 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePC Layer: Polynomial Weight Preconditioning for Improving LLM Pre-Training
Jun 04, 2026We propose a preconditioning (PC) layer, a weight parameterization via polynomial preconditioner that ensures stable weight conditioning throughout LLM training. The PC module reshapes the singular-value spectrum of weight matrices via low-degree polynomial preconditioning. After training, the preconditioned weights can be merged back into the original architecture, incurring no inference overhead. We demonstrate the advantage of the proposed PC layer over standard transformers in Llama-1B pre-training, for both the AdamW and Muon optimizers. Theoretically, we justify this spectrum-control principle by proving that uniformly bounding each layer's singular values ensures geometric convergence of gradient descent to global minima, for certain deep linear networks. Our code is available at https://github.com/Empath-aln/PC-layer.
Adam Converges Without Any Modification On Update Rules
Mar 02, 2026Adam is the default algorithm for training neural networks, including large language models (LLMs). However, \citet{reddi2019convergence} provided an example that Adam diverges, raising concerns for its deployment in AI model training. We identify a key mismatch between the divergence example and practice: \citet{reddi2019convergence} pick the problem after picking the hyperparameters of Adam, i.e., $(β_1,β_2)$; while practical applications often fix the problem first and then tune $(β_1,β_2)$. In this work, we prove that Adam converges with proper problem-dependent hyperparameters. First, we prove that Adam converges when $β_2$ is large and $β_1 < \sqrt{β_2}$. Second, when $β_2$ is small, we point out a region of $(β_1,β_2)$ combinations where Adam can diverge to infinity. Our results indicate a phase transition for Adam from divergence to convergence when changing the $(β_1, β_2)$ combination. To our knowledge, this is the first phase transition in $(β_1,β_2)$ 2D-plane reported in the literature, providing rigorous theoretical guarantees for Adam optimizer. We further point out that the critical boundary $(β_1^*, β_2^*)$ is problem-dependent, and particularly, dependent on batch size. This provides suggestions on how to tune $β_1$ and $β_2$: when Adam does not work well, we suggest tuning up $β_2$ inversely with batch size to surpass the threshold $β_2^*$, and then trying $β_1< \sqrt{β_2}$. Our suggestions are supported by reports from several empirical studies, which observe improved LLM training performance when applying them.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
ErrEval: Error-Aware Evaluation for Question Generation through Explicit Diagnostics
Jan 15, 2026Automatic Question Generation (QG) often produces outputs with critical defects, such as factual hallucinations and answer mismatches. However, existing evaluation methods, including LLM-based evaluators, mainly adopt a black-box and holistic paradigm without explicit error modeling, leading to the neglect of such defects and overestimation of question quality. To address this issue, we propose ErrEval, a flexible and Error-aware Evaluation framework that enhances QG evaluation through explicit error diagnostics. Specifically, ErrEval reformulates evaluation as a two-stage process of error diagnosis followed by informed scoring. At the first stage, a lightweight plug-and-play Error Identifier detects and categorizes common errors across structural, linguistic, and content-related aspects. These diagnostic signals are then incorporated as explicit evidence to guide LLM evaluators toward more fine-grained and grounded judgments. Extensive experiments on three benchmarks demonstrate the effectiveness of ErrEval, showing that incorporating explicit diagnostics improves alignment with human judgments. Further analyses confirm that ErrEval effectively mitigates the overestimation of low-quality questions.
GeoLaux: A Benchmark for Evaluating MLLMs' Geometry Performance on Long-Step Problems Requiring Auxiliary Lines
Aug 08, 2025Geometry problem solving (GPS) requires models to master diagram comprehension, logical reasoning, knowledge application, numerical computation, and auxiliary line construction. This presents a significant challenge for Multimodal Large Language Models (MLLMs). However, existing benchmarks for evaluating MLLM geometry skills overlook auxiliary line construction and lack fine-grained process evaluation, making them insufficient for assessing MLLMs' long-step reasoning abilities. To bridge these gaps, we present the GeoLaux benchmark, comprising 2,186 geometry problems, incorporating both calculation and proving questions. Notably, the problems require an average of 6.51 reasoning steps, with a maximum of 24 steps, and 41.8% of them need auxiliary line construction. Building on the dataset, we design a novel five-dimensional evaluation strategy assessing answer correctness, process correctness, process quality, auxiliary line impact, and error causes. Extensive experiments on 13 leading MLLMs (including thinking models and non-thinking models) yield three pivotal findings: First, models exhibit substantial performance degradation in extended reasoning steps (nine models demonstrate over 50% performance drop). Second, compared to calculation problems, MLLMs tend to take shortcuts when solving proving problems. Third, models lack auxiliary line awareness, and enhancing this capability proves particularly beneficial for overall geometry reasoning improvement. These findings establish GeoLaux as both a benchmark for evaluating MLLMs' long-step geometric reasoning with auxiliary lines and a guide for capability advancement. Our dataset and code are included in supplementary materials and will be released.
$XX^{t}$ Can Be Faster
May 14, 2025



We present a new algorithm RXTX that computes product of matrix by its transpose $XX^{t}$. RXTX uses $5\%$ less multiplications and additions than State-of-the-Art and achieves accelerations even for small sizes of matrix $X$. The algorithm was discovered by combining Machine Learning-based search methods with Combinatorial Optimization.
Towards Quantifying the Hessian Structure of Neural Networks
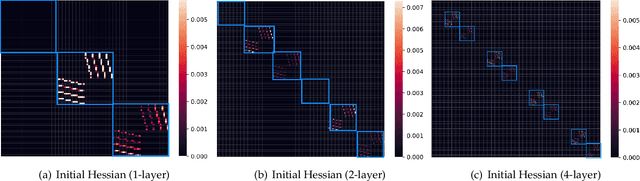
May 05, 2025Empirical studies reported that the Hessian matrix of neural networks (NNs) exhibits a near-block-diagonal structure, yet its theoretical foundation remains unclear. In this work, we reveal two forces that shape the Hessian structure: a ``static force'' rooted in the architecture design, and a ``dynamic force'' arisen from training. We then provide a rigorous theoretical analysis of ``static force'' at random initialization. We study linear models and 1-hidden-layer networks with the mean-square (MSE) loss and the Cross-Entropy (CE) loss for classification tasks. By leveraging random matrix theory, we compare the limit distributions of the diagonal and off-diagonal Hessian blocks and find that the block-diagonal structure arises as $C \rightarrow \infty$, where $C$ denotes the number of classes. Our findings reveal that $C$ is a primary driver of the near-block-diagonal structure. These results may shed new light on the Hessian structure of large language models (LLMs), which typically operate with a large $C$ exceeding $10^4$ or $10^5$.
MoFO: Momentum-Filtered Optimizer for Mitigating Forgetting in LLM Fine-Tuning
Jul 31, 2024Recently, large language models (LLMs) have demonstrated remarkable capabilities in a wide range of tasks. Typically, an LLM is pre-trained on large corpora and subsequently fine-tuned on task-specific datasets. However, during fine-tuning, LLMs may forget the knowledge acquired in the pre-training stage, leading to a decline in general capabilities. To address this issue, we propose a new fine-tuning algorithm termed Momentum-Filtered Optimizer (MoFO). The key idea of MoFO is to iteratively select and update the model parameters with the largest momentum magnitudes. Compared to full-parameter training, MoFO achieves similar fine-tuning performance while keeping parameters closer to the pre-trained model, thereby mitigating knowledge forgetting. Unlike most existing methods for forgetting mitigation, MoFO combines the following two advantages. First, MoFO does not require access to pre-training data. This makes MoFO particularly suitable for fine-tuning scenarios where pre-training data is unavailable, such as fine-tuning checkpoint-only open-source LLMs. Second, MoFO does not alter the original loss function. This could avoid impairing the model performance on the fine-tuning tasks. We validate MoFO through rigorous convergence analysis and extensive experiments, demonstrating its superiority over existing methods in mitigating forgetting and enhancing fine-tuning performance.
Adam-mini: Use Fewer Learning Rates To Gain More
Jun 26, 2024We propose Adam-mini, an optimizer that achieves on-par or better performance than AdamW with 45% to 50% less memory footprint. Adam-mini reduces memory by cutting down the learning rate resources in Adam (i.e., $1/\sqrt{v}$). We find that $\geq$ 90% of these learning rates in $v$ could be harmlessly removed if we (1) carefully partition the parameters into blocks following our proposed principle on Hessian structure; (2) assign a single but good learning rate to each parameter block. We further find that, for each of these parameter blocks, there exists a single high-quality learning rate that can outperform Adam, provided that sufficient resources are available to search it out. We then provide one cost-effective way to find good learning rates and propose Adam-mini. Empirically, we verify that Adam-mini performs on par or better than AdamW on various language models sized from 125M to 7B for pre-training, supervised fine-tuning, and RLHF. The reduced memory footprint of Adam-mini also alleviates communication overheads among GPUs and CPUs, thereby increasing throughput. For instance, Adam-mini achieves 49.6% higher throughput than AdamW when pre-training Llama2-7B on $2\times$ A800-80GB GPUs, which saves 33% wall-clock time for pre-training.
Why Transformers Need Adam: A Hessian Perspective
Feb 26, 2024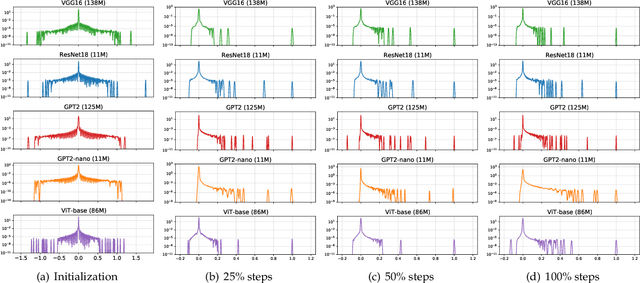

SGD performs worse than Adam by a significant margin on Transformers, but the reason remains unclear. In this work, we provide an explanation of SGD's failure on Transformers through the lens of Hessian: (i) Transformers are ``heterogeneous'': the Hessian spectrum across parameter blocks vary dramatically, a phenomenon we call ``block heterogeneity"; (ii) Heterogeneity hampers SGD: SGD performs badly on problems with block heterogeneity. To validate that heterogeneity hampers SGD, we check various Transformers, CNNs, MLPs, and quadratic problems, and find that SGD works well on problems without block heterogeneity but performs badly when the heterogeneity exists. Our initial theoretical analysis indicates that SGD fails because it applies one single learning rate for all blocks, which cannot handle the heterogeneity among blocks. The failure could be rescued if we could assign different learning rates across blocks, as designed in Adam.