard surrogate loss. GeCo surpasses the leading few-shot detection-based counters by $\sim$25\% in the total count MAE, achieves superior detection accuracy and sets a new solid state-of-the-art result across all low-shot counting setups.