 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-Free Representation Guidance for Diffusion Models with a Representation Alignment Projector
Jan 30, 2026Recent progress in generative modeling has enabled high-quality visual synthesis with diffusion-based frameworks, supporting controllable sampling and large-scale training. Inference-time guidance methods such as classifier-free and representative guidance enhance semantic alignment by modifying sampling dynamics; however, they do not fully exploit unsupervised feature representations. Although such visual representations contain rich semantic structure, their integration during generation is constrained by the absence of ground-truth reference images at inference. This work reveals semantic drift in the early denoising stages of diffusion transformers, where stochasticity results in inconsistent alignment even under identical conditioning. To mitigate this issue, we introduce a guidance scheme using a representation alignment projector that injects representations predicted by a projector into intermediate sampling steps, providing an effective semantic anchor without modifying the model architecture. Experiments on SiTs and REPAs show notable improvements in class-conditional ImageNet synthesis, achieving substantially lower FID scores; for example, REPA-XL/2 improves from 5.9 to 3.3, and the proposed method outperforms representative guidance when applied to SiT models. The approach further yields complementary gains when combined with classifier-free guidance, demonstrating enhanced semantic coherence and visual fidelity. These results establish representation-informed diffusion sampling as a practical strategy for reinforcing semantic preservation and image consistency.
Encyclo-K: Evaluating LLMs with Dynamically Composed Knowledge Statements
Dec 31, 2025Benchmarks play a crucial role in tracking the rapid advancement of large language models (LLMs) and identifying their capability boundaries. However, existing benchmarks predominantly curate questions at the question level, suffering from three fundamental limitations: vulnerability to data contamination, restriction to single-knowledge-point assessment, and reliance on costly domain expert annotation. We propose Encyclo-K, a statement-based benchmark that rethinks benchmark construction from the ground up. Our key insight is that knowledge statements, not questions, can serve as the unit of curation, and questions can then be constructed from them. We extract standalone knowledge statements from authoritative textbooks and dynamically compose them into evaluation questions through random sampling at test time. This design directly addresses all three limitations: the combinatorial space is too vast to memorize, and model rankings remain stable across dynamically generated question sets, enabling reliable periodic dataset refresh; each question aggregates 8-10 statements for comprehensive multi-knowledge assessment; annotators only verify formatting compliance without requiring domain expertise, substantially reducing annotation costs. Experiments on over 50 LLMs demonstrate that Encyclo-K poses substantial challenges with strong discriminative power. Even the top-performing OpenAI-GPT-5.1 achieves only 62.07% accuracy, and model performance displays a clear gradient distribution--reasoning models span from 16.04% to 62.07%, while chat models range from 9.71% to 50.40%. These results validate the challenges introduced by dynamic evaluation and multi-statement comprehensive understanding. These findings establish Encyclo-K as a scalable framework for dynamic evaluation of LLMs' comprehensive understanding over multiple fine-grained disciplinary knowledge statements.
Right Time to Learn:Promoting Generalization via Bio-inspired Spacing Effect in Knowledge Distillation
Feb 10, 2025



Knowledge distillation (KD) is a powerful strategy for training deep neural networks (DNNs). Although it was originally proposed to train a more compact ``student'' model from a large ``teacher'' model, many recent efforts have focused on adapting it to promote generalization of the model itself, such as online KD and self KD. % as an effective way Here, we propose an accessible and compatible strategy named Spaced KD to improve the effectiveness of both online KD and self KD, in which the student model distills knowledge from a teacher model trained with a space interval ahead. This strategy is inspired by a prominent theory named \emph{spacing effect} in biological learning and memory, positing that appropriate intervals between learning trials can significantly enhance learning performance. With both theoretical and empirical analyses, we demonstrate that the benefits of the proposed Spaced KD stem from convergence to a flatter loss landscape during stochastic gradient descent (SGD). We perform extensive experiments to validate the effectiveness of Spaced KD in improving the learning performance of DNNs (e.g., the performance gain is up to 2.31\% and 3.34\% on Tiny-ImageNet over online KD and self KD, respectively).
Learning from Pattern Completion: Self-supervised Controllable Generation
Sep 27, 2024
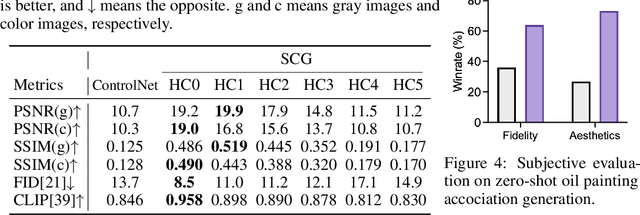
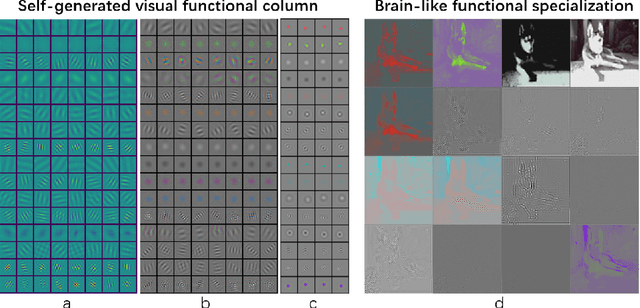

The human brain exhibits a strong ability to spontaneously associate different visual attributes of the same or similar visual scene, such as associating sketches and graffiti with real-world visual objects, usually without supervising information. In contrast, in the field of artificial intelligence, controllable generation methods like ControlNet heavily rely on annotated training datasets such as depth maps, semantic segmentation maps, and poses, which limits the method's scalability. Inspired by the neural mechanisms that may contribute to the brain's associative power, specifically the cortical modularization and hippocampal pattern completion, here we propose a self-supervised controllable generation (SCG) framework. Firstly, we introduce an equivariant constraint to promote inter-module independence and intra-module correlation in a modular autoencoder network, thereby achieving functional specialization. Subsequently, based on these specialized modules, we employ a self-supervised pattern completion approach for controllable generation training. Experimental results demonstrate that the proposed modular autoencoder effectively achieves functional specialization, including the modular processing of color, brightness, and edge detection, and exhibits brain-like features including orientation selectivity, color antagonism, and center-surround receptive fields. Through self-supervised training, associative generation capabilities spontaneously emerge in SCG, demonstrating excellent generalization ability to various tasks such as associative generation on painting, sketches, and ancient graffiti. Compared to the previous representative method ControlNet, our proposed approach not only demonstrates superior robustness in more challenging high-noise scenarios but also possesses more promising scalability potential due to its self-supervised manner.
Optimizing Placement and Power Allocation in Reconfigurable Intelligent Sensing Surfaces for Enhanced Sensing and Communication Performance
Sep 10, 2024



In this letter, we investigate the design of multiple reconfigurable intelligent sensing surfaces (RISSs) that enhance both communication and sensing tasks. An RISS incorporates additional active elements tailored to improve sensing accuracy. Our initial task involves optimizing placement of RISSs to mitigate signal interference. Subsequently, we establish power allocation schemes for sensing and communication within the system. Our final consideration involves examining how sensing results can be utilized to enhance communication, alongside an evaluation of communication performance under the impact of sensing inaccuracies. Numerical results reveal that the sensing task reaches its optimal performance with a finite number of RISSs, while the communication task exhibits enhanced performance with an increasing number of RISSs. Additionally, we identify an optimal communication spot under user movement.
Grand canonical generative diffusion model for crystalline phases and grain boundaries
Aug 28, 2024The diffusion model has emerged as a powerful tool for generating atomic structures for materials science. This work calls attention to the deficiency of current particle-based diffusion models, which represent atoms as a point cloud, in generating even the simplest ordered crystalline structures. The problem is attributed to particles being trapped in local minima during the score-driven simulated annealing of the diffusion process, similar to the physical process of force-driven simulated annealing. We develop a solution, the grand canonical diffusion model, which adopts an alternative voxel-based representation with continuous rather than fixed number of particles. The method is applied towards generation of several common crystalline phases as well as the technologically important and challenging problem of grain boundary structures.
Communication Efficiency Optimization of Federated Learning for Computing and Network Convergence of 6G Networks
Nov 28, 2023Federated learning effectively addresses issues such as data privacy by collaborating across participating devices to train global models. However, factors such as network topology and device computing power can affect its training or communication process in complex network environments. A new network architecture and paradigm with computing-measurable, perceptible, distributable, dispatchable, and manageable capabilities, computing and network convergence (CNC) of 6G networks can effectively support federated learning training and improve its communication efficiency. By guiding the participating devices' training in federated learning based on business requirements, resource load, network conditions, and arithmetic power of devices, CNC can reach this goal. In this paper, to improve the communication efficiency of federated learning in complex networks, we study the communication efficiency optimization of federated learning for computing and network convergence of 6G networks, methods that gives decisions on its training process for different network conditions and arithmetic power of participating devices in federated learning. The experiments address two architectures that exist for devices in federated learning and arrange devices to participate in training based on arithmetic power while achieving optimization of communication efficiency in the process of transferring model parameters. The results show that the method we proposed can (1) cope well with complex network situations (2) effectively balance the delay distribution of participating devices for local training (3) improve the communication efficiency during the transfer of model parameters (4) improve the resource utilization in the network.
Performance Analysis and Comparison of Non-ideal Wireless PBFT and RAFT Consensus Networks in 6G Communications
Apr 18, 2023Due to advantages in security and privacy, blockchain is considered a key enabling technology to support 6G communications. Practical Byzantine Fault Tolerance (PBFT) and RAFT are seen as the most applicable consensus mechanisms (CMs) in blockchain-enabled wireless networks. However, previous studies on PBFT and RAFT rarely consider the channel performance of the physical layer, such as path loss and channel fading, resulting in research results that are far from real networks. Additionally, 6G communications will widely deploy high-frequency signals such as terahertz (THz) and millimeter wave (mmWave), while performances of PBFT and RAFT are still unknown when these signals are transmitted in wireless PBFT or RAFT networks. Therefore, it is urgent to study the performance of non-ideal wireless PBFT and RAFT networks with THz and mmWave signals, to better make PBFT and RAFT play a role in the 6G era. In this paper, we study and compare the performance of THz and mmWave signals in non-ideal wireless PBFT and RAFT networks, considering Rayleigh Fading (RF) and close-in Free Space (FS) reference distance path loss. Performance is evaluated by five metrics: consensus success rate, latency, throughput, reliability gain, and energy consumption. Meanwhile, we find and derive that there is a maximum distance between two nodes that can make CMs inevitably successful, and it is named the active distance of CMs. The research results not only analyze the performance of non-ideal wireless PBFT and RAFT networks, but also provide important references for the future transmission of THz and mmWave signals in PBFT and RAFT networks.
Overview: Computer vision and machine learning for microstructural characterization and analysis
May 28, 2020
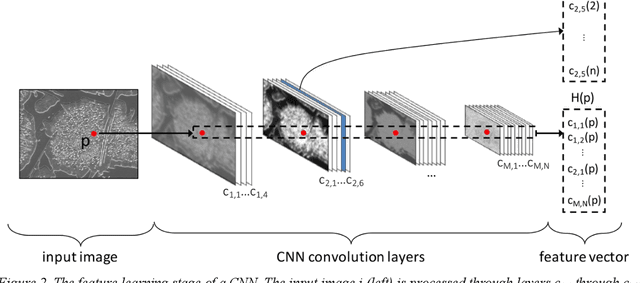


The characterization and analysis of microstructure is the foundation of microstructural science, connecting the materials structure to its composition, process history, and properties. Microstructural quantification traditionally involves a human deciding a priori what to measure and then devising a purpose-built method for doing so. However, recent advances in data science, including computer vision (CV) and machine learning (ML) offer new approaches to extracting information from microstructural images. This overview surveys CV approaches to numerically encode the visual information contained in a microstructural image, which then provides input to supervised or unsupervised ML algorithms that find associations and trends in the high-dimensional image representation. CV/ML systems for microstructural characterization and analysis span the taxonomy of image analysis tasks, including image classification, semantic segmentation, object detection, and instance segmentation. These tools enable new approaches to microstructural analysis, including the development of new, rich visual metrics and the discovery of processing-microstructure-property relationships.
Triple Memory Networks: a Brain-Inspired Method for Continual Learning
Mar 06, 2020
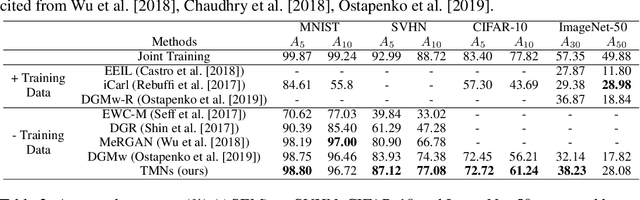


Continual acquisition of novel experience without interfering previously learned knowledge, i.e. continual learning, is critical for artificial neural networks, but limited by catastrophic forgetting. A neural network adjusts its parameters when learning a new task, but then fails to conduct the old tasks well. By contrast, the brain has a powerful ability to continually learn new experience without catastrophic interference. The underlying neural mechanisms possibly attribute to the interplay of hippocampus-dependent memory system and neocortex-dependent memory system, mediated by prefrontal cortex. Specifically, the two memory systems develop specialized mechanisms to consolidate information as more specific forms and more generalized forms, respectively, and complement the two forms of information in the interplay. Inspired by such brain strategy, we propose a novel approach named triple memory networks (TMNs) for continual learning. TMNs model the interplay of hippocampus, prefrontal cortex and sensory cortex (a neocortex region) as a triple-network architecture of generative adversarial networks (GAN). The input information is encoded as specific representation of the data distributions in a generator, or generalized knowledge of solving tasks in a discriminator and a classifier, with implementing appropriate brain-inspired algorithms to alleviate catastrophic forgetting in each module. Particularly, the generator replays generated data of the learned tasks to the discriminator and the classifier, both of which are implemented with a weight consolidation regularizer to complement the lost information in generation process. TMNs achieve new state-of-the-art performance on a variety of class-incremental learning benchmarks on MNIST, SVHN, CIFAR-10 and ImageNet-50, comparing with strong baseline methods.