 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning in Chaos: Efficient Autoscaling and Self-healing for Distributed Training at the Edge
May 19, 2025Frequent node and link changes in edge AI clusters disrupt distributed training, while traditional checkpoint-based recovery and cloud-centric autoscaling are too slow for scale-out and ill-suited to chaotic and self-governed edge. This paper proposes Chaos, a resilient and scalable edge distributed training system with built-in self-healing and autoscaling. It speeds up scale-out by using multi-neighbor replication with fast shard scheduling, allowing a new node to pull the latest training state from nearby neighbors in parallel while balancing the traffic load between them. It also uses a cluster monitor to track resource and topology changes to assist scheduler decisions, and handles scaling events through peer negotiation protocols, enabling fully self-governed autoscaling without a central admin. Extensive experiments show that Chaos consistently achieves much lower scale-out delays than Pollux, EDL, and Autoscaling, and handles scale-in, connect-link, and disconnect-link events within 1 millisecond, making it smoother to handle node joins, exits, and failures. It also delivers the lowest idle time, showing superior resource use and scalability as the cluster grows.
A Trustworthy Multi-LLM Network: Challenges,Solutions, and A Use Case
May 06, 2025Large Language Models (LLMs) demonstrate strong potential across a variety of tasks in communications and networking due to their advanced reasoning capabilities. However, because different LLMs have different model structures and are trained using distinct corpora and methods, they may offer varying optimization strategies for the same network issues. Moreover, the limitations of an individual LLM's training data, aggravated by the potential maliciousness of its hosting device, can result in responses with low confidence or even bias. To address these challenges, we propose a blockchain-enabled collaborative framework that connects multiple LLMs into a Trustworthy Multi-LLM Network (MultiLLMN). This architecture enables the cooperative evaluation and selection of the most reliable and high-quality responses to complex network optimization problems. Specifically, we begin by reviewing related work and highlighting the limitations of existing LLMs in collaboration and trust, emphasizing the need for trustworthiness in LLM-based systems. We then introduce the workflow and design of the proposed Trustworthy MultiLLMN framework. Given the severity of False Base Station (FBS) attacks in B5G and 6G communication systems and the difficulty of addressing such threats through traditional modeling techniques, we present FBS defense as a case study to empirically validate the effectiveness of our approach. Finally, we outline promising future research directions in this emerging area.
Cluster-Based Multi-Agent Task Scheduling for Space-Air-Ground Integrated Networks
Dec 14, 2024



The Space-Air-Ground Integrated Network (SAGIN) framework is a crucial foundation for future networks, where satellites and aerial nodes assist in computational task offloading. The low-altitude economy, leveraging the flexibility and multifunctionality of Unmanned Aerial Vehicles (UAVs) in SAGIN, holds significant potential for development in areas such as communication and sensing. However, effective coordination is needed to streamline information exchange and enable efficient system resource allocation. In this paper, we propose a Clustering-based Multi-agent Deep Deterministic Policy Gradient (CMADDPG) algorithm to address the multi-UAV cooperative task scheduling challenges in SAGIN. The CMADDPG algorithm leverages dynamic UAV clustering to partition UAVs into clusters, each managed by a Cluster Head (CH) UAV, facilitating a distributed-centralized control approach. Within each cluster, UAVs delegate offloading decisions to the CH UAV, reducing intra-cluster communication costs and decision conflicts, thereby enhancing task scheduling efficiency. Additionally, by employing a multi-agent reinforcement learning framework, the algorithm leverages the extensive coverage of satellites to achieve centralized training and distributed execution of multi-agent tasks, while maximizing overall system profit through optimized task offloading decision-making. Simulation results reveal that the CMADDPG algorithm effectively optimizes resource allocation, minimizes queue delays, maintains balanced load distribution, and surpasses existing methods by achieving at least a 25\% improvement in system profit, showcasing its robustness and adaptability across diverse scenarios.
TPI-LLM: Serving 70B-scale LLMs Efficiently on Low-resource Edge Devices
Oct 01, 2024



Large model inference is shifting from cloud to edge due to concerns about the privacy of user interaction data. However, edge devices often struggle with limited computing power, memory, and bandwidth, requiring collaboration across multiple devices to run and speed up LLM inference. Pipeline parallelism, the mainstream solution, is inefficient for single-user scenarios, while tensor parallelism struggles with frequent communications. In this paper, we argue that tensor parallelism can be more effective than pipeline on low-resource devices, and present a compute- and memory-efficient tensor parallel inference system, named TPI-LLM, to serve 70B-scale models. TPI-LLM keeps sensitive raw data local in the users' devices and introduces a sliding window memory scheduler to dynamically manage layer weights during inference, with disk I/O latency overlapped with the computation and communication. This allows larger models to run smoothly on memory-limited devices. We analyze the communication bottleneck and find that link latency, not bandwidth, emerges as the main issue, so a star-based allreduce algorithm is implemented. Through extensive experiments on both emulated and real testbeds, TPI-LLM demonstrated over 80% less time-to-first-token and token latency compared to Accelerate, and over 90% compared to Transformers and Galaxy, while cutting the peak memory footprint of Llama 2-70B by 90%, requiring only 3.1 GB of memory for 70B-scale models.
Convergence of Symbiotic Communications and Blockchain for Sustainable and Trustworthy 6G Wireless Networks
Aug 11, 2024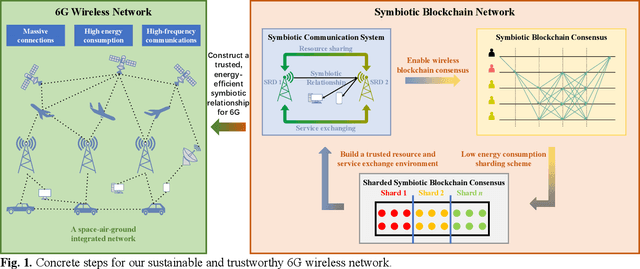
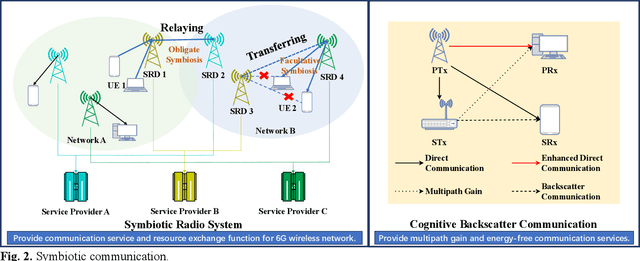
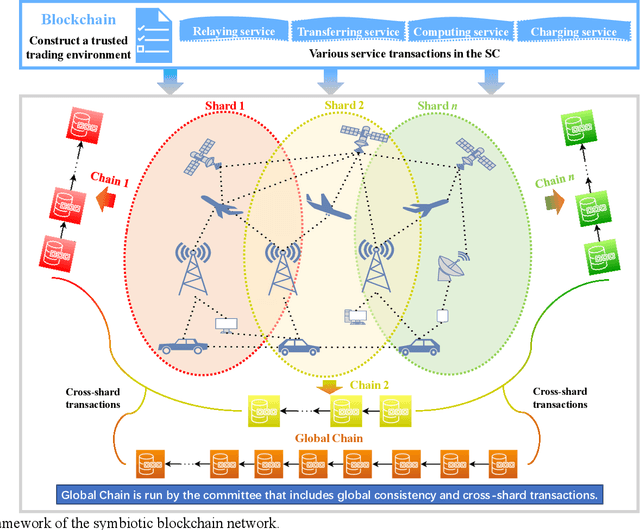
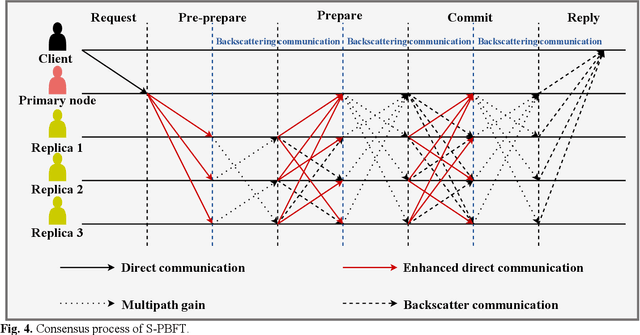
Symbiotic communication (SC) is known as a new wireless communication paradigm, similar to the natural ecosystem population, and can enable multiple communication systems to cooperate and mutualize through service exchange and resource sharing. As a result, SC is seen as an important potential technology for future sixth-generation (6G) communications, solving the problem of lack of spectrum resources and energy inefficiency. Symbiotic relationships among communication systems can complement radio resources in 6G. However, the absence of established trust relationships among diverse communication systems presents a formidable hurdle in ensuring efficient and trusted resource and service exchange within SC frameworks. To better realize trusted SC services in 6G, in this paper, we propose a solution that converges SC and blockchain, called a symbiotic blockchain network (SBN). Specifically, we first use cognitive backscatter communication to transform blockchain consensus, that is, the symbiotic blockchain consensus (SBC), so that it can be better suited for the wireless network. Then, for SBC, we propose a highly energy-efficient sharding scheme to meet the extremely low power consumption requirements in 6G. Finally, such a blockchain scheme guarantees trusted transactions of communication services in SC. Through ablation experiments, our proposed SBN demonstrates significant efficacy in mitigating energy consumption and reducing processing latency in adversarial networks, which is expected to achieve a sustainable and trusted 6G wireless network.
Information-Theoretic Generalization Analysis for Topology-aware Heterogeneous Federated Edge Learning over Noisy Channels
Oct 25, 2023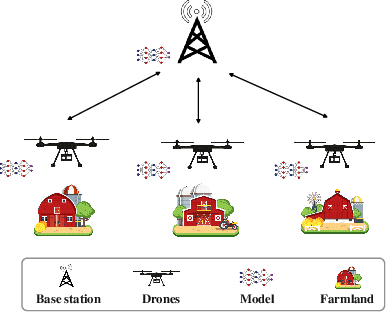
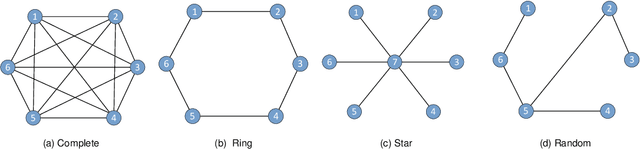
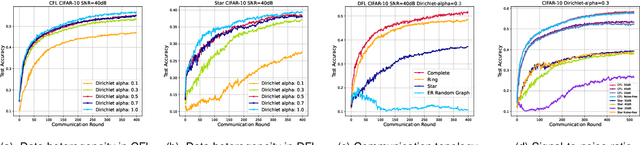
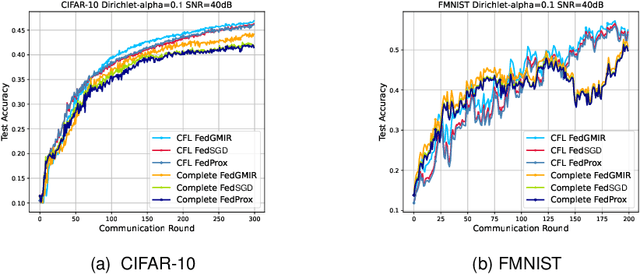
With the rapid growth of edge intelligence, the deployment of federated learning (FL) over wireless networks has garnered increasing attention, which is called Federated Edge Learning (FEEL). In FEEL, both mobile devices transmitting model parameters over noisy channels and collecting data in diverse environments pose challenges to the generalization of trained models. Moreover, devices can engage in decentralized FL via Device-to-Device communication while the communication topology of connected devices also impacts the generalization of models. Most recent theoretical studies overlook the incorporation of all these effects into FEEL when developing generalization analyses. In contrast, our work presents an information-theoretic generalization analysis for topology-aware FEEL in the presence of data heterogeneity and noisy channels. Additionally, we propose a novel regularization method called Federated Global Mutual Information Reduction (FedGMIR) to enhance the performance of models based on our analysis. Numerical results validate our theoretical findings and provide evidence for the effectiveness of the proposed method.
ESCM: An Efficient and Secure Communication Mechanism for UAV Networks
Apr 26, 2023



UAV (unmanned aerial vehicle) is gradually entering various human activities. It has also become an important part of satellite-air-ground-sea integrated network (SAGS) for 6G communication. In order to achieve high mobility, UAV has strict requirements on communication latency, and it cannot be illegally controlled as weapons of attack with malicious intentions. Therefore, an efficient and secure communication method specifically designed for UAV network is required. This paper proposes a communication mechanism named ESCM for the above requirements. For high efficiency of communication, ESCM designs a routing protocol based on artificial bee colony algorithm (ABC) for UAV network to accelerate communication between UAVs. Meanwhile, we plan to use blockchain to guarantee the communication security of UAV networks. However, blockchain has unstable links in high mobility network scenarios, resulting in low consensus efficiency and high communication overhead. Therefore, ESCM also introduces the concept of the digital twin, mapping the UAVs from the physical world into Cyberspace, transforming the UAV network into a static network. And this virtual UAV network is called CyberUAV. Then, in CyberUAV, we design a blockchain system and propose a consensus algorithm based on network coding, named proof of network coding (PoNC). PoNC not only ensures the security of ESCM, but also further improves the performance of ESCM through network coding. Simulation results show that ESCM has obvious advantages in communication efficiency and security. Moreover, encoding messages through PoNC consensus can increase the network throughput, and make mobile blockchain static through digital twin can improve the consensus success rate.
Performance Analysis and Comparison of Non-ideal Wireless PBFT and RAFT Consensus Networks in 6G Communications
Apr 18, 2023Due to advantages in security and privacy, blockchain is considered a key enabling technology to support 6G communications. Practical Byzantine Fault Tolerance (PBFT) and RAFT are seen as the most applicable consensus mechanisms (CMs) in blockchain-enabled wireless networks. However, previous studies on PBFT and RAFT rarely consider the channel performance of the physical layer, such as path loss and channel fading, resulting in research results that are far from real networks. Additionally, 6G communications will widely deploy high-frequency signals such as terahertz (THz) and millimeter wave (mmWave), while performances of PBFT and RAFT are still unknown when these signals are transmitted in wireless PBFT or RAFT networks. Therefore, it is urgent to study the performance of non-ideal wireless PBFT and RAFT networks with THz and mmWave signals, to better make PBFT and RAFT play a role in the 6G era. In this paper, we study and compare the performance of THz and mmWave signals in non-ideal wireless PBFT and RAFT networks, considering Rayleigh Fading (RF) and close-in Free Space (FS) reference distance path loss. Performance is evaluated by five metrics: consensus success rate, latency, throughput, reliability gain, and energy consumption. Meanwhile, we find and derive that there is a maximum distance between two nodes that can make CMs inevitably successful, and it is named the active distance of CMs. The research results not only analyze the performance of non-ideal wireless PBFT and RAFT networks, but also provide important references for the future transmission of THz and mmWave signals in PBFT and RAFT networks.
Performance Analysis of Non-ideal Wireless PBFT Networks with mmWave and Terahertz Signals
Mar 28, 2023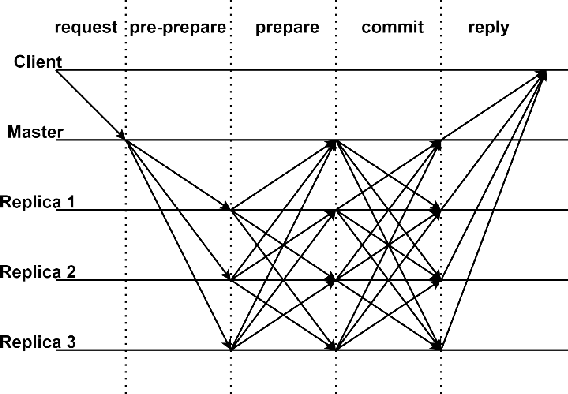
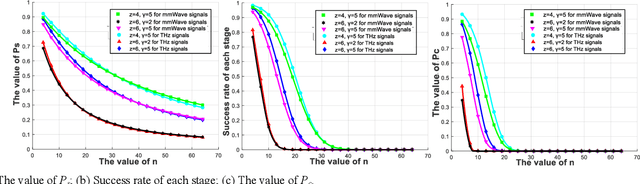
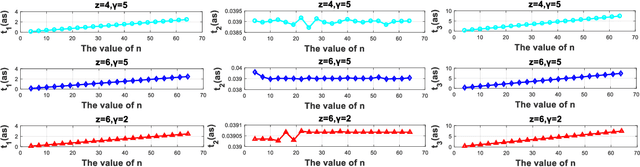
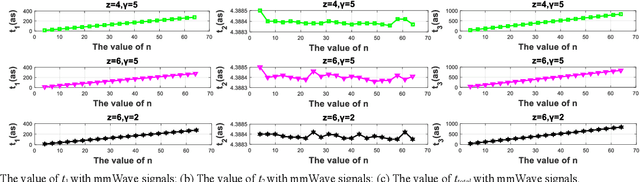
Due to advantages in security and privacy, blockchain is considered a key enabling technology to support 6G communications. Practical Byzantine Fault Tolerance (PBFT) is seen as the most applicable consensus mechanism in blockchain-enabled wireless networks. However, previous studies on PBFT do not consider the channel performance of the physical layer, such as path loss and channel fading, resulting in research results that are far from real networks. Additionally, 6G communications will widely deploy high frequency signals such as millimeter wave (mmWave) and terahertz (THz), while the performance of PBFT is still unknown when these signals are transmitted in wireless PBFT networks. Therefore, it is urgent to study the performance of non-ideal wireless PBFT networks with mmWave and THz siganls, so as to better make PBFT play a role in 6G era. In this paper, we study and compare the performance of mmWave and THz signals in non-ideal wireless PBFT networks, considering Rayleigh Fading (RF) and close-in Free Space (FS) reference distance path loss. Performance is evaluated by consensus success rate and delay. Meanwhile, we find and derive that there is a maximum distance between two nodes that can make PBFT consensus inevitably successful, and it is named active distance of PBFT in this paper. The research results not only analyze the performance of non-ideal wireless PBFT networks, but also provide an important reference for the future transmission of mmWave and THz signals in PBFT networks.
HFedMS: Heterogeneous Federated Learning with Memorable Data Semantics in Industrial Metaverse
Nov 07, 2022



Federated Learning (FL), as a rapidly evolving privacy-preserving collaborative machine learning paradigm, is a promising approach to enable edge intelligence in the emerging Industrial Metaverse. Even though many successful use cases have proved the feasibility of FL in theory, in the industrial practice of Metaverse, the problems of non-independent and identically distributed (non-i.i.d.) data, learning forgetting caused by streaming industrial data, and scarce communication bandwidth remain key barriers to realize practical FL. Facing the above three challenges simultaneously, this paper presents a high-performance and efficient system named HFEDMS for incorporating practical FL into Industrial Metaverse. HFEDMS reduces data heterogeneity through dynamic grouping and training mode conversion (Dynamic Sequential-to-Parallel Training, STP). Then, it compensates for the forgotten knowledge by fusing compressed historical data semantics and calibrates classifier parameters (Semantic Compression and Compensation, SCC). Finally, the network parameters of the feature extractor and classifier are synchronized in different frequencies (Layer-wiseAlternative Synchronization Protocol, LASP) to reduce communication costs. These techniques make FL more adaptable to the heterogeneous streaming data continuously generated by industrial equipment, and are also more efficient in communication than traditional methods (e.g., Federated Averaging). Extensive experiments have been conducted on the streamed non-i.i.d. FEMNIST dataset using 368 simulated devices. Numerical results show that HFEDMS improves the classification accuracy by at least 6.4% compared with 8 benchmarks and saves both the overall runtime and transfer bytes by up to 98%, proving its superiority in precision and efficiency.