 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTASU2: Controllable CTC Simulation for Alignment and Low-Resource Adaptation of Speech LLMs
Apr 09, 2026Speech LLM post-training increasingly relies on efficient cross-modal alignment and robust low-resource adaptation, yet collecting large-scale audio-text pairs remains costly. Text-only alignment methods such as TASU reduce this burden by simulating CTC posteriors from transcripts, but they provide limited control over uncertainty and error rate, making curriculum design largely heuristic. We propose \textbf{TASU2}, a controllable CTC simulation framework that simulates CTC posterior distributions under a specified WER range, producing text-derived supervision that better matches the acoustic decoding interface. This enables principled post-training curricula that smoothly vary supervision difficulty without TTS. Across multiple source-to-target adaptation settings, TASU2 improves in-domain and out-of-domain recognition over TASU, and consistently outperforms strong baselines including text-only fine-tuning and TTS-based augmentation, while mitigating source-domain performance degradation.
Beyond Descriptions: A Generative Scene2Audio Framework for Blind and Low-Vision Users to Experience Vista Landscapes
Mar 28, 2026Current scene perception tools for Blind and Low Vision (BLV) individuals rely on spoken descriptions but lack engaging representations of visually pleasing distant environmental landscapes (Vista spaces). Our proposed Scene2Audio framework generates comprehensible and enjoyable nonverbal audio using generative models informed by psychoacoustics, and principles of scene audio composition. Through a user study with 11 BLV participants, we found that combining the Scene2Audio sounds with speech creates a better experience than speech alone, as the sound effects complement the speech making the scene easier to imagine. A mobile app "in-the-wild" study with 7 BLV users for more than a week further showed the potential of Scene2Audio in enhancing outdoor scene experiences. Our work bridges the gap between visual and auditory scene perception by moving beyond purely descriptive aids, addressing the aesthetic needs of BLV users.
G-STAR: End-to-End Global Speaker-Tracking Attributed Recognition
Mar 11, 2026We study timestamped speaker-attributed ASR for long-form, multi-party speech with overlap, where chunk-wise inference must preserve meeting-level speaker identity consistency while producing time-stamped, speaker-labeled transcripts. Previous Speech-LLM systems tend to prioritize either local diarization or global labeling, but often lack the ability to capture fine-grained temporal boundaries or robust cross-chunk identity linking. We propose G-STAR, an end-to-end system that couples a time-aware speaker-tracking module with a Speech-LLM transcription backbone. The tracker provides structured speaker cues with temporal grounding, and the LLM generates attributed text conditioned on these cues. G-STAR supports both component-wise optimization and joint end-to-end training, enabling flexible learning under heterogeneous supervision and domain shift. Experiments analyze cue fusion, local versus long-context trade-offs and hierarchical objectives.
A Typologically Grounded Evaluation Framework for Word Order and Morphology Sensitivity in Multilingual Masked LMs
Feb 28, 2026We introduce a typology-aware diagnostic for multilingual masked language models that tests reliance on word order versus inflectional form. Using Universal Dependencies, we apply inference-time perturbations: full token scrambling, content-word scrambling with function words fixed, dependency-based head--dependent swaps, and sentence-level lemma substitution (+L), which lemmatizes both the context and the masked target label. We evaluate mBERT and XLM-R on English, Chinese, German, Spanish, and Russian. Full scrambling drives word-level reconstruction accuracy near zero in all languages; partial and head--dependent perturbations cause smaller but still large drops. +L has little effect in Chinese but substantially lowers accuracy in German/Spanish/Russian, and it does not mitigate the impact of scrambling. Top-5 word accuracy shows the same pattern: under full scrambling, the gold word rarely appears among the five highest-ranked reconstructions. We release code, sampling scripts, and balanced evaluation subsets; Turkish results under strict reconstruction are reported in the appendix.
When Semantic Overlap Is Not Enough: Cross-Lingual Euphemism Transfer Between Turkish and English
Feb 18, 2026Euphemisms substitute socially sensitive expressions, often softening or reframing meaning, and their reliance on cultural and pragmatic context complicates modeling across languages. In this study, we investigate how cross-lingual equivalence influences transfer in multilingual euphemism detection. We categorize Potentially Euphemistic Terms (PETs) in Turkish and English into Overlapping (OPETs) and Non-Overlapping (NOPETs) subsets based on their functional, pragmatic, and semantic alignment. Our findings reveal a transfer asymmetry: semantic overlap is insufficient to guarantee positive transfer, particularly in low-resource Turkish-to-English direction, where performance can degrade even for overlapping euphemisms, and in some cases, improve under NOPET-based training. Differences in label distribution help explain these counterintuitive results. Category-level analysis suggests that transfer may be influenced by domain-specific alignment, though evidence is limited by sparsity.
TC-BiMamba: Trans-Chunk bidirectionally within BiMamba for unified streaming and non-streaming ASR
Feb 12, 2026This work investigates bidirectional Mamba (BiMamba) for unified streaming and non-streaming automatic speech recognition (ASR). Dynamic chunk size training enables a single model for offline decoding and streaming decoding with various latency settings. In contrast, existing BiMamba based streaming method is limited to fixed chunk size decoding. When dynamic chunk size training is applied, training overhead increases substantially. To tackle this issue, we propose the Trans-Chunk BiMamba (TC-BiMamba) for dynamic chunk size training. Trans-Chunk mechanism trains both bidirectional sequences in an offline style with dynamic chunk size. On the one hand, compared to traditional chunk-wise processing, TC-BiMamba simultaneously achieves 1.3 times training speedup, reduces training memory by 50%, and improves model performance since it can capture bidirectional context. On the other hand, experimental results show that TC-BiMamba outperforms U2++ and matches LC-BiMmaba with smaller model size.
UniSRCodec: Unified and Low-Bitrate Single Codebook Codec with Sub-Band Reconstruction
Jan 06, 2026Neural Audio Codecs (NACs) can reduce transmission overhead by performing compact compression and reconstruction, which also aim to bridge the gap between continuous and discrete signals. Existing NACs can be divided into two categories: multi-codebook and single-codebook codecs. Multi-codebook codecs face challenges such as structural complexity and difficulty in adapting to downstream tasks, while single-codebook codecs, though structurally simpler, suffer from low-fidelity, ineffective modeling of unified audio, and an inability to support modeling of high-frequency audio. We propose the UniSRCodec, a single-codebook codec capable of supporting high sampling rate, low-bandwidth, high fidelity, and unified. We analyze the inefficiency of waveform-based compression and introduce the time and frequency compression method using the Mel-spectrogram, and cooperate with a Vocoder to recover the phase information of the original audio. Moreover, we propose a sub-band reconstruction technique to achieve high-quality compression across both low and high frequency bands. Subjective and objective experimental results demonstrate that UniSRCodec achieves state-of-the-art (SOTA) performance among cross-domain single-codebook codecs with only a token rate of 40, and its reconstruction quality is comparable to that of certain multi-codebook methods. Our demo page is available at https://wxzyd123.github.io/unisrcodec.
MOSA: Mixtures of Simple Adapters Outperform Monolithic Approaches in LLM-based Multilingual ASR
Aug 26, 2025



End-to-end multilingual ASR aims to transcribe speech from different languages into corresponding text, but is often limited by scarce multilingual data. LLM-based ASR aligns speech encoder outputs with LLM input space via a projector and has achieved notable success. However, prior work mainly improves performance by increasing data, with little focus on cross-lingual knowledge sharing. Moreover, a single complex projector struggles to capture both shared and language-specific features effectively. In this work, we propose MOSA (Mixture of Simple Adapters), leveraging a Mixture-of-Experts mechanism to combine lightweight adapters that learn shared and language-specific knowledge. This enables better utilization of high-resource language data to support low-resource languages, mitigating data scarcity issues. Experimental results show that MOSA-Base achieves a 15.4\% relative reduction in average WER compared to the Baseline-Base and consistently outperforms it across all languages. Remarkably, MOSA-Base surpasses the Baseline-Base even when trained with only 60\% of its parameters. Similarly, MOSA-Large outperforms the Baseline-Large in average WER and demonstrates greater robustness to data imbalance. Ablation studies further indicate that MOSA is more effective at handling individual languages and learning both language-specific and shared linguistic knowledge. These findings support that, in LLM-based ASR, a mixture of simple adapters is more effective than a single, complex adapter design.
Joint decoding method for controllable contextual speech recognition based on Speech LLM
Aug 12, 2025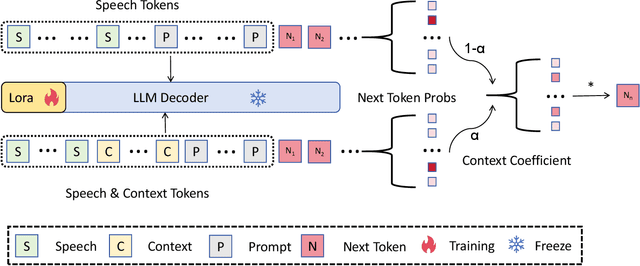
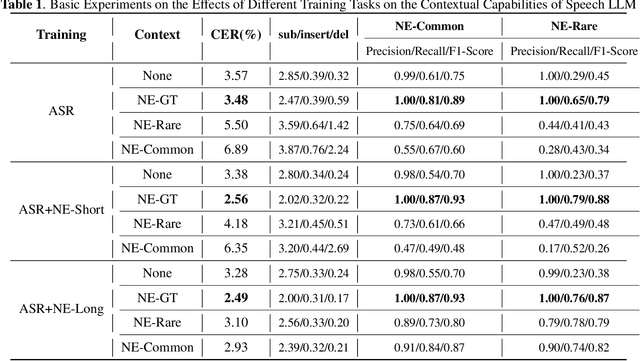
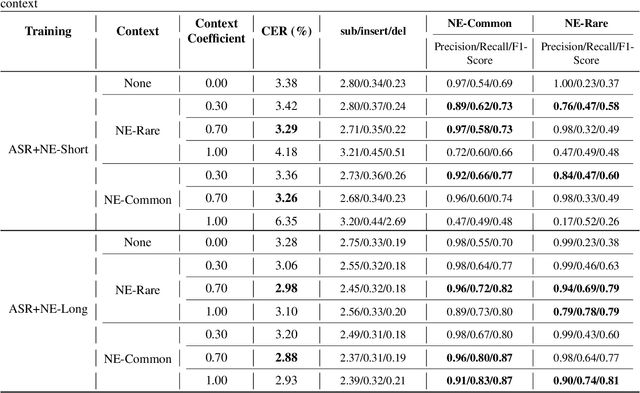
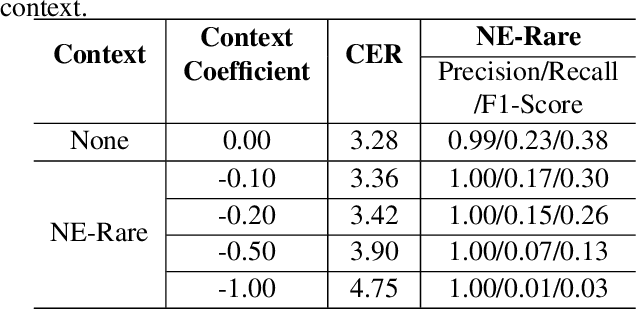
Contextual speech recognition refers to the ability to identify preferences for specific content based on contextual information. Recently, leveraging the contextual understanding capabilities of Speech LLM to achieve contextual biasing by injecting contextual information through prompts have emerged as a research hotspot.However, the direct information injection method via prompts relies on the internal attention mechanism of the model, making it impossible to explicitly control the extent of information injection. To address this limitation, we propose a joint decoding method to control the contextual information. This approach enables explicit control over the injected contextual information and achieving superior recognition performance. Additionally, Our method can also be used for sensitive word suppression recognition.Furthermore, experimental results show that even Speech LLM not pre-trained on long contextual data can acquire long contextual capabilities through our method.
Low-Resource Domain Adaptation for Speech LLMs via Text-Only Fine-Tuning
Jun 06, 2025



Recent advances in automatic speech recognition (ASR) have combined speech encoders with large language models (LLMs) through projection, forming Speech LLMs with strong performance. However, adapting them to new domains remains challenging, especially in low-resource settings where paired speech-text data is scarce. We propose a text-only fine-tuning strategy for Speech LLMs using unpaired target-domain text without requiring additional audio. To preserve speech-text alignment, we introduce a real-time evaluation mechanism during fine-tuning. This enables effective domain adaptation while maintaining source-domain performance. Experiments on LibriSpeech, SlideSpeech, and Medical datasets show that our method achieves competitive recognition performance, with minimal degradation compared to full audio-text fine-tuning. It also improves generalization to new domains without catastrophic forgetting, highlighting the potential of text-only fine-tuning for low-resource domain adaptation of ASR.