 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth-only Object Tracking
Oct 22, 2021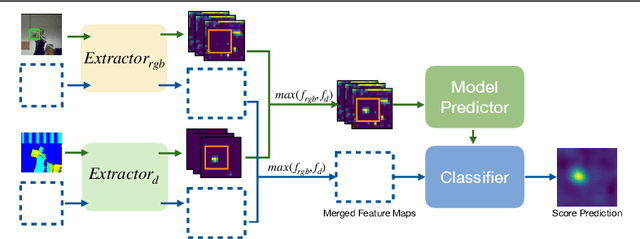
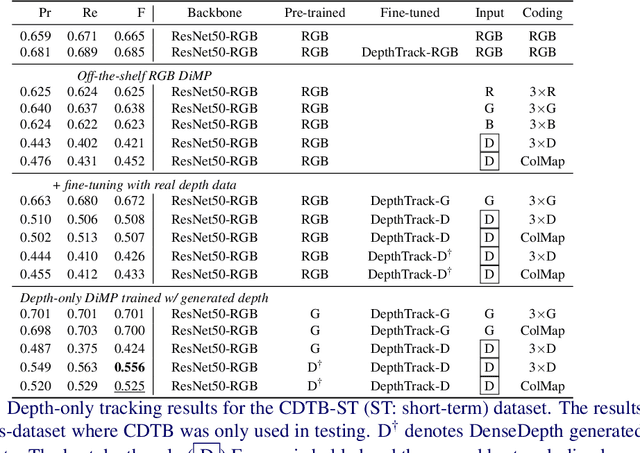

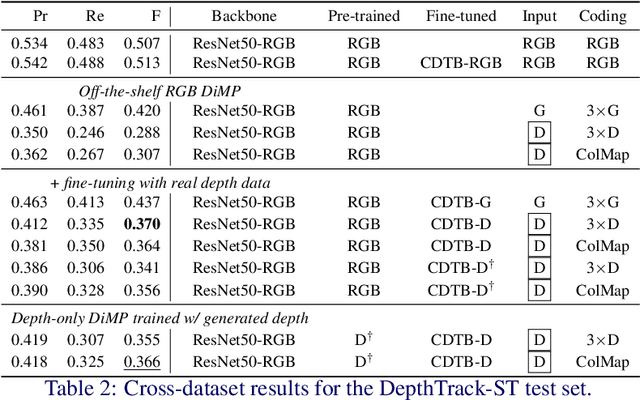
Depth (D) indicates occlusion and is less sensitive to illumination changes, which make depth attractive modality for Visual Object Tracking (VOT). Depth is used in RGBD object tracking where the best trackers are deep RGB trackers with additional heuristic using depth maps. There are two potential reasons for the heuristics: 1) the lack of large RGBD tracking datasets to train deep RGBD trackers and 2) the long-term evaluation protocol of VOT RGBD that benefits from heuristics such as depth-based occlusion detection. In this work, we study how far D-only tracking can go if trained with large amounts of depth data. To compensate the lack of depth data, we generate depth maps for tracking. We train a "Depth-DiMP" from the scratch with the generated data and fine-tune it with the available small RGBD tracking datasets. The depth-only DiMP achieves good accuracy in depth-only tracking and combined with the original RGB DiMP the end-to-end trained RGBD-DiMP outperforms the recent VOT 2020 RGBD winners.
Monolithic vs. hybrid controller for multi-objective Sim-to-Real learning
Aug 17, 2021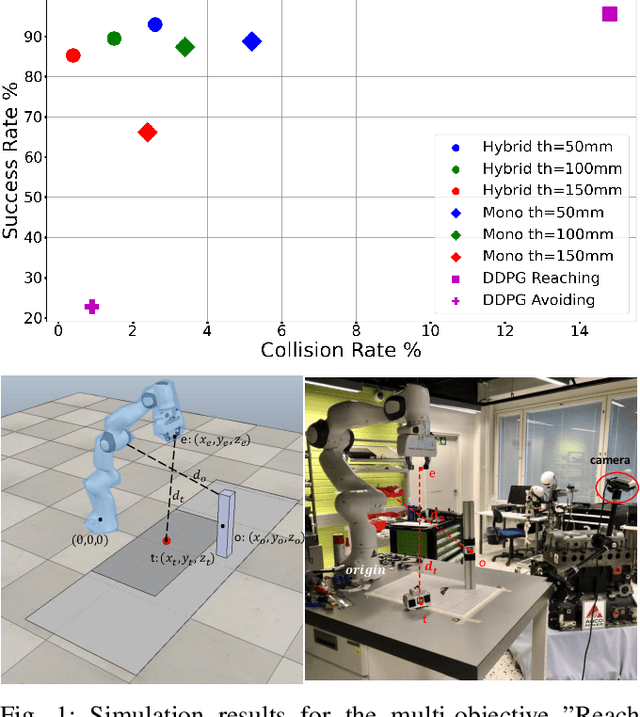
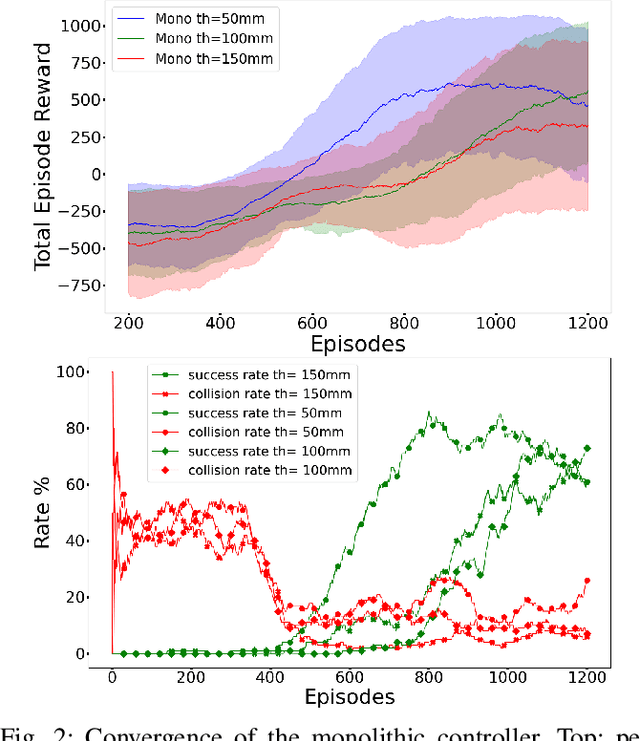
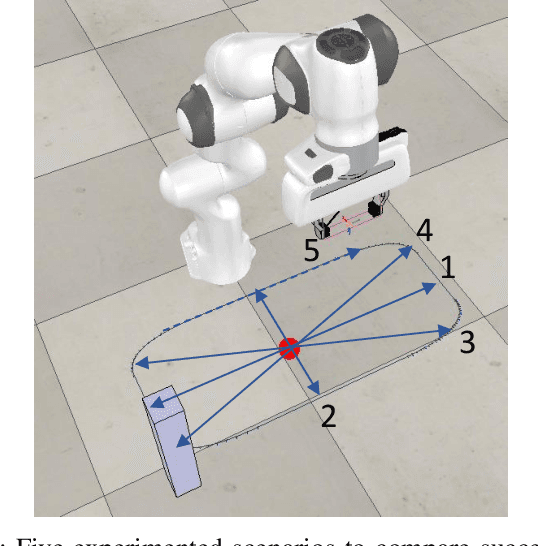

Simulation to real (Sim-to-Real) is an attractive approach to construct controllers for robotic tasks that are easier to simulate than to analytically solve. Working Sim-to-Real solutions have been demonstrated for tasks with a clear single objective such as "reach the target". Real world applications, however, often consist of multiple simultaneous objectives such as "reach the target" but "avoid obstacles". A straightforward solution in the context of reinforcement learning (RL) is to combine multiple objectives into a multi-term reward function and train a single monolithic controller. Recently, a hybrid solution based on pre-trained single objective controllers and a switching rule between them was proposed. In this work, we compare these two approaches in the multi-objective setting of a robot manipulator to reach a target while avoiding an obstacle. Our findings show that the training of a hybrid controller is easier and obtains a better success-failure trade-off than a monolithic controller. The controllers trained in simulator were verified by a real set-up.
Object Tracking by Reconstruction with View-Specific Discriminative Correlation Filters
Nov 27, 2018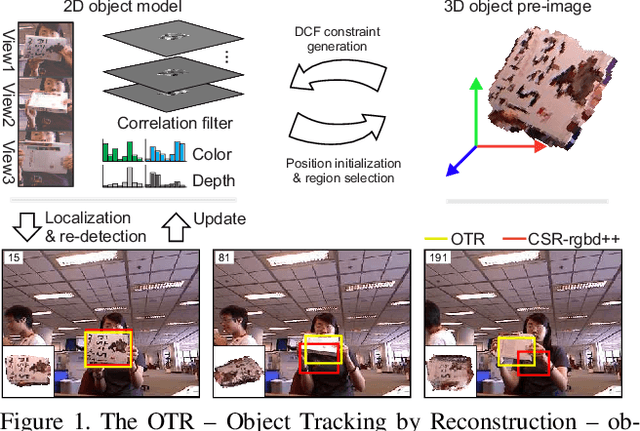
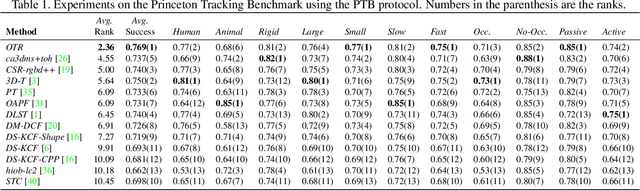
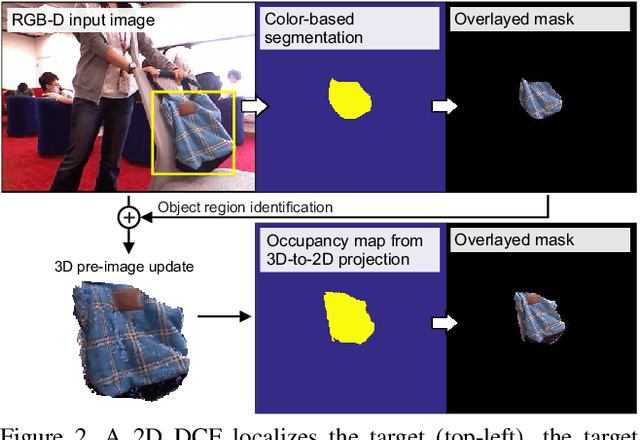
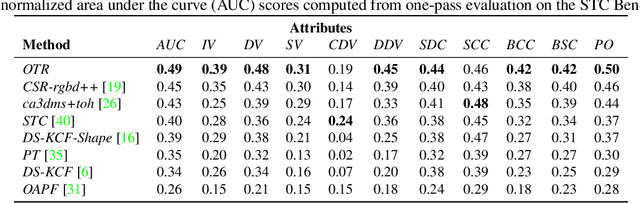
Standard RGB-D trackers treat the target as an inherently 2D structure, which makes modelling appearance changes related even to simple out-of-plane rotation highly challenging. We address this limitation by proposing a novel long-term RGB-D tracker - Object Tracking by Reconstruction (OTR). The tracker performs online 3D target reconstruction to facilitate robust learning of a set of view-specific discriminative correlation filters (DCFs). The 3D reconstruction supports two performance-enhancing features: (i) generation of accurate spatial support for constrained DCF learning from its 2D projection and (ii) point cloud based estimation of 3D pose change for selection and storage of view-specific DCFs which are used to robustly localize the target after out-of-view rotation or heavy occlusion. Extensive evaluation of OTR on the challenging Princeton RGB-D tracking and STC Benchmarks shows it outperforms the state-of-the-art by a large margin.
Object Detection in Equirectangular Panorama
May 21, 2018

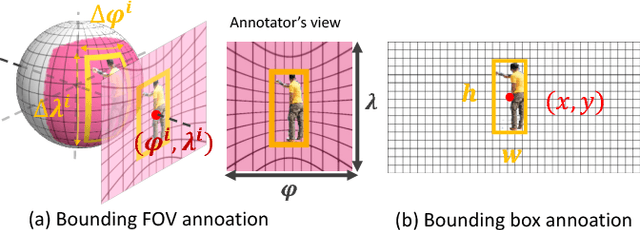
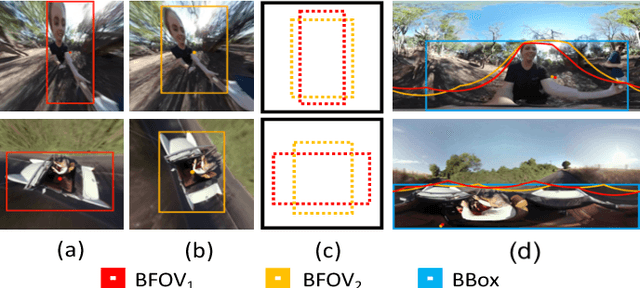
We introduced a high-resolution equirectangular panorama (360-degree, virtual reality) dataset for object detection and propose a multi-projection variant of YOLO detector. The main challenge with equirectangular panorama image are i) the lack of annotated training data, ii) high-resolution imagery and iii) severe geometric distortions of objects near the panorama projection poles. In this work, we solve the challenges by i) using training examples available in the "conventional datasets" (ImageNet and COCO), ii) employing only low-resolution images that require only moderate GPU computing power and memory, and iii) our multi-projection YOLO handles projection distortions by making multiple stereographic sub-projections. In our experiments, YOLO outperforms the other state-of-art detector, Faster RCNN and our multi-projection YOLO achieves the best accuracy with low-resolution input.
Pose Estimation using Local Structure-Specific Shape and Appearance Context
Aug 23, 2017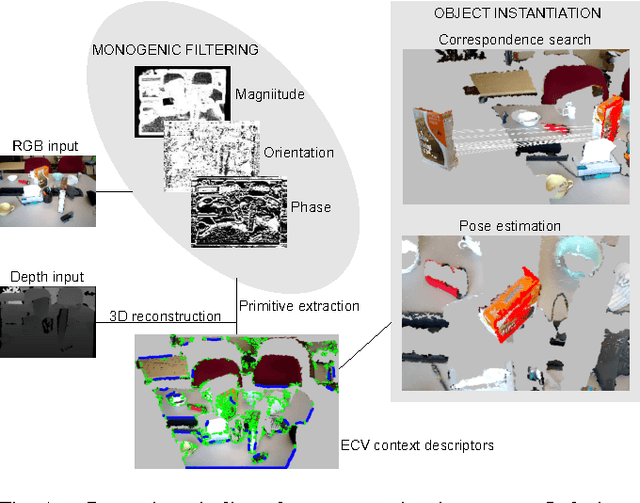

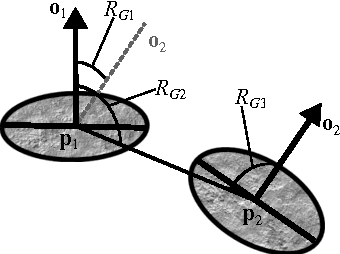
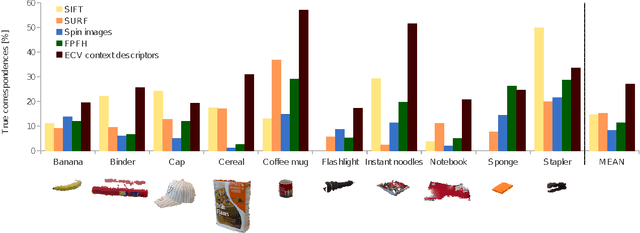
We address the problem of estimating the alignment pose between two models using structure-specific local descriptors. Our descriptors are generated using a combination of 2D image data and 3D contextual shape data, resulting in a set of semi-local descriptors containing rich appearance and shape information for both edge and texture structures. This is achieved by defining feature space relations which describe the neighborhood of a descriptor. By quantitative evaluations, we show that our descriptors provide high discriminative power compared to state of the art approaches. In addition, we show how to utilize this for the estimation of the alignment pose between two point sets. We present experiments both in controlled and real-life scenarios to validate our approach.
Deep Structured-Output Regression Learning for Computational Color Constancy
Aug 11, 2016
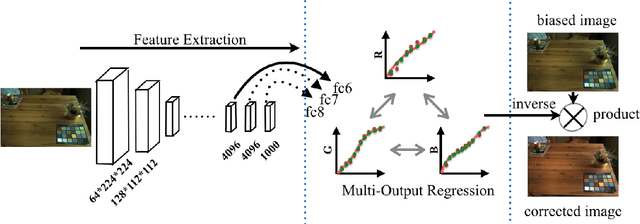


Computational color constancy that requires esti- mation of illuminant colors of images is a fundamental yet active problem in computer vision, which can be formulated into a regression problem. To learn a robust regressor for color constancy, obtaining meaningful imagery features and capturing latent correlations across output variables play a vital role. In this work, we introduce a novel deep structured-output regression learning framework to achieve both goals simultaneously. By borrowing the power of deep convolutional neural networks (CNN) originally designed for visual recognition, the proposed framework can automatically discover strong features for white balancing over different illumination conditions and learn a multi-output regressor beyond underlying relationships between features and targets to find the complex interdependence of dif- ferent dimensions of target variables. Experiments on two public benchmarks demonstrate that our method achieves competitive performance in comparison with the state-of-the-art approaches.