 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Randomness: Understand the Order of the Noise in Diffusion
Nov 11, 2025
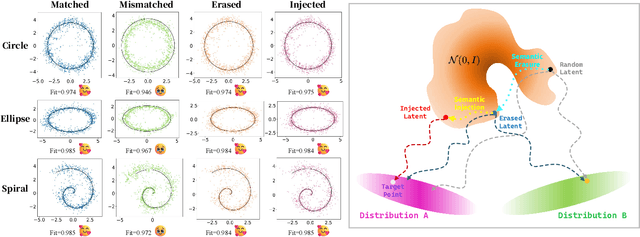


In text-driven content generation (T2C) diffusion model, semantic of generated content is mostly attributed to the process of text embedding and attention mechanism interaction. The initial noise of the generation process is typically characterized as a random element that contributes to the diversity of the generated content. Contrary to this view, this paper reveals that beneath the random surface of noise lies strong analyzable patterns. Specifically, this paper first conducts a comprehensive analysis of the impact of random noise on the model's generation. We found that noise not only contains rich semantic information, but also allows for the erasure of unwanted semantics from it in an extremely simple way based on information theory, and using the equivalence between the generation process of diffusion model and semantic injection to inject semantics into the cleaned noise. Then, we mathematically decipher these observations and propose a simple but efficient training-free and universal two-step "Semantic Erasure-Injection" process to modulate the initial noise in T2C diffusion model. Experimental results demonstrate that our method is consistently effective across various T2C models based on both DiT and UNet architectures and presents a novel perspective for optimizing the generation of diffusion model, providing a universal tool for consistent generation.
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.
ChatHaruhi: Reviving Anime Character in Reality via Large Language Model
Aug 18, 2023



Role-playing chatbots built on large language models have drawn interest, but better techniques are needed to enable mimicking specific fictional characters. We propose an algorithm that controls language models via an improved prompt and memories of the character extracted from scripts. We construct ChatHaruhi, a dataset covering 32 Chinese / English TV / anime characters with over 54k simulated dialogues. Both automatic and human evaluations show our approach improves role-playing ability over baselines. Code and data are available at https://github.com/LC1332/Chat-Haruhi-Suzumiya .
RGBD Object Tracking: An In-depth Review
Mar 26, 2022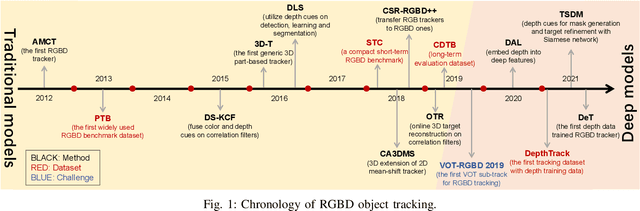
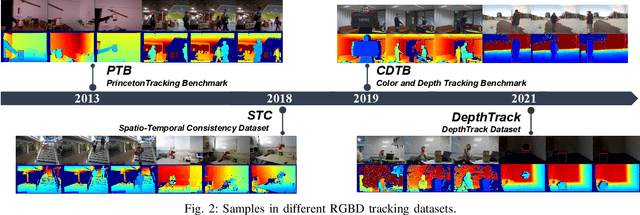
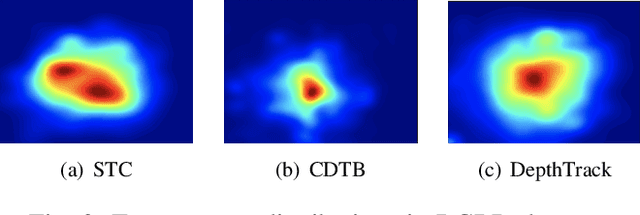
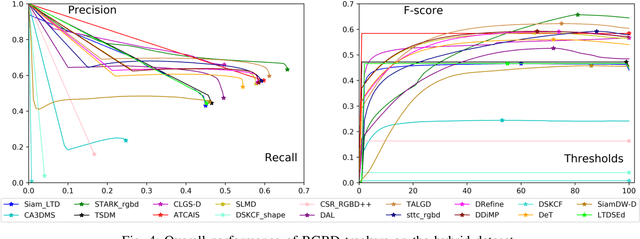
RGBD object tracking is gaining momentum in computer vision research thanks to the development of depth sensors. Although numerous RGBD trackers have been proposed with promising performance, an in-depth review for comprehensive understanding of this area is lacking. In this paper, we firstly review RGBD object trackers from different perspectives, including RGBD fusion, depth usage, and tracking framework. Then, we summarize the existing datasets and the evaluation metrics. We benchmark a representative set of RGBD trackers, and give detailed analyses based on their performances. Particularly, we are the first to provide depth quality evaluation and analysis of tracking results in depth-friendly scenarios in RGBD tracking. For long-term settings in most RGBD tracking videos, we give an analysis of trackers' performance on handling target disappearance. To enable better understanding of RGBD trackers, we propose robustness evaluation against input perturbations. Finally, we summarize the challenges and provide open directions for this community. All resources are publicly available at https://github.com/memoryunreal/RGBD-tracking-review.
Depth-only Object Tracking
Oct 22, 2021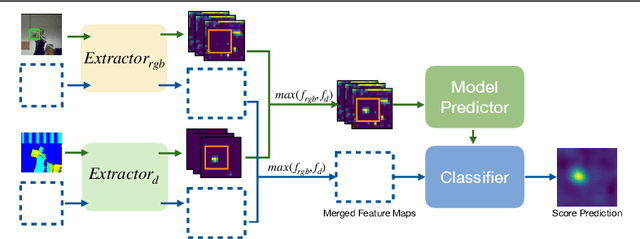
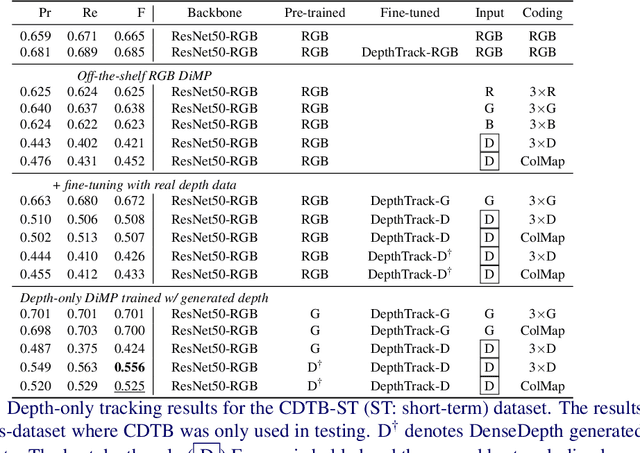

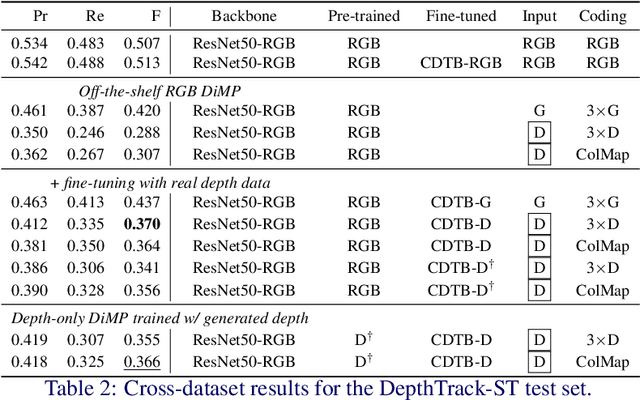
Depth (D) indicates occlusion and is less sensitive to illumination changes, which make depth attractive modality for Visual Object Tracking (VOT). Depth is used in RGBD object tracking where the best trackers are deep RGB trackers with additional heuristic using depth maps. There are two potential reasons for the heuristics: 1) the lack of large RGBD tracking datasets to train deep RGBD trackers and 2) the long-term evaluation protocol of VOT RGBD that benefits from heuristics such as depth-based occlusion detection. In this work, we study how far D-only tracking can go if trained with large amounts of depth data. To compensate the lack of depth data, we generate depth maps for tracking. We train a "Depth-DiMP" from the scratch with the generated data and fine-tune it with the available small RGBD tracking datasets. The depth-only DiMP achieves good accuracy in depth-only tracking and combined with the original RGB DiMP the end-to-end trained RGBD-DiMP outperforms the recent VOT 2020 RGBD winners.
DepthTrack : Unveiling the Power of RGBD Tracking
Aug 31, 2021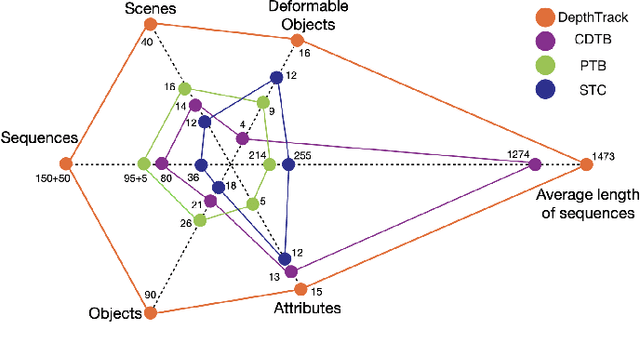
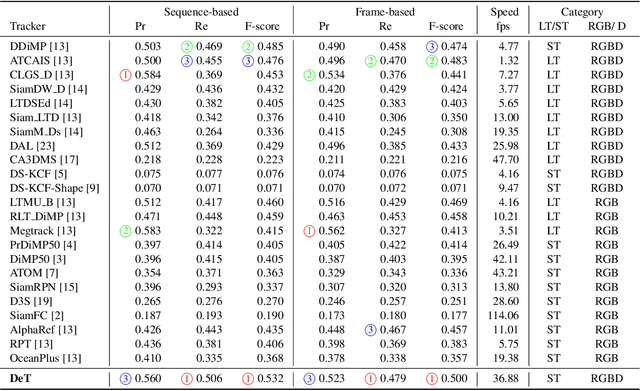

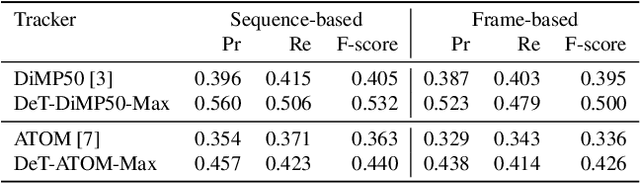
RGBD (RGB plus depth) object tracking is gaining momentum as RGBD sensors have become popular in many application fields such as robotics.However, the best RGBD trackers are extensions of the state-of-the-art deep RGB trackers. They are trained with RGB data and the depth channel is used as a sidekick for subtleties such as occlusion detection. This can be explained by the fact that there are no sufficiently large RGBD datasets to 1) train deep depth trackers and to 2) challenge RGB trackers with sequences for which the depth cue is essential. This work introduces a new RGBD tracking dataset - Depth-Track - that has twice as many sequences (200) and scene types (40) than in the largest existing dataset, and three times more objects (90). In addition, the average length of the sequences (1473), the number of deformable objects (16) and the number of annotated tracking attributes (15) have been increased. Furthermore, by running the SotA RGB and RGBD trackers on DepthTrack, we propose a new RGBD tracking baseline, namely DeT, which reveals that deep RGBD tracking indeed benefits from genuine training data. The code and dataset is available at https://github.com/xiaozai/DeT
Learning Anthropometry from Rendered Humans
Jan 07, 2021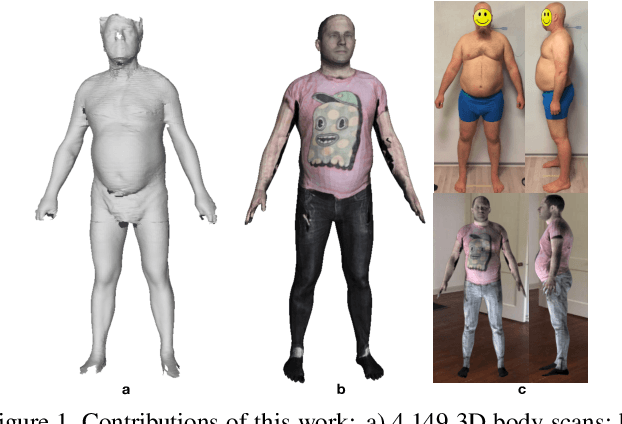



Accurate estimation of anthropometric body measurements from RGB images has many potential applications in industrial design, online clothing, medical diagnosis and ergonomics. Research on this topic is limited by the fact that there exist only generated datasets which are based on fitting a 3D body mesh to 3D body scans in the commercial CAESAR dataset. For 2D only silhouettes are generated. To circumvent the data bottleneck, we introduce a new 3D scan dataset of 2,675 female and 1,474 male scans. We also introduce a small dataset of 200 RGB images and tape measured ground truth. With the help of the two new datasets we propose a part-based shape model and a deep neural network for estimating anthropometric measurements from 2D images. All data will be made publicly available.
Anthropometric clothing measurements from 3D body scans
Nov 02, 2019
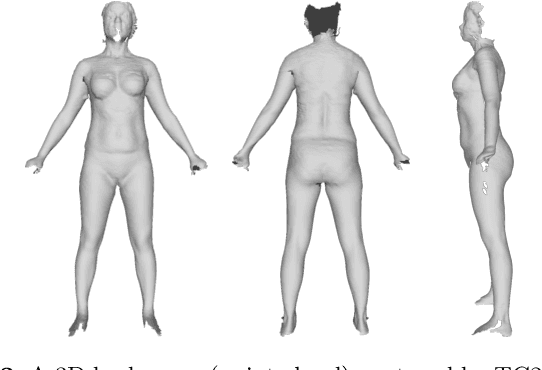

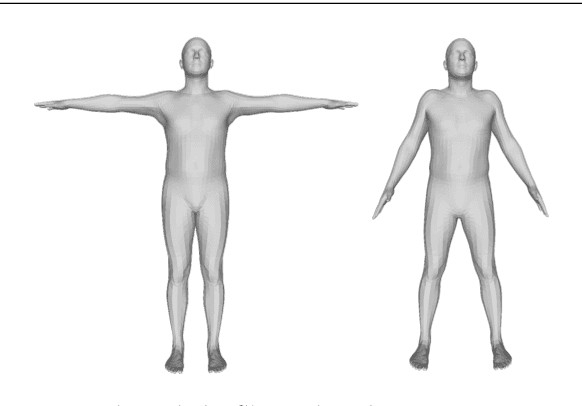
We propose a full processing pipeline to acquire anthropometric measurements from 3D measurements. The first stage of our pipeline is a commercial point cloud scanner. In the second stage, a pre-defined body model is fitted to the captured point cloud. We have generated one male and one female model from the SMPL library. The fitting process is based on non-rigid Iterative Closest Point (ICP) algorithm that minimizes overall energy of point distance and local stiffness energy terms. In the third stage, we measure multiple circumference paths on the fitted model surface and use a non-linear regressor to provide the final estimates of anthropometric measurements. We scanned 194 male and 181 female subjects and the proposed pipeline provides mean absolute errors from 2.5 mm to 16.0 mm depending on the anthropometric measurement.
Flash Lightens Gray Pixels
Feb 27, 2019



In the real world, a scene is usually cast by multiple illuminants and herein we address the problem of spatial illumination estimation. Our solution is based on detecting gray pixels with the help of flash photography. We show that flash photography significantly improves the performance of gray pixel detection without illuminant prior, training data or calibration of the flash. We also introduce a novel flash photography dataset generated from the MIT intrinsic dataset.