 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Language Models for Agentic NetOps and AIOps: Architectures, Evaluation, and Safety
May 12, 2026Large language models are increasingly being used to support network operations (NetOps) and artificial intelligence for IT operations (AIOps), including incident investigation, root-cause analysis, configuration synthesis, and limited self-healing. In both NetOps and AIOps, this shift is changing how tasks are managed. Agent-based operations work as workflows, from gathering evidence to taking action, following permissions, policies, and checks, and providing rollback options when necessary. This is crucial because operational decisions can have instant impacts. To make the argument concrete, we organise the relevant literature around the hierarchy of autonomy, tool scope, evidence traces, and assurance contracts. These contracts define what an agent may observe, propose, and execute. They also define the checks that must pass before any action is allowed. A consistent pattern appears across work on telemetry query recommendation, diagnosis, root-cause analysis, configuration synthesis, change planning, and limited self-healing. Operational reliability does not come chiefly from the model itself. It depends on the machinery around the model. We also argue that evaluation should go beyond static question answering. Agentic NetOps and AIOps systems require workflow-centred evaluation, including trace quality, bounded tool use, safe proposal generation, replay in sandboxed environments, and canary trials with rollback-aware scoring. Without these measures, a system may appear robust yet remain too fragile. Finally, we examine security, privacy, and governance risks that become acute when agents sit close to operational control surfaces. Taken together, the survey concludes that progress in intelligent NetOps and AIOps will depend on treating autonomy as a constrained operational control problem, whose outputs must be reliable, auditable, and securely deployable.
DQ-Ladder: A Deep Reinforcement Learning-based Bitrate Ladder for Adaptive Video Streaming
Mar 13, 2026Adaptive streaming of segmented video over HTTP typically relies on a predefined set of bitrate-resolution pairs, known as a bitrate ladder. However, fixed ladders often overlook variations in content and decoding complexities, leading to suboptimal trade-offs between encoding time, decoding efficiency, and video quality. This article introduces DQ-Ladder, a deep reinforcement learning (DRL)-based scheme for constructing time- and quality-aware bitrate ladders for adaptive video streaming applications. DQ-Ladder employs predicted decoding time, quality scores, and bitrate levels per segment as inputs to a Deep Q-Network (DQN) agent, guided by a weighted reward function of decoding time, video quality, and resolution smoothness. We leverage machine learning models to predict decoding time, bitrate level, and objective quality metrics (VMAF, XPSNR), eliminating the need for exhaustive encoding or quality metric computation. We evaluate DQ-Ladder using the Versatile Video Coding (VVC) toolchain (VVenC/VVdeC) on 750 video sequences across six Apple HLS-compliant resolutions and 41 quantization parameters. Experimental results against four baselines show that DQ-Ladder achieves BD-rate reductions of at least 10.3% for XPSNR compared to the HLS ladder, while reducing decoding time by 22%. DQ-Ladder shows significantly lower sensitivity to prediction errors than competing methods, remaining robust even with up to 20% noise.
A Microservice-Based Platform for Sustainable and Intelligent SLO Fulfilment and Service Management
Feb 13, 2026The Microservices Architecture (MSA) design pattern has become a staple for modern applications, allowing functionalities to be divided across fine-grained microservices, fostering reusability, distribution, and interoperability. As MSA-based applications are deployed to the Computing Continuum (CC), meeting their Service Level Objectives (SLOs) becomes a challenge. Trading off performance and sustainability SLOs is especially challenging. This challenge can be addressed with intelligent decision systems, able to reconfigure the services during runtime to meet the SLOs. However, developing these agents while adhering to the MSA pattern is complex, especially because CC providers, who have key know-how and information to fulfill these SLOs, must comply with the privacy requirements of application developers. This work presents the Carbon-Aware SLO and Control plAtform (CASCA), an open-source MSA-based platform that allows CC providers to reconfigure services and fulfill their SLOs while maintaining the privacy of developers. CASCA is architected to be highly reusable, distributable, and easy to use, extend, and modify. CASCA has been evaluated in a real CC testbed for a media streaming service, where decision systems implemented in Bash, Rust, and Python successfully reconfigured the service, unaffected by upholding privacy.
Bio-inspired Agentic Self-healing Framework for Resilient Distributed Computing Continuum Systems
Jan 01, 2026Human biological systems sustain life through extraordinary resilience, continually detecting damage, orchestrating targeted responses, and restoring function through self-healing. Inspired by these capabilities, this paper introduces ReCiSt, a bio-inspired agentic self-healing framework designed to achieve resilience in Distributed Computing Continuum Systems (DCCS). Modern DCCS integrate heterogeneous computing resources, ranging from resource-constrained IoT devices to high-performance cloud infrastructures, and their inherent complexity, mobility, and dynamic operating conditions expose them to frequent faults that disrupt service continuity. These challenges underscore the need for scalable, adaptive, and self-regulated resilience strategies. ReCiSt reconstructs the biological phases of Hemostasis, Inflammation, Proliferation, and Remodeling into the computational layers Containment, Diagnosis, Meta-Cognitive, and Knowledge for DCCS. These four layers perform autonomous fault isolation, causal diagnosis, adaptive recovery, and long-term knowledge consolidation through Language Model (LM)-powered agents. These agents interpret heterogeneous logs, infer root causes, refine reasoning pathways, and reconfigure resources with minimal human intervention. The proposed ReCiSt framework is evaluated on public fault datasets using multiple LMs, and no baseline comparison is included due to the scarcity of similar approaches. Nevertheless, our results, evaluated under different LMs, confirm ReCiSt's self-healing capabilities within tens of seconds with minimum of 10% of agent CPU usage. Our results also demonstrated depth of analysis to over come uncertainties and amount of micro-agents invoked to achieve resilience.
Resilient by Design -- Active Inference for Distributed Continuum Intelligence
Nov 18, 2025Failures are the norm in highly complex and heterogeneous devices spanning the distributed computing continuum (DCC), from resource-constrained IoT and edge nodes to high-performance computing systems. Ensuring reliability and global consistency across these layers remains a major challenge, especially for AI-driven workloads requiring real-time, adaptive coordination. This work-in-progress paper introduces a Probabilistic Active Inference Resilience Agent (PAIR-Agent) to achieve resilience in DCC systems. PAIR-Agent performs three core operations: (i) constructing a causal fault graph from device logs, (ii) identifying faults while managing certainties and uncertainties using Markov blankets and the free energy principle, and (iii) autonomously healing issues through active inference. Through continuous monitoring and adaptive reconfiguration, the agent maintains service continuity and stability under diverse failure conditions. Theoretical validations confirm the reliability and effectiveness of the proposed framework.
BIPPO: Budget-Aware Independent PPO for Energy-Efficient Federated Learning Services
Nov 11, 2025Federated Learning (FL) is a promising machine learning solution in large-scale IoT systems, guaranteeing load distribution and privacy. However, FL does not natively consider infrastructure efficiency, a critical concern for systems operating in resource-constrained environments. Several Reinforcement Learning (RL) based solutions offer improved client selection for FL; however, they do not consider infrastructure challenges, such as resource limitations and device churn. Furthermore, the training of RL methods is often not designed for practical application, as these approaches frequently do not consider generalizability and are not optimized for energy efficiency. To fill this gap, we propose BIPPO (Budget-aware Independent Proximal Policy Optimization), which is an energy-efficient multi-agent RL solution that improves performance. We evaluate BIPPO on two image classification tasks run in a highly budget-constrained setting, with FL clients training on non-IID data, a challenging context for vanilla FL. The improved sampler of BIPPO enables it to increase the mean accuracy compared to non-RL mechanisms, traditional PPO, and IPPO. In addition, BIPPO only consumes a negligible proportion of the budget, which stays consistent even if the number of clients increases. Overall, BIPPO delivers a performant, stable, scalable, and sustainable solution for client selection in IoT-FL.
Multi-Dimensional Autoscaling of Stream Processing Services on Edge Devices
Oct 08, 2025
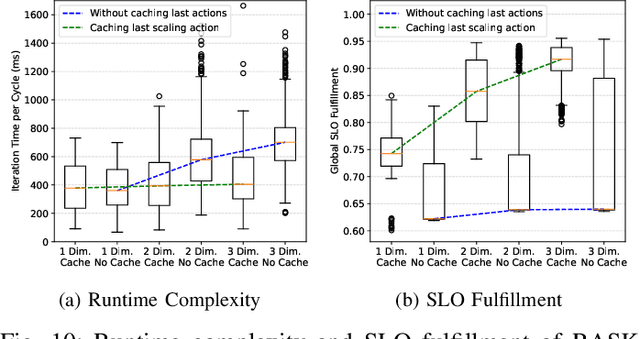
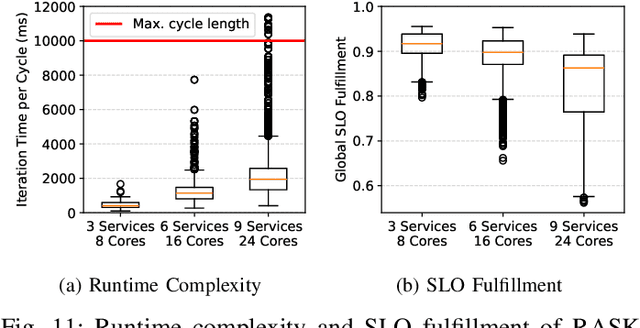

Edge devices have limited resources, which inevitably leads to situations where stream processing services cannot satisfy their needs. While existing autoscaling mechanisms focus entirely on resource scaling, Edge devices require alternative ways to sustain the Service Level Objectives (SLOs) of competing services. To address these issues, we introduce a Multi-dimensional Autoscaling Platform (MUDAP) that supports fine-grained vertical scaling across both service- and resource-level dimensions. MUDAP supports service-specific scaling tailored to available parameters, e.g., scale data quality or model size for a particular service. To optimize the execution across services, we present a scaling agent based on Regression Analysis of Structural Knowledge (RASK). The RASK agent efficiently explores the solution space and learns a continuous regression model of the processing environment for inferring optimal scaling actions. We compared our approach with two autoscalers, the Kubernetes VPA and a reinforcement learning agent, for scaling up to 9 services on a single Edge device. Our results showed that RASK can infer an accurate regression model in merely 20 iterations (i.e., observe 200s of processing). By increasingly adding elasticity dimensions, RASK sustained the highest request load with 28% less SLO violations, compared to baselines.
Edge Intelligence with Spiking Neural Networks
Jul 18, 2025The convergence of artificial intelligence and edge computing has spurred growing interest in enabling intelligent services directly on resource-constrained devices. While traditional deep learning models require significant computational resources and centralized data management, the resulting latency, bandwidth consumption, and privacy concerns have exposed critical limitations in cloud-centric paradigms. Brain-inspired computing, particularly Spiking Neural Networks (SNNs), offers a promising alternative by emulating biological neuronal dynamics to achieve low-power, event-driven computation. This survey provides a comprehensive overview of Edge Intelligence based on SNNs (EdgeSNNs), examining their potential to address the challenges of on-device learning, inference, and security in edge scenarios. We present a systematic taxonomy of EdgeSNN foundations, encompassing neuron models, learning algorithms, and supporting hardware platforms. Three representative practical considerations of EdgeSNN are discussed in depth: on-device inference using lightweight SNN models, resource-aware training and updating under non-stationary data conditions, and secure and privacy-preserving issues. Furthermore, we highlight the limitations of evaluating EdgeSNNs on conventional hardware and introduce a dual-track benchmarking strategy to support fair comparisons and hardware-aware optimization. Through this study, we aim to bridge the gap between brain-inspired learning and practical edge deployment, offering insights into current advancements, open challenges, and future research directions. To the best of our knowledge, this is the first dedicated and comprehensive survey on EdgeSNNs, providing an essential reference for researchers and practitioners working at the intersection of neuromorphic computing and edge intelligence.
Multi-dimensional Autoscaling of Processing Services: A Comparison of Agent-based Methods
Jun 12, 2025Edge computing breaks with traditional autoscaling due to strict resource constraints, thus, motivating more flexible scaling behaviors using multiple elasticity dimensions. This work introduces an agent-based autoscaling framework that dynamically adjusts both hardware resources and internal service configurations to maximize requirements fulfillment in constrained environments. We compare four types of scaling agents: Active Inference, Deep Q Network, Analysis of Structural Knowledge, and Deep Active Inference, using two real-world processing services running in parallel: YOLOv8 for visual recognition and OpenCV for QR code detection. Results show all agents achieve acceptable SLO performance with varying convergence patterns. While the Deep Q Network benefits from pre-training, the structural analysis converges quickly, and the deep active inference agent combines theoretical foundations with practical scalability advantages. Our findings provide evidence for the viability of multi-dimensional agent-based autoscaling for edge environments and encourage future work in this research direction.
A Trustworthy Multi-LLM Network: Challenges,Solutions, and A Use Case
May 06, 2025Large Language Models (LLMs) demonstrate strong potential across a variety of tasks in communications and networking due to their advanced reasoning capabilities. However, because different LLMs have different model structures and are trained using distinct corpora and methods, they may offer varying optimization strategies for the same network issues. Moreover, the limitations of an individual LLM's training data, aggravated by the potential maliciousness of its hosting device, can result in responses with low confidence or even bias. To address these challenges, we propose a blockchain-enabled collaborative framework that connects multiple LLMs into a Trustworthy Multi-LLM Network (MultiLLMN). This architecture enables the cooperative evaluation and selection of the most reliable and high-quality responses to complex network optimization problems. Specifically, we begin by reviewing related work and highlighting the limitations of existing LLMs in collaboration and trust, emphasizing the need for trustworthiness in LLM-based systems. We then introduce the workflow and design of the proposed Trustworthy MultiLLMN framework. Given the severity of False Base Station (FBS) attacks in B5G and 6G communication systems and the difficulty of addressing such threats through traditional modeling techniques, we present FBS defense as a case study to empirically validate the effectiveness of our approach. Finally, we outline promising future research directions in this emerging area.