 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProcessGPT: Transforming Business Process Management with Generative Artificial Intelligence
May 29, 2023Generative Pre-trained Transformer (GPT) is a state-of-the-art machine learning model capable of generating human-like text through natural language processing (NLP). GPT is trained on massive amounts of text data and uses deep learning techniques to learn patterns and relationships within the data, enabling it to generate coherent and contextually appropriate text. This position paper proposes using GPT technology to generate new process models when/if needed. We introduce ProcessGPT as a new technology that has the potential to enhance decision-making in data-centric and knowledge-intensive processes. ProcessGPT can be designed by training a generative pre-trained transformer model on a large dataset of business process data. This model can then be fine-tuned on specific process domains and trained to generate process flows and make decisions based on context and user input. The model can be integrated with NLP and machine learning techniques to provide insights and recommendations for process improvement. Furthermore, the model can automate repetitive tasks and improve process efficiency while enabling knowledge workers to communicate analysis findings, supporting evidence, and make decisions. ProcessGPT can revolutionize business process management (BPM) by offering a powerful tool for process augmentation, automation and improvement. Finally, we demonstrate how ProcessGPT can be a powerful tool for augmenting data engineers in maintaining data ecosystem processes within large bank organizations. Our scenario highlights the potential of this approach to improve efficiency, reduce costs, and enhance the quality of business operations through the automation of data-centric and knowledge-intensive processes. These results underscore the promise of ProcessGPT as a transformative technology for organizations looking to improve their process workflows.
Crowdsourcing Diverse Paraphrases for Training Task-oriented Bots
Sep 20, 2021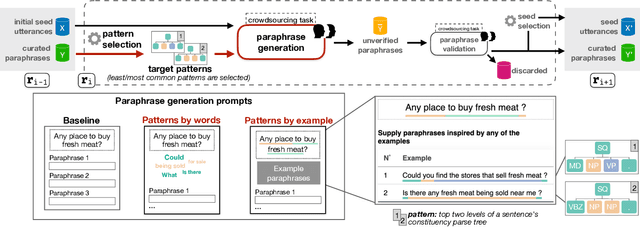
A prominent approach to build datasets for training task-oriented bots is crowd-based paraphrasing. Current approaches, however, assume the crowd would naturally provide diverse paraphrases or focus only on lexical diversity. In this WiP we addressed an overlooked aspect of diversity, introducing an approach for guiding the crowdsourcing process towards paraphrases that are syntactically diverse.
A Query Language for Summarizing and Analyzing Business Process Data
May 23, 2021
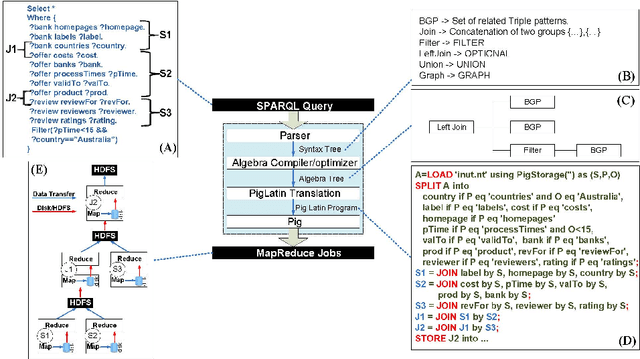
In modern enterprises, Business Processes (BPs) are realized over a mix of workflows, IT systems, Web services and direct collaborations of people. Accordingly, process data (i.e., BP execution data such as logs containing events, interaction messages and other process artifacts) is scattered across several systems and data sources, and increasingly show all typical properties of the Big Data. Understanding the execution of process data is challenging as key business insights remain hidden in the interactions among process entities: most objects are interconnected, forming complex, heterogeneous but often semi-structured networks. In the context of business processes, we consider the Big Data problem as a massive number of interconnected data islands from personal, shared and business data. We present a framework to model process data as graphs, i.e., Process Graph, and present abstractions to summarize the process graph and to discover concept hierarchies for entities based on both data objects and their interactions in process graphs. We present a language, namely BP-SPARQL, for the explorative querying and understanding of process graphs from various user perspectives. We have implemented a scalable architecture for querying, exploration and analysis of process graphs. We report on experiments performed on both synthetic and real-world datasets that show the viability and efficiency of the approach.
Automatic Generation of Chatbots for Conversational Web Browsing
Aug 19, 2020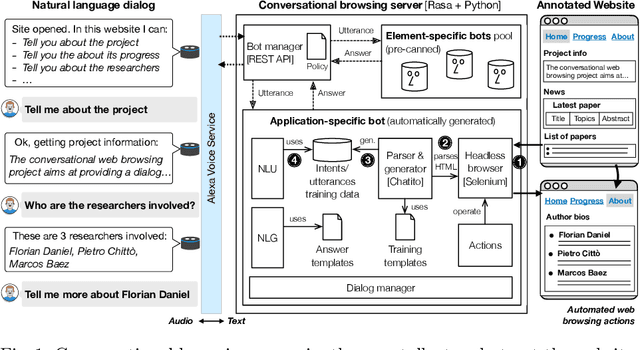
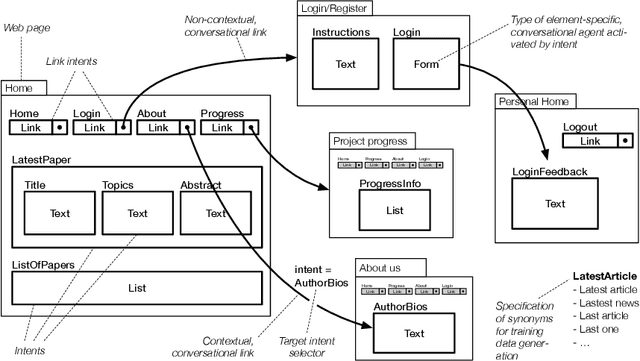

In this paper, we describe the foundations for generating a chatbot out of a website equipped with simple, bot-specific HTML annotations. The approach is part of what we call conversational web browsing, i.e., a dialog-based, natural language interaction with websites. The goal is to enable users to use content and functionality accessible through rendered UIs by "talking to websites" instead of by operating the graphical UI using keyboard and mouse. The chatbot mediates between the user and the website, operates its graphical UI on behalf of the user, and informs the user about the state of interaction. We describe the conceptual vocabulary and annotation format, the supporting conversational middleware and techniques, and the implementation of a demo able to deliver conversational web browsing experiences through Amazon Alexa.
DARec: Deep Domain Adaptation for Cross-Domain Recommendation via Transferring Rating Patterns
May 26, 2019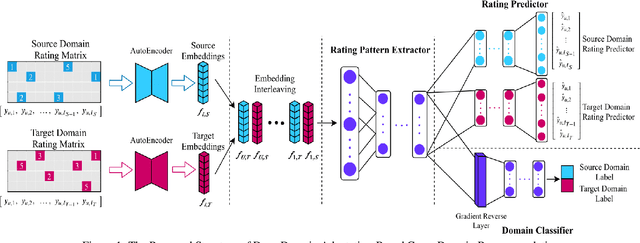

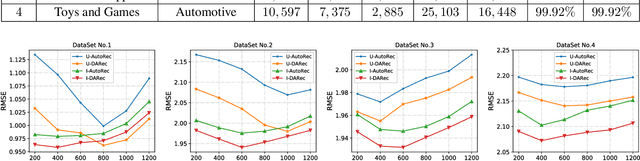
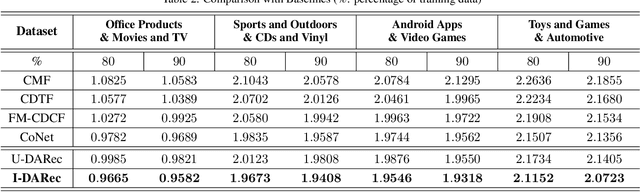
Cross-domain recommendation has long been one of the major topics in recommender systems. Recently, various deep models have been proposed to transfer the learned knowledge across domains, but most of them focus on extracting abstract transferable features from auxilliary contents, e.g., images and review texts, and the patterns in the rating matrix itself is rarely touched. In this work, inspired by the concept of domain adaptation, we proposed a deep domain adaptation model (DARec) that is capable of extracting and transferring patterns from rating matrices {\em only} without relying on any auxillary information. We empirically demonstrate on public datasets that our method achieves the best performance among several state-of-the-art alternative cross-domain recommendation models.
Combining Crowd and Machines for Multi-predicate Item Screening
Apr 01, 2019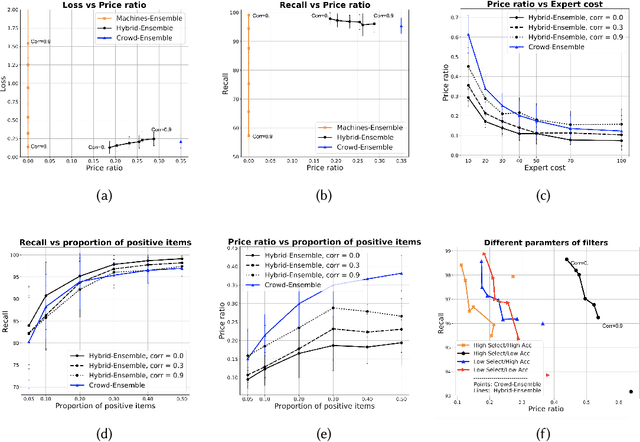

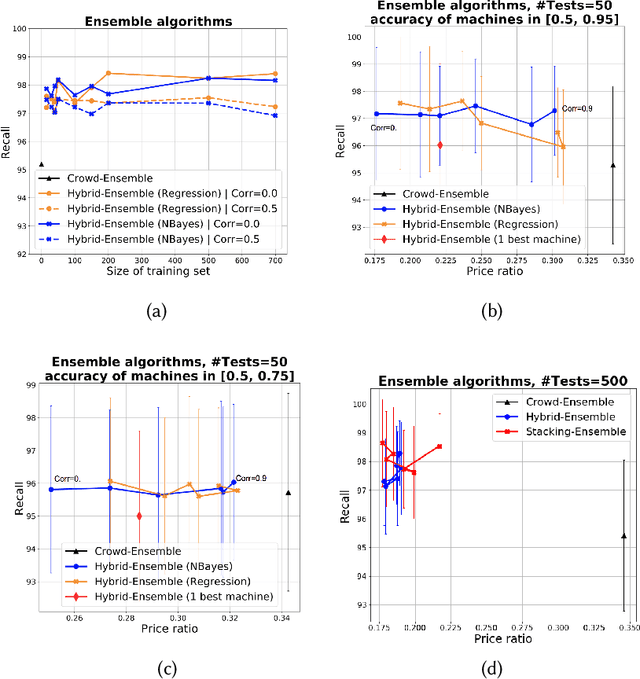
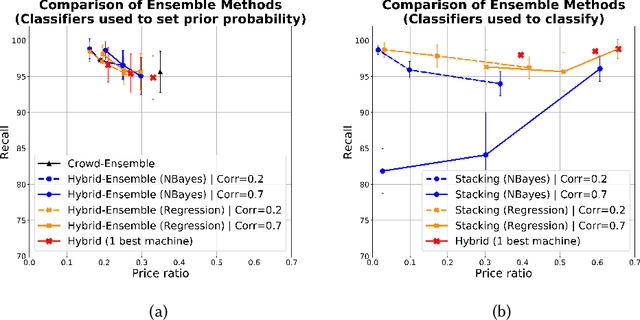
This paper discusses how crowd and machine classifiers can be efficiently combined to screen items that satisfy a set of predicates. We show that this is a recurring problem in many domains, present machine-human (hybrid) algorithms that screen items efficiently and estimate the gain over human-only or machine-only screening in terms of performance and cost. We further show how, given a new classification problem and a set of classifiers of unknown accuracy for the problem at hand, we can identify how to manage the cost-accuracy trade off by progressively determining if we should spend budget to obtain test data (to assess the accuracy of the given classifiers), or to train an ensemble of classifiers, or whether we should leverage the existing machine classifiers with the crowd, and in this case how to efficiently combine them based on their estimated characteristics to obtain the classification. We demonstrate that the techniques we propose obtain significant cost/accuracy improvements with respect to the leading classification algorithms.
GrCAN: Gradient Boost Convolutional Autoencoder with Neural Decision Forest
Jun 24, 2018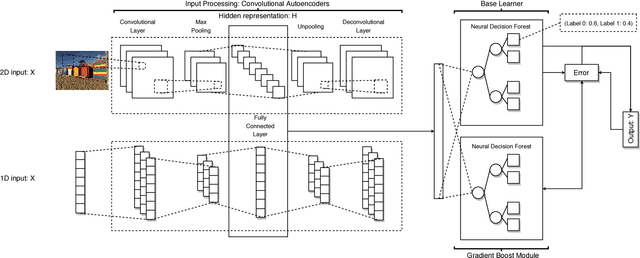


Random forest and deep neural network are two schools of effective classification methods in machine learning. While the random forest is robust irrespective of the data domain, the deep neural network has advantages in handling high dimensional data. In view that a differentiable neural decision forest can be added to the neural network to fully exploit the benefits of both models, in our work, we further combine convolutional autoencoder with neural decision forest, where autoencoder has its advantages in finding the hidden representations of the input data. We develop a gradient boost module and embed it into the proposed convolutional autoencoder with neural decision forest to improve the performance. The idea of gradient boost is to learn and use the residual in the prediction. In addition, we design a structure to learn the parameters of the neural decision forest and gradient boost module at contiguous steps. The extensive experiments on several public datasets demonstrate that our proposed model achieves good efficiency and prediction performance compared with a series of baseline methods.
A Unified Knowledge Representation and Context-aware Recommender System in Internet of Things
May 24, 2018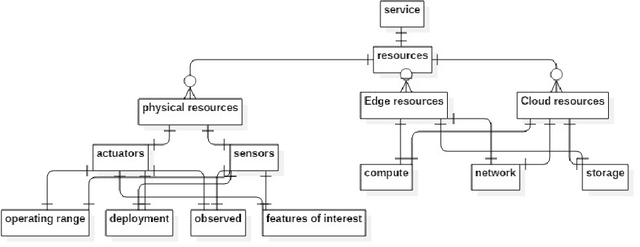
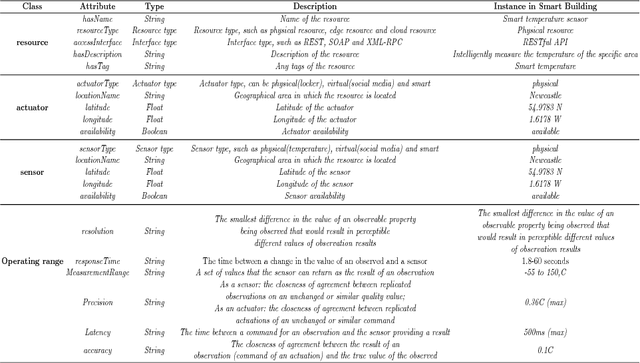
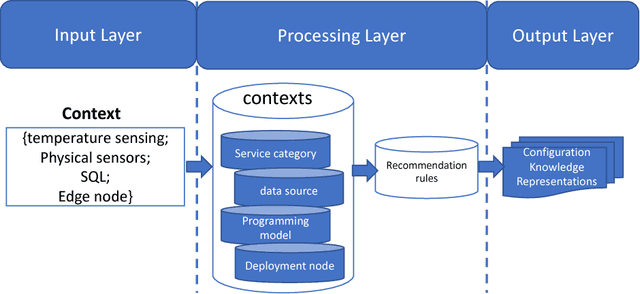
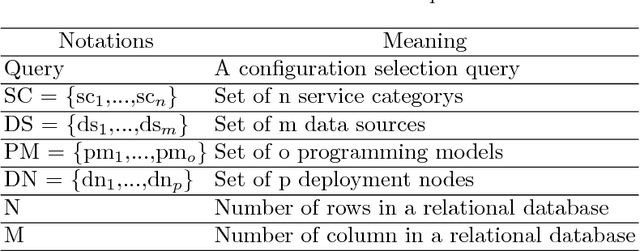
Within the rapidly developing Internet of Things (IoT), numerous and diverse physical devices, Edge devices, Cloud infrastructure, and their quality of service requirements (QoS), need to be represented within a unified specification in order to enable rapid IoT application development, monitoring, and dynamic reconfiguration. But heterogeneities among different configuration knowledge representation models pose limitations for acquisition, discovery and curation of configuration knowledge for coordinated IoT applications. This paper proposes a unified data model to represent IoT resource configuration knowledge artifacts. It also proposes IoT-CANE (Context-Aware recommendatioN systEm) to facilitate incremental knowledge acquisition and declarative context driven knowledge recommendation.
Opinion Fraud Detection via Neural Autoencoder Decision Forest
May 09, 2018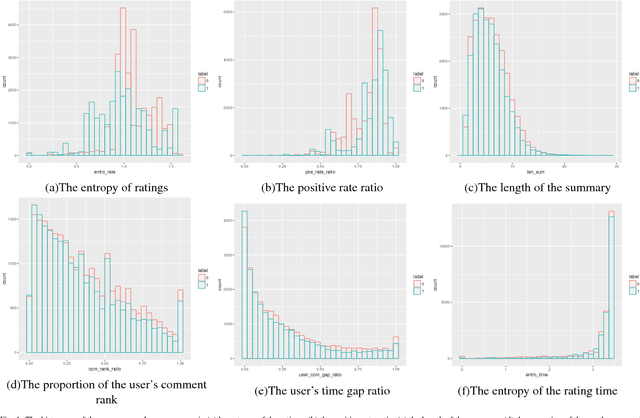
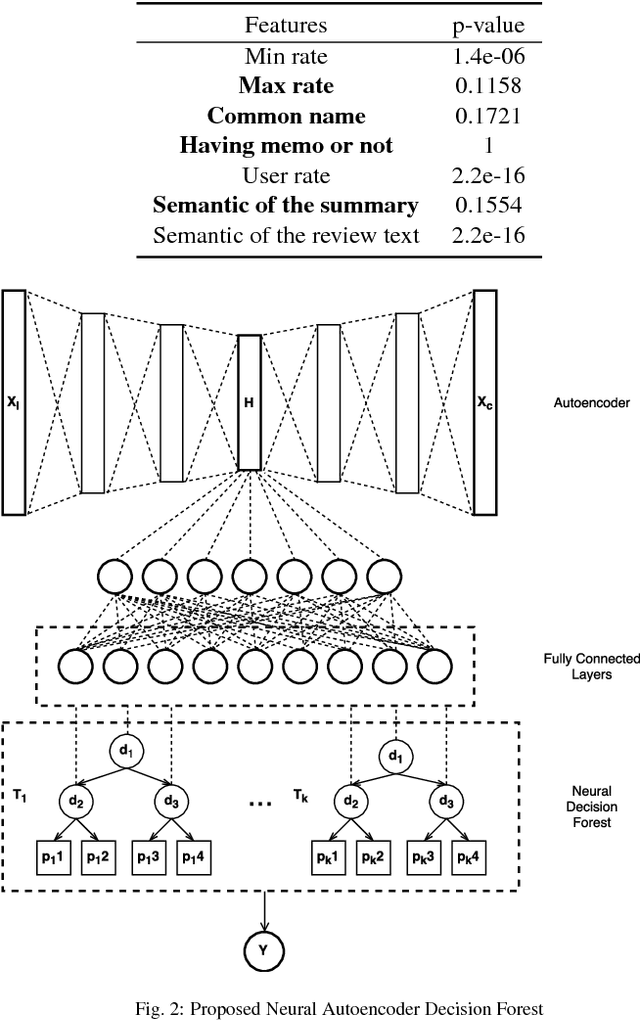

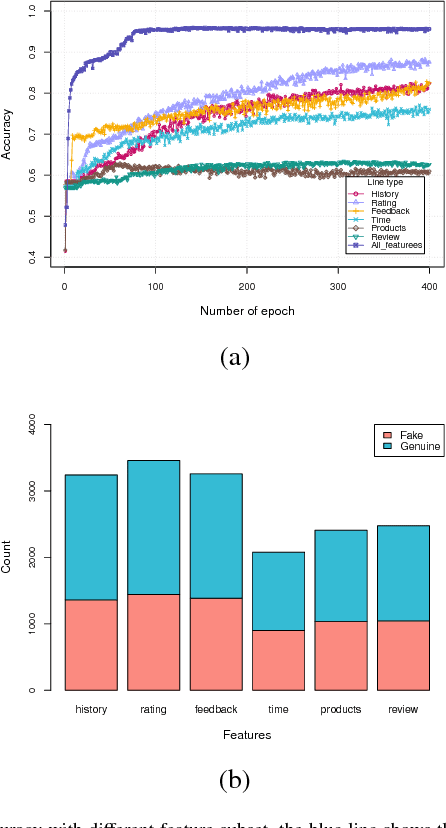
Online reviews play an important role in influencing buyers' daily purchase decisions. However, fake and meaningless reviews, which cannot reflect users' genuine purchase experience and opinions, widely exist on the Web and pose great challenges for users to make right choices. Therefore,it is desirable to build a fair model that evaluates the quality of products by distinguishing spamming reviews. We present an end-to-end trainable unified model to leverage the appealing properties from Autoencoder and random forest. A stochastic decision tree model is implemented to guide the global parameter learning process. Extensive experiments were conducted on a large Amazon review dataset. The proposed model consistently outperforms a series of compared methods.
Crowd-Machine Collaboration for Item Screening
Mar 21, 2018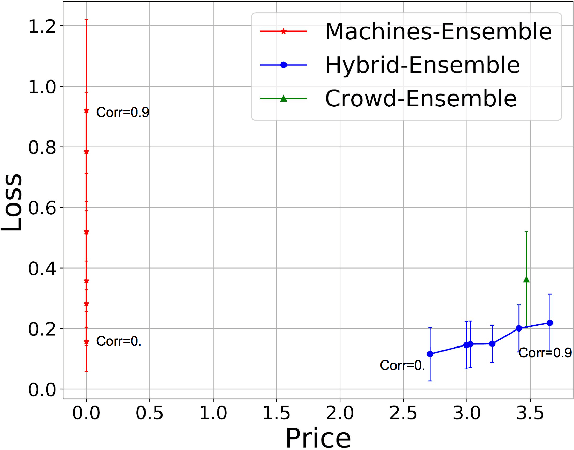
In this paper we describe how crowd and machine classifier can be efficiently combined to screen items that satisfy a set of predicates. We show that this is a recurring problem in many domains, present machine-human (hybrid) algorithms that screen items efficiently and estimate the gain over human-only or machine-only screening in terms of performance and cost.