 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized-Scale Object Counting with Gradual Query Aggregation
Nov 11, 2025Few-shot detection-based counters estimate the number of instances in the image specified only by a few test-time exemplars. A common approach to localize objects across multiple sizes is to merge backbone features of different resolutions. Furthermore, to enable small object detection in densely populated regions, the input image is commonly upsampled and tiling is applied to cope with the increased computational and memory requirements. Because of these ad-hoc solutions, existing counters struggle with images containing diverse-sized objects and densely populated regions of small objects. We propose GECO2, an end-to-end few-shot counting and detection method that explicitly addresses the object scale issues. A new dense query representation gradually aggregates exemplar-specific feature information across scales that leads to high-resolution dense queries that enable detection of large as well as small objects. GECO2 surpasses state-of-the-art few-shot counters in counting as well as detection accuracy by 10% while running 3x times faster at smaller GPU memory footprint.
Distractor-Aware Memory-Based Visual Object Tracking
Sep 17, 2025
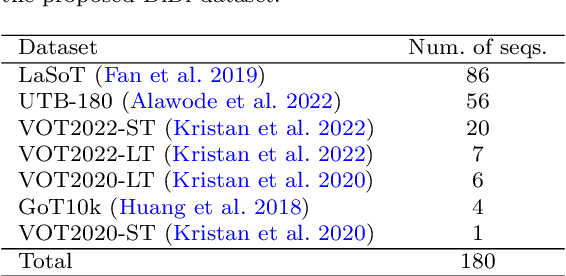

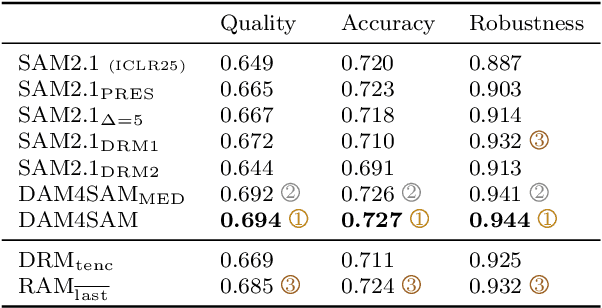
Recent emergence of memory-based video segmentation methods such as SAM2 has led to models with excellent performance in segmentation tasks, achieving leading results on numerous benchmarks. However, these modes are not fully adjusted for visual object tracking, where distractors (i.e., objects visually similar to the target) pose a key challenge. In this paper we propose a distractor-aware drop-in memory module and introspection-based management method for SAM2, leading to DAM4SAM. Our design effectively reduces the tracking drift toward distractors and improves redetection capability after object occlusion. To facilitate the analysis of tracking in the presence of distractors, we construct DiDi, a Distractor-Distilled dataset. DAM4SAM outperforms SAM2.1 on thirteen benchmarks and sets new state-of-the-art results on ten. Furthermore, integrating the proposed distractor-aware memory into a real-time tracker EfficientTAM leads to 11% improvement and matches tracking quality of the non-real-time SAM2.1-L on multiple tracking and segmentation benchmarks, while integration with edge-based tracker EdgeTAM delivers 4% performance boost, demonstrating a very good generalization across architectures.
A Distractor-Aware Memory for Visual Object Tracking with SAM2
Nov 26, 2024Memory-based trackers are video object segmentation methods that form the target model by concatenating recently tracked frames into a memory buffer and localize the target by attending the current image to the buffered frames. While already achieving top performance on many benchmarks, it was the recent release of SAM2 that placed memory-based trackers into focus of the visual object tracking community. Nevertheless, modern trackers still struggle in the presence of distractors. We argue that a more sophisticated memory model is required, and propose a new distractor-aware memory model for SAM2 and an introspection-based update strategy that jointly addresses the segmentation accuracy as well as tracking robustness. The resulting tracker is denoted as SAM2.1++. We also propose a new distractor-distilled DiDi dataset to study the distractor problem better. SAM2.1++ outperforms SAM2.1 and related SAM memory extensions on seven benchmarks and sets a solid new state-of-the-art on six of them.
A New Dataset and a Distractor-Aware Architecture for Transparent Object Tracking
Jan 08, 2024
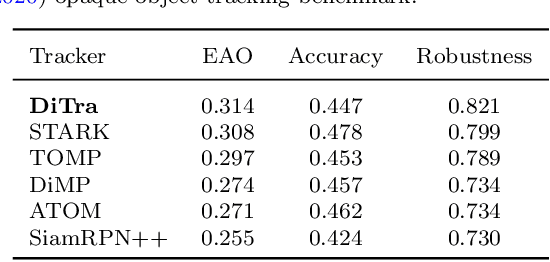
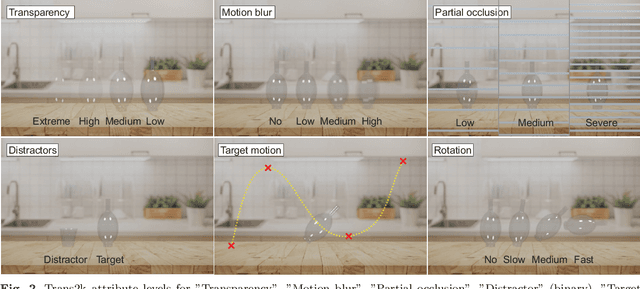
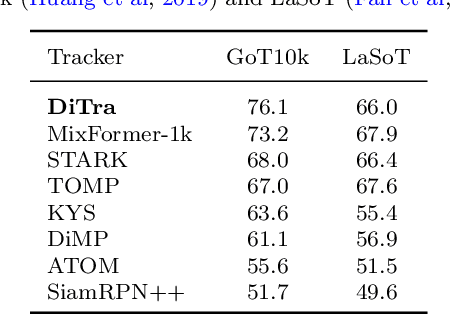
Performance of modern trackers degrades substantially on transparent objects compared to opaque objects. This is largely due to two distinct reasons. Transparent objects are unique in that their appearance is directly affected by the background. Furthermore, transparent object scenes often contain many visually similar objects (distractors), which often lead to tracking failure. However, development of modern tracking architectures requires large training sets, which do not exist in transparent object tracking. We present two contributions addressing the aforementioned issues. We propose the first transparent object tracking training dataset Trans2k that consists of over 2k sequences with 104,343 images overall, annotated by bounding boxes and segmentation masks. Standard trackers trained on this dataset consistently improve by up to 16%. Our second contribution is a new distractor-aware transparent object tracker (DiTra) that treats localization accuracy and target identification as separate tasks and implements them by a novel architecture. DiTra sets a new state-of-the-art in transparent object tracking and generalizes well to opaque objects.
A Low-Shot Object Counting Network With Iterative Prototype Adaptation
Nov 15, 2022

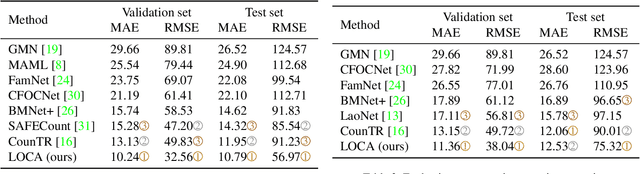

We consider low-shot counting of arbitrary semantic categories in the image using only few annotated exemplars (few-shot) or no exemplars (no-shot). The standard few-shot pipeline follows extraction of appearance queries from exemplars and matching them with image features to infer the object counts. Existing methods extract queries by feature pooling, but neglect the shape information (e.g., size and aspect), which leads to a reduced object localization accuracy and count estimates. We propose a Low-shot Object Counting network with iterative prototype Adaptation (LOCA). Our main contribution is the new object prototype extraction module, which iteratively fuses the exemplar shape and appearance queries with image features. The module is easily adapted to zero-shot scenario, enabling LOCA to cover the entire spectrum of low-shot counting problems. LOCA outperforms all recent state-of-the-art methods on FSC147 benchmark by 20-30% in RMSE on one-shot and few-shot and achieves state-of-the-art on zero-shot scenarios, while demonstrating better generalization capabilities.
Trans2k: Unlocking the Power of Deep Models for Transparent Object Tracking
Oct 07, 2022

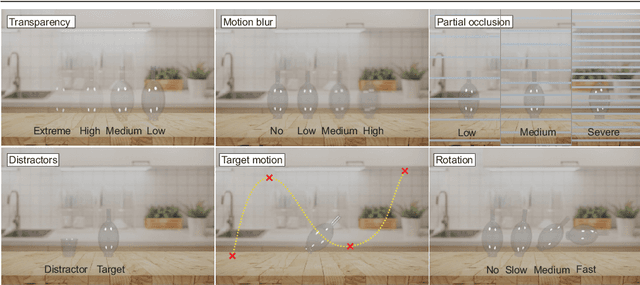

Visual object tracking has focused predominantly on opaque objects, while transparent object tracking received very little attention. Motivated by the uniqueness of transparent objects in that their appearance is directly affected by the background, the first dedicated evaluation dataset has emerged recently. We contribute to this effort by proposing the first transparent object tracking training dataset Trans2k that consists of over 2k sequences with 104,343 images overall, annotated by bounding boxes and segmentation masks. Noting that transparent objects can be realistically rendered by modern renderers, we quantify domain-specific attributes and render the dataset containing visual attributes and tracking situations not covered in the existing object training datasets. We observe a consistent performance boost (up to 16%) across a diverse set of modern tracking architectures when trained using Trans2k, and show insights not previously possible due to the lack of appropriate training sets. The dataset and the rendering engine will be publicly released to unlock the power of modern learning-based trackers and foster new designs in transparent object tracking.
Object Tracking by Reconstruction with View-Specific Discriminative Correlation Filters
Nov 27, 2018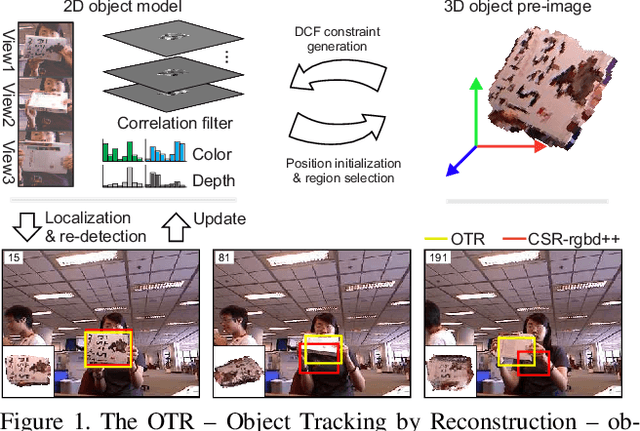
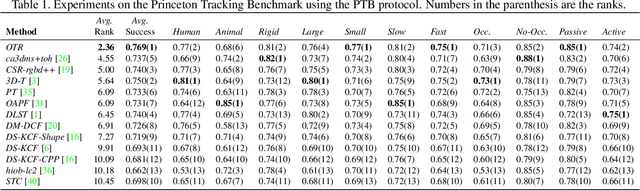
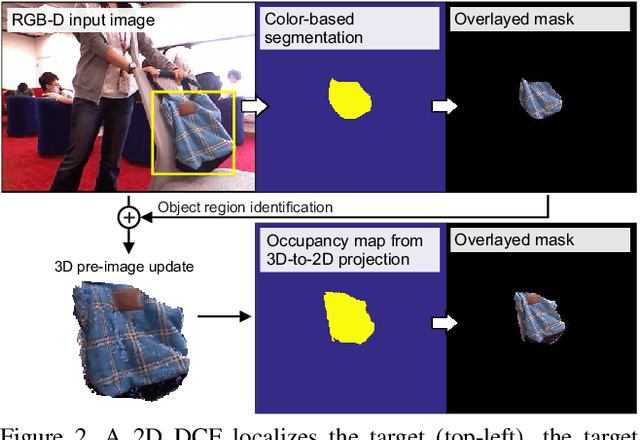
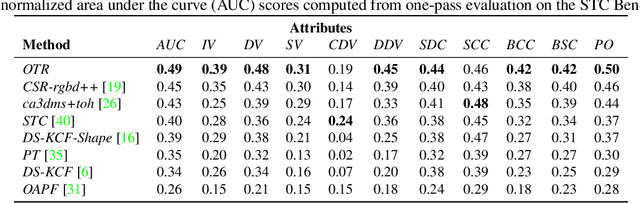
Standard RGB-D trackers treat the target as an inherently 2D structure, which makes modelling appearance changes related even to simple out-of-plane rotation highly challenging. We address this limitation by proposing a novel long-term RGB-D tracker - Object Tracking by Reconstruction (OTR). The tracker performs online 3D target reconstruction to facilitate robust learning of a set of view-specific discriminative correlation filters (DCFs). The 3D reconstruction supports two performance-enhancing features: (i) generation of accurate spatial support for constrained DCF learning from its 2D projection and (ii) point cloud based estimation of 3D pose change for selection and storage of view-specific DCFs which are used to robustly localize the target after out-of-view rotation or heavy occlusion. Extensive evaluation of OTR on the challenging Princeton RGB-D tracking and STC Benchmarks shows it outperforms the state-of-the-art by a large margin.