 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternVLA-A1: Unifying Understanding, Generation and Action for Robotic Manipulation
Jan 05, 2026Prevalent Vision-Language-Action (VLA) models are typically built upon Multimodal Large Language Models (MLLMs) and demonstrate exceptional proficiency in semantic understanding, but they inherently lack the capability to deduce physical world dynamics. Consequently, recent approaches have shifted toward World Models, typically formulated via video prediction; however, these methods often suffer from a lack of semantic grounding and exhibit brittleness when handling prediction errors. To synergize semantic understanding with dynamic predictive capabilities, we present InternVLA-A1. This model employs a unified Mixture-of-Transformers architecture, coordinating three experts for scene understanding, visual foresight generation, and action execution. These components interact seamlessly through a unified masked self-attention mechanism. Building upon InternVL3 and Qwen3-VL, we instantiate InternVLA-A1 at 2B and 3B parameter scales. We pre-train these models on hybrid synthetic-real datasets spanning InternData-A1 and Agibot-World, covering over 533M frames. This hybrid training strategy effectively harnesses the diversity of synthetic simulation data while minimizing the sim-to-real gap. We evaluated InternVLA-A1 across 12 real-world robotic tasks and simulation benchmark. It significantly outperforms leading models like pi0 and GR00T N1.5, achieving a 14.5\% improvement in daily tasks and a 40\%-73.3\% boost in dynamic settings, such as conveyor belt sorting.
Dino U-Net: Exploiting High-Fidelity Dense Features from Foundation Models for Medical Image Segmentation
Aug 28, 2025Foundation models pre-trained on large-scale natural image datasets offer a powerful paradigm for medical image segmentation. However, effectively transferring their learned representations for precise clinical applications remains a challenge. In this work, we propose Dino U-Net, a novel encoder-decoder architecture designed to exploit the high-fidelity dense features of the DINOv3 vision foundation model. Our architecture introduces an encoder built upon a frozen DINOv3 backbone, which employs a specialized adapter to fuse the model's rich semantic features with low-level spatial details. To preserve the quality of these representations during dimensionality reduction, we design a new fidelity-aware projection module (FAPM) that effectively refines and projects the features for the decoder. We conducted extensive experiments on seven diverse public medical image segmentation datasets. Our results show that Dino U-Net achieves state-of-the-art performance, consistently outperforming previous methods across various imaging modalities. Our framework proves to be highly scalable, with segmentation accuracy consistently improving as the backbone model size increases up to the 7-billion-parameter variant. The findings demonstrate that leveraging the superior, dense-pretrained features from a general-purpose foundation model provides a highly effective and parameter-efficient approach to advance the accuracy of medical image segmentation. The code is available at https://github.com/yifangao112/DinoUNet.
WeGA: Weakly-Supervised Global-Local Affinity Learning Framework for Lymph Node Metastasis Prediction in Rectal Cancer
May 15, 2025Accurate lymph node metastasis (LNM) assessment in rectal cancer is essential for treatment planning, yet current MRI-based evaluation shows unsatisfactory accuracy, leading to suboptimal clinical decisions. Developing automated systems also faces significant obstacles, primarily the lack of node-level annotations. Previous methods treat lymph nodes as isolated entities rather than as an interconnected system, overlooking valuable spatial and contextual information. To solve this problem, we present WeGA, a novel weakly-supervised global-local affinity learning framework that addresses these challenges through three key innovations: 1) a dual-branch architecture with DINOv2 backbone for global context and residual encoder for local node details; 2) a global-local affinity extractor that aligns features across scales through cross-attention fusion; and 3) a regional affinity loss that enforces structural coherence between classification maps and anatomical regions. Experiments across one internal and two external test centers demonstrate that WeGA outperforms existing methods, achieving AUCs of 0.750, 0.822, and 0.802 respectively. By effectively modeling the relationships between individual lymph nodes and their collective context, WeGA provides a more accurate and generalizable approach for lymph node metastasis prediction, potentially enhancing diagnostic precision and treatment selection for rectal cancer patients.
ABS-Mamba: SAM2-Driven Bidirectional Spiral Mamba Network for Medical Image Translation
May 12, 2025Accurate multi-modal medical image translation requires ha-rmonizing global anatomical semantics and local structural fidelity, a challenge complicated by intermodality information loss and structural distortion. We propose ABS-Mamba, a novel architecture integrating the Segment Anything Model 2 (SAM2) for organ-aware semantic representation, specialized convolutional neural networks (CNNs) for preserving modality-specific edge and texture details, and Mamba's selective state-space modeling for efficient long- and short-range feature dependencies. Structurally, our dual-resolution framework leverages SAM2's image encoder to capture organ-scale semantics from high-resolution inputs, while a parallel CNNs branch extracts fine-grained local features. The Robust Feature Fusion Network (RFFN) integrates these epresentations, and the Bidirectional Mamba Residual Network (BMRN) models spatial dependencies using spiral scanning and bidirectional state-space dynamics. A three-stage skip fusion decoder enhances edge and texture fidelity. We employ Efficient Low-Rank Adaptation (LoRA+) fine-tuning to enable precise domain specialization while maintaining the foundational capabilities of the pre-trained components. Extensive experimental validation on the SynthRAD2023 and BraTS2019 datasets demonstrates that ABS-Mamba outperforms state-of-the-art methods, delivering high-fidelity cross-modal synthesis that preserves anatomical semantics and structural details to enhance diagnostic accuracy in clinical applications. The code is available at https://github.com/gatina-yone/ABS-Mamba
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.
Semantic-Enhanced Relational Metric Learning for Recommender Systems
Jun 07, 2024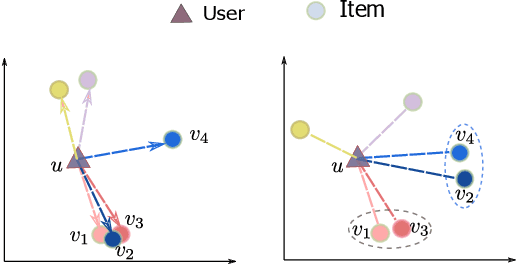
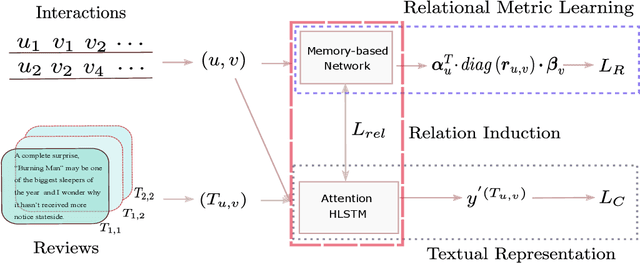


Recently, relational metric learning methods have been received great attention in recommendation community, which is inspired by the translation mechanism in knowledge graph. Different from the knowledge graph where the entity-to-entity relations are given in advance, historical interactions lack explicit relations between users and items in recommender systems. Currently, many researchers have succeeded in constructing the implicit relations to remit this issue. However, in previous work, the learning process of the induction function only depends on a single source of data (i.e., user-item interaction) in a supervised manner, resulting in the co-occurrence relation that is free of any semantic information. In this paper, to tackle the above problem in recommender systems, we propose a joint Semantic-Enhanced Relational Metric Learning (SERML) framework that incorporates the semantic information. Specifically, the semantic signal is first extracted from the target reviews containing abundant item features and personalized user preferences. A novel regression model is then designed via leveraging the extracted semantic signal to improve the discriminative ability of original relation-based training process. On four widely-used public datasets, experimental results demonstrate that SERML produces a competitive performance compared with several state-of-the-art methods in recommender systems.
A Hierarchical Dataflow-Driven Heterogeneous Architecture for Wireless Baseband Processing
Feb 28, 2024Wireless baseband processing (WBP) is a key element of wireless communications, with a series of signal processing modules to improve data throughput and counter channel fading. Conventional hardware solutions, such as digital signal processors (DSPs) and more recently, graphic processing units (GPUs), provide various degrees of parallelism, yet they both fail to take into account the cyclical and consecutive character of WBP. Furthermore, the large amount of data in WBPs cannot be processed quickly in symmetric multiprocessors (SMPs) due to the unpredictability of memory latency. To address this issue, we propose a hierarchical dataflow-driven architecture to accelerate WBP. A pack-and-ship approach is presented under a non-uniform memory access (NUMA) architecture to allow the subordinate tiles to operate in a bundled access and execute manner. We also propose a multi-level dataflow model and the related scheduling scheme to manage and allocate the heterogeneous hardware resources. Experiment results demonstrate that our prototype achieves $2\times$ and $2.3\times$ speedup in terms of normalized throughput and single-tile clock cycles compared with GPU and DSP counterparts in several critical WBP benchmarks. Additionally, a link-level throughput of $288$ Mbps can be achieved with a $45$-core configuration.
MAMO: Memory-Augmented Meta-Optimization for Cold-start Recommendation
Jul 07, 2020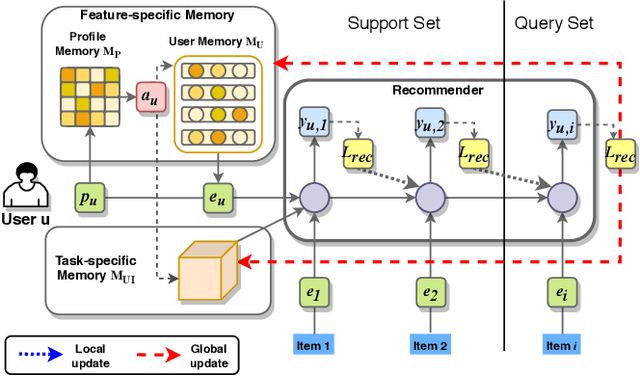
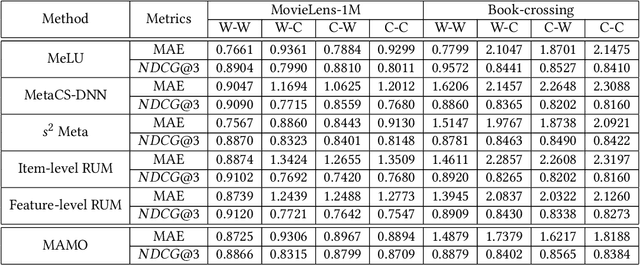
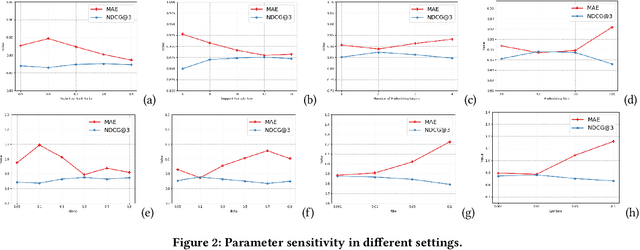
A common challenge for most current recommender systems is the cold-start problem. Due to the lack of user-item interactions, the fine-tuned recommender systems are unable to handle situations with new users or new items. Recently, some works introduce the meta-optimization idea into the recommendation scenarios, i.e. predicting the user preference by only a few of past interacted items. The core idea is learning a global sharing initialization parameter for all users and then learning the local parameters for each user separately. However, most meta-learning based recommendation approaches adopt model-agnostic meta-learning for parameter initialization, where the global sharing parameter may lead the model into local optima for some users. In this paper, we design two memory matrices that can store task-specific memories and feature-specific memories. Specifically, the feature-specific memories are used to guide the model with personalized parameter initialization, while the task-specific memories are used to guide the model fast predicting the user preference. And we adopt a meta-optimization approach for optimizing the proposed method. We test the model on two widely used recommendation datasets and consider four cold-start situations. The experimental results show the effectiveness of the proposed methods.
Trust in Recommender Systems: A Deep Learning Perspective
Apr 08, 2020
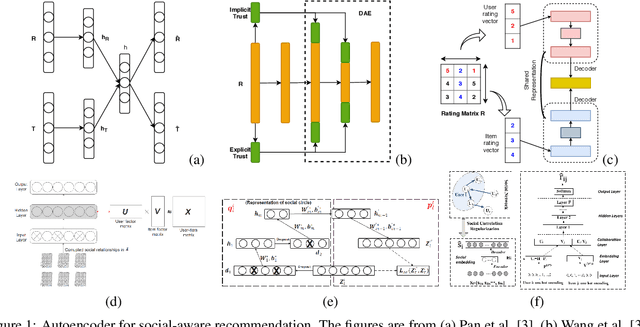

A significant remaining challenge for existing recommender systems is that users may not trust the recommender systems for either lack of explanation or inaccurate recommendation results. Thus, it becomes critical to embrace a trustworthy recommender system. This survey provides a systemic summary of three categories of trust-aware recommender systems: social-aware recommender systems that leverage users' social relationships; robust recommender systems that filter untruthful noises (e.g., spammers and fake information) or enhance attack resistance; explainable recommender systems that provide explanations of recommended items. We focus on the work based on deep learning techniques, an emerging area in the recommendation research.
DARec: Deep Domain Adaptation for Cross-Domain Recommendation via Transferring Rating Patterns
May 26, 2019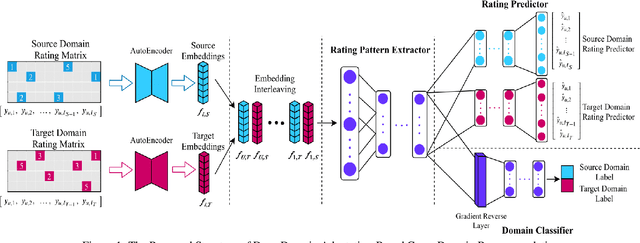

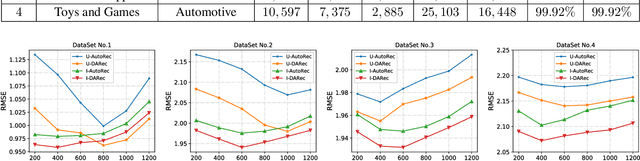
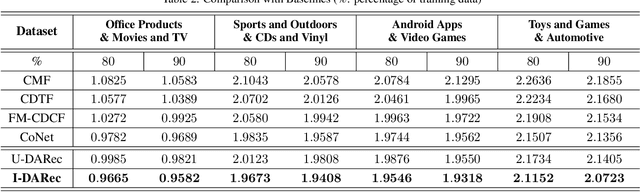
Cross-domain recommendation has long been one of the major topics in recommender systems. Recently, various deep models have been proposed to transfer the learned knowledge across domains, but most of them focus on extracting abstract transferable features from auxilliary contents, e.g., images and review texts, and the patterns in the rating matrix itself is rarely touched. In this work, inspired by the concept of domain adaptation, we proposed a deep domain adaptation model (DARec) that is capable of extracting and transferring patterns from rating matrices {\em only} without relying on any auxillary information. We empirically demonstrate on public datasets that our method achieves the best performance among several state-of-the-art alternative cross-domain recommendation models.