 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHookMIL: Revisiting Context Modeling in Multiple Instance Learning for Computational Pathology
Dec 20, 2025Multiple Instance Learning (MIL) has enabled weakly supervised analysis of whole-slide images (WSIs) in computational pathology. However, traditional MIL approaches often lose crucial contextual information, while transformer-based variants, though more expressive, suffer from quadratic complexity and redundant computations. To address these limitations, we propose HookMIL, a context-aware and computationally efficient MIL framework that leverages compact, learnable hook tokens for structured contextual aggregation. These tokens can be initialized from (i) key-patch visual features, (ii) text embeddings from vision-language pathology models, and (iii) spatially grounded features from spatial transcriptomics-vision models. This multimodal initialization enables Hook Tokens to incorporate rich textual and spatial priors, accelerating convergence and enhancing representation quality. During training, Hook tokens interact with instances through bidirectional attention with linear complexity. To further promote specialization, we introduce a Hook Diversity Loss that encourages each token to focus on distinct histopathological patterns. Additionally, a hook-to-hook communication mechanism refines contextual interactions while minimizing redundancy. Extensive experiments on four public pathology datasets demonstrate that HookMIL achieves state-of-the-art performance, with improved computational efficiency and interpretability. Codes are available at https://github.com/lingxitong/HookMIL.
Deep Pathomic Learning Defines Prognostic Subtypes and Molecular Drivers in Colorectal Cancer
Nov 19, 2025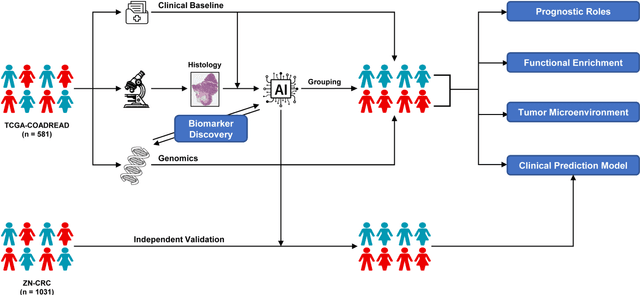
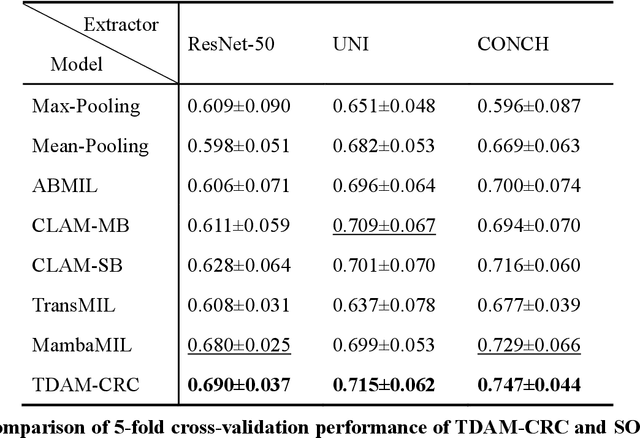
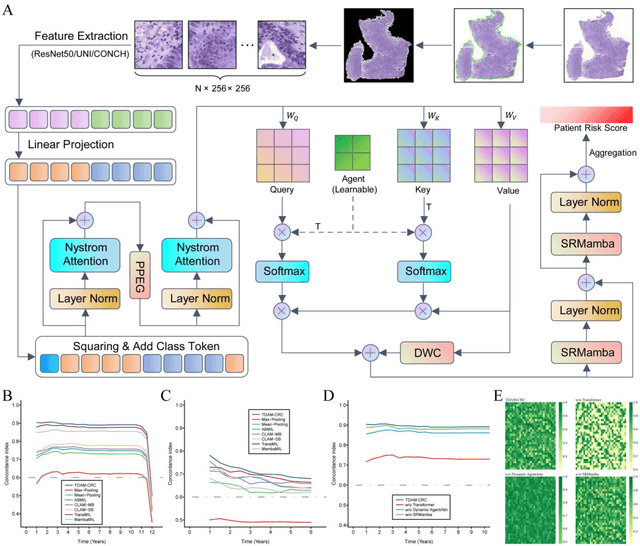
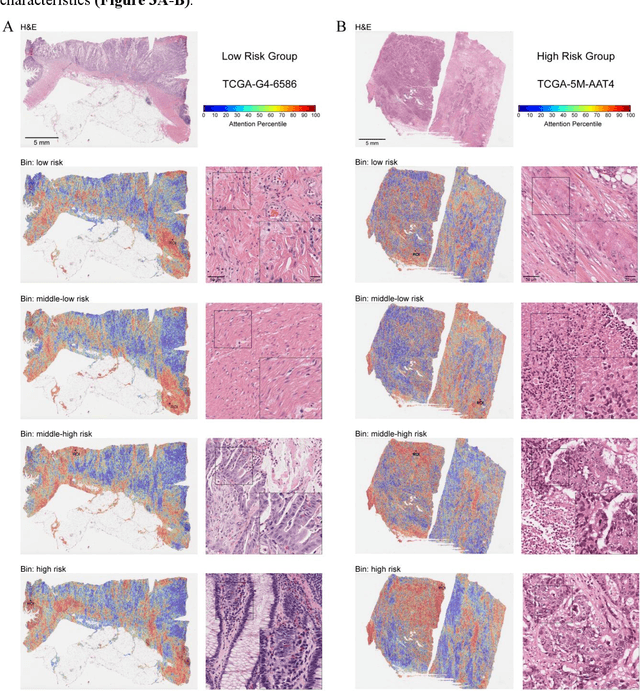
Precise prognostic stratification of colorectal cancer (CRC) remains a major clinical challenge due to its high heterogeneity. The conventional TNM staging system is inadequate for personalized medicine. We aimed to develop and validate a novel multiple instance learning model TDAM-CRC using histopathological whole-slide images for accurate prognostic prediction and to uncover its underlying molecular mechanisms. We trained the model on the TCGA discovery cohort (n=581), validated it in an independent external cohort (n=1031), and further we integrated multi-omics data to improve model interpretability and identify novel prognostic biomarkers. The results demonstrated that the TDAM-CRC achieved robust risk stratification in both cohorts. Its predictive performance significantly outperformed the conventional clinical staging system and multiple state-of-the-art models. The TDAM-CRC risk score was confirmed as an independent prognostic factor in multivariable analysis. Multi-omics analysis revealed that the high-risk subtype is closely associated with metabolic reprogramming and an immunosuppressive tumor microenvironment. Through interaction network analysis, we identified and validated Mitochondrial Ribosomal Protein L37 (MRPL37) as a key hub gene linking deep pathomic features to clinical prognosis. We found that high expression of MRPL37, driven by promoter hypomethylation, serves as an independent biomarker of favorable prognosis. Finally, we constructed a nomogram incorporating the TDAM-CRC risk score and clinical factors to provide a precise and interpretable clinical decision-making tool for CRC patients. Our AI-driven pathological model TDAM-CRC provides a robust tool for improved CRC risk stratification, reveals new molecular targets, and facilitates personalized clinical decision-making.
MergeSAM: Unsupervised change detection of remote sensing images based on the Segment Anything Model
Jul 30, 2025Recently, large foundation models trained on vast datasets have demonstrated exceptional capabilities in feature extraction and general feature representation. The ongoing advancements in deep learning-driven large models have shown great promise in accelerating unsupervised change detection methods, thereby enhancing the practical applicability of change detection technologies. Building on this progress, this paper introduces MergeSAM, an innovative unsupervised change detection method for high-resolution remote sensing imagery, based on the Segment Anything Model (SAM). Two novel strategies, MaskMatching and MaskSplitting, are designed to address real-world complexities such as object splitting, merging, and other intricate changes. The proposed method fully leverages SAM's object segmentation capabilities to construct multitemporal masks that capture complex changes, embedding the spatial structure of land cover into the change detection process.
Subspecialty-Specific Foundation Model for Intelligent Gastrointestinal Pathology
May 28, 2025Gastrointestinal (GI) diseases represent a clinically significant burden, necessitating precise diagnostic approaches to optimize patient outcomes. Conventional histopathological diagnosis, heavily reliant on the subjective interpretation of pathologists, suffers from limited reproducibility and diagnostic variability. To overcome these limitations and address the lack of pathology-specific foundation models for GI diseases, we develop Digepath, a specialized foundation model for GI pathology. Our framework introduces a dual-phase iterative optimization strategy combining pretraining with fine-screening, specifically designed to address the detection of sparsely distributed lesion areas in whole-slide images. Digepath is pretrained on more than 353 million image patches from over 200,000 hematoxylin and eosin-stained slides of GI diseases. It attains state-of-the-art performance on 33 out of 34 tasks related to GI pathology, including pathological diagnosis, molecular prediction, gene mutation prediction, and prognosis evaluation, particularly in diagnostically ambiguous cases and resolution-agnostic tissue classification.We further translate the intelligent screening module for early GI cancer and achieve near-perfect 99.6% sensitivity across 9 independent medical institutions nationwide. The outstanding performance of Digepath highlights its potential to bridge critical gaps in histopathological practice. This work not only advances AI-driven precision pathology for GI diseases but also establishes a transferable paradigm for other pathology subspecialties.
Multimodal Distillation-Driven Ensemble Learning for Long-Tailed Histopathology Whole Slide Images Analysis
Mar 02, 2025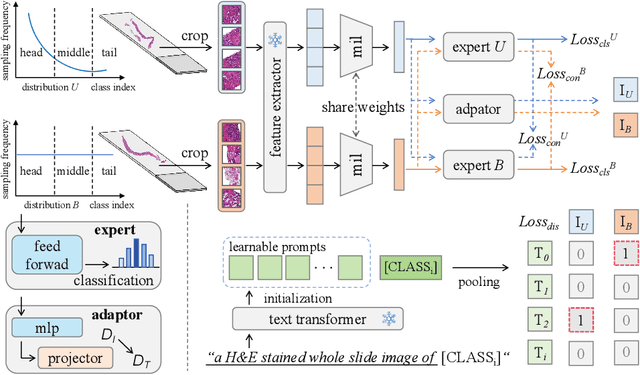


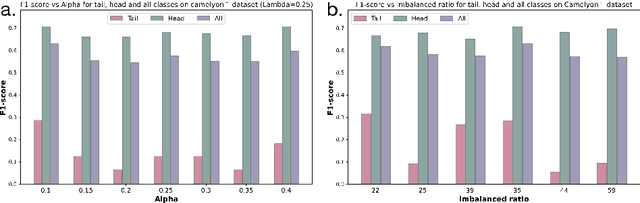
Multiple Instance Learning (MIL) plays a significant role in computational pathology, enabling weakly supervised analysis of Whole Slide Image (WSI) datasets. The field of WSI analysis is confronted with a severe long-tailed distribution problem, which significantly impacts the performance of classifiers. Long-tailed distributions lead to class imbalance, where some classes have sparse samples while others are abundant, making it difficult for classifiers to accurately identify minority class samples. To address this issue, we propose an ensemble learning method based on MIL, which employs expert decoders with shared aggregators and consistency constraints to learn diverse distributions and reduce the impact of class imbalance on classifier performance. Moreover, we introduce a multimodal distillation framework that leverages text encoders pre-trained on pathology-text pairs to distill knowledge and guide the MIL aggregator in capturing stronger semantic features relevant to class information. To ensure flexibility, we use learnable prompts to guide the distillation process of the pre-trained text encoder, avoiding limitations imposed by specific prompts. Our method, MDE-MIL, integrates multiple expert branches focusing on specific data distributions to address long-tailed issues. Consistency control ensures generalization across classes. Multimodal distillation enhances feature extraction. Experiments on Camelyon+-LT and PANDA-LT datasets show it outperforms state-of-the-art methods.
Controlling the Latent Diffusion Model for Generative Image Shadow Removal via Residual Generation
Dec 03, 2024Large-scale generative models have achieved remarkable advancements in various visual tasks, yet their application to shadow removal in images remains challenging. These models often generate diverse, realistic details without adequate focus on fidelity, failing to meet the crucial requirements of shadow removal, which necessitates precise preservation of image content. In contrast to prior approaches that aimed to regenerate shadow-free images from scratch, this paper utilizes diffusion models to generate and refine image residuals. This strategy fully uses the inherent detailed information within shadowed images, resulting in a more efficient and faithful reconstruction of shadow-free content. Additionally, to revent the accumulation of errors during the generation process, a crosstimestep self-enhancement training strategy is proposed. This strategy leverages the network itself to augment the training data, not only increasing the volume of data but also enabling the network to dynamically correct its generation trajectory, ensuring a more accurate and robust output. In addition, to address the loss of original details in the process of image encoding and decoding of large generative models, a content-preserved encoder-decoder structure is designed with a control mechanism and multi-scale skip connections to achieve high-fidelity shadow-free image reconstruction. Experimental results demonstrate that the proposed method can reproduce high-quality results based on a large latent diffusion prior and faithfully preserve the original contents in shadow regions.
Agent Aggregator with Mask Denoise Mechanism for Histopathology Whole Slide Image Analysis
Sep 18, 2024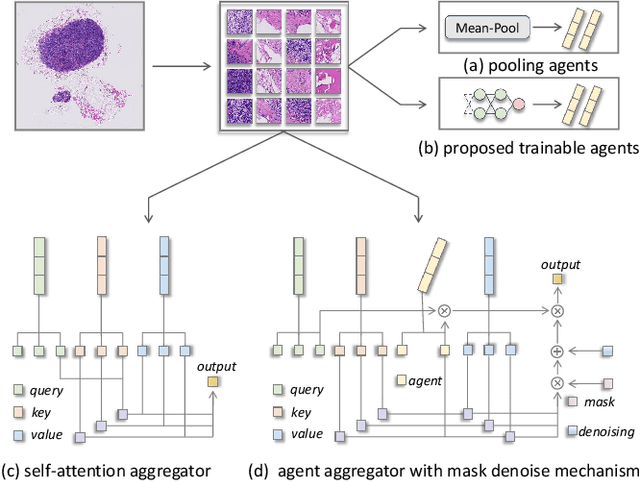
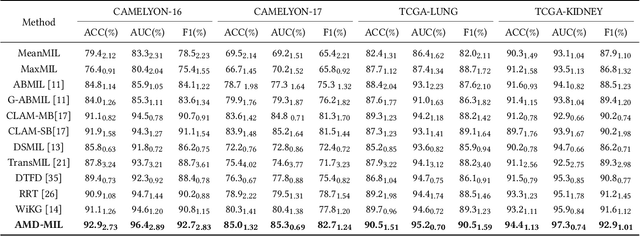
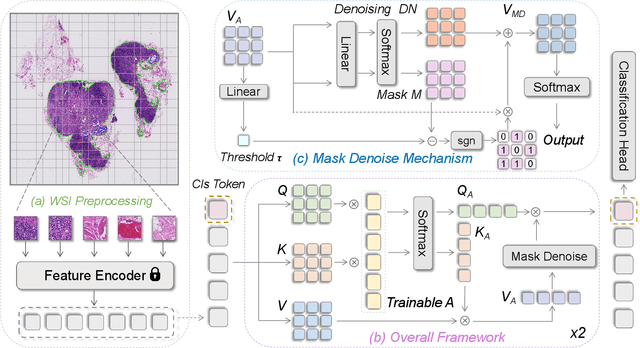
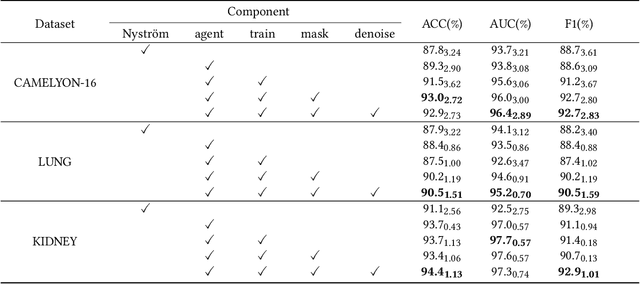
Histopathology analysis is the gold standard for medical diagnosis. Accurate classification of whole slide images (WSIs) and region-of-interests (ROIs) localization can assist pathologists in diagnosis. The gigapixel resolution of WSI and the absence of fine-grained annotations make direct classification and analysis challenging. In weakly supervised learning, multiple instance learning (MIL) presents a promising approach for WSI classification. The prevailing strategy is to use attention mechanisms to measure instance importance for classification. However, attention mechanisms fail to capture inter-instance information, and self-attention causes quadratic computational complexity. To address these challenges, we propose AMD-MIL, an agent aggregator with a mask denoise mechanism. The agent token acts as an intermediate variable between the query and key for computing instance importance. Mask and denoising matrices, mapped from agents-aggregated value, dynamically mask low-contribution representations and eliminate noise. AMD-MIL achieves better attention allocation by adjusting feature representations, capturing micro-metastases in cancer, and improving interpretability. Extensive experiments on CAMELYON-16, CAMELYON-17, TCGA-KIDNEY, and TCGA-LUNG show AMD-MIL's superiority over state-of-the-art methods.
Multi-frame Joint Enhancement for Early Interlaced Videos
Sep 29, 2021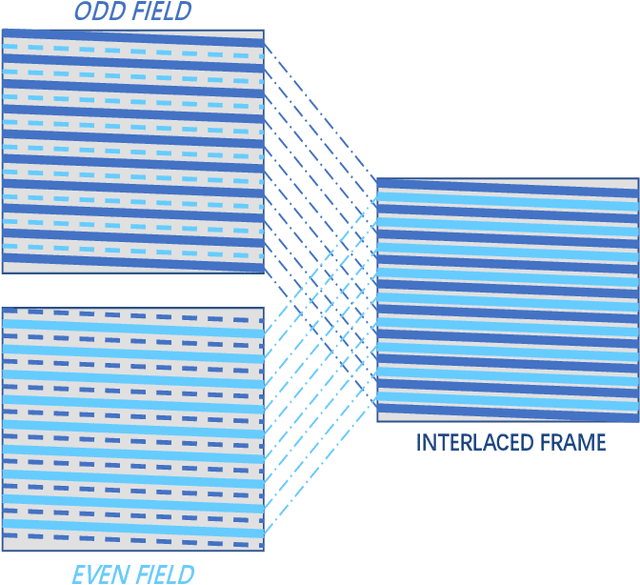



Early interlaced videos usually contain multiple and interlacing and complex compression artifacts, which significantly reduce the visual quality. Although the high-definition reconstruction technology for early videos has made great progress in recent years, related research on deinterlacing is still lacking. Traditional methods mainly focus on simple interlacing mechanism, and cannot deal with the complex artifacts in real-world early videos. Recent interlaced video reconstruction deep deinterlacing models only focus on single frame, while neglecting important temporal information. Therefore, this paper proposes a multiframe deinterlacing network joint enhancement network for early interlaced videos that consists of three modules, i.e., spatial vertical interpolation module, temporal alignment and fusion module, and final refinement module. The proposed method can effectively remove the complex artifacts in early videos by using temporal redundancy of multi-fields. Experimental results demonstrate that the proposed method can recover high quality results for both synthetic dataset and real-world early interlaced videos.
Improving Global Forest Mapping by Semi-automatic Sample Labeling with Deep Learning on Google Earth Images
Aug 06, 2021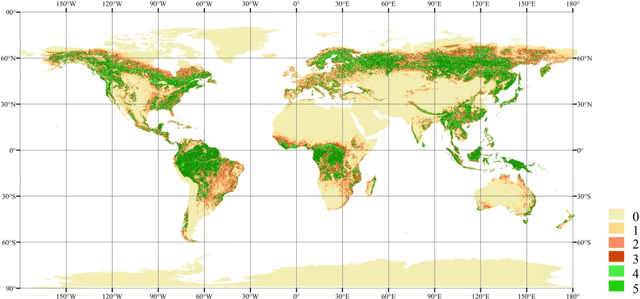
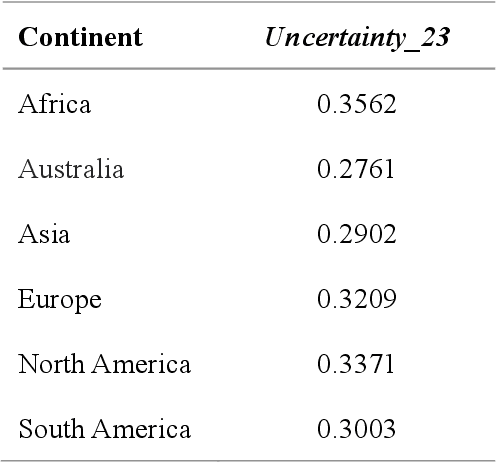
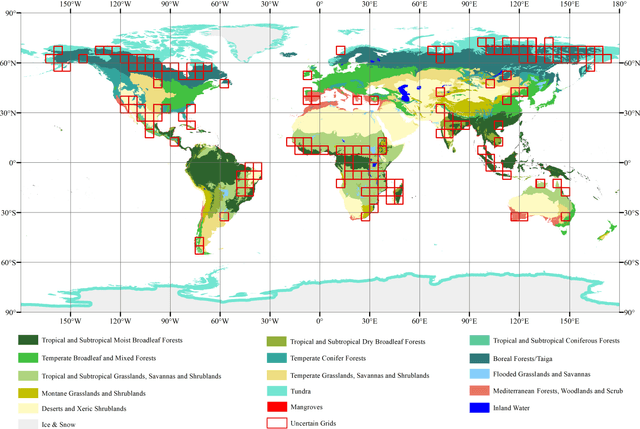
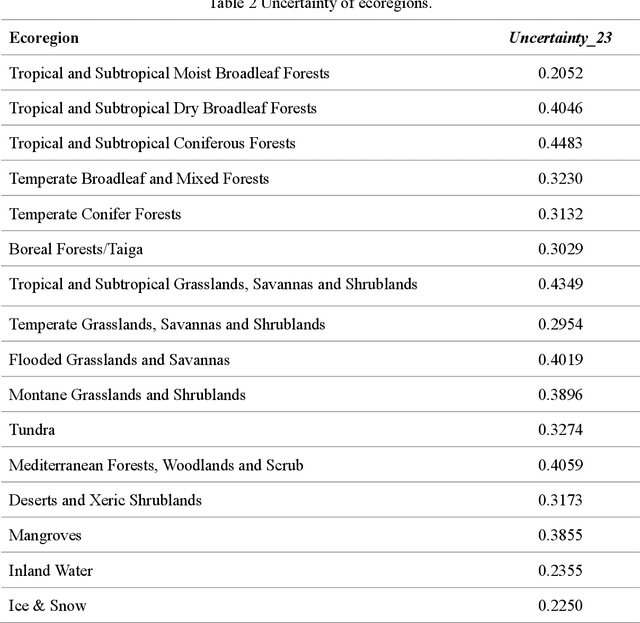
Global forest cover is critical to the provision of certain ecosystem services. With the advent of the google earth engine cloud platform, fine resolution global land cover mapping task could be accomplished in a matter of days instead of years. The amount of global forest cover (GFC) products has been steadily increasing in the last decades. However, it's hard for users to select suitable one due to great differences between these products, and the accuracy of these GFC products has not been verified on global scale. To provide guidelines for users and producers, it is urgent to produce a validation sample set at the global level. However, this labeling task is time and labor consuming, which has been the main obstacle to the progress of global land cover mapping. In this research, a labor-efficient semi-automatic framework is introduced to build a biggest ever Forest Sample Set (FSS) contained 395280 scattered samples categorized as forest, shrubland, grassland, impervious surface, etc. On the other hand, to provide guidelines for the users, we comprehensively validated the local and global mapping accuracy of all existing 30m GFC products, and analyzed and mapped the agreement of them. Moreover, to provide guidelines for the producers, optimal sampling strategy was proposed to improve the global forest classification. Furthermore, a new global forest cover named GlobeForest2020 has been generated, which proved to improve the previous highest state-of-the-art accuracies (obtained by Gong et al., 2017) by 2.77% in uncertain grids and by 1.11% in certain grids.
Super-resolution-based Change Detection Network with Stacked Attention Module for Images with Different Resolutions
Feb 27, 2021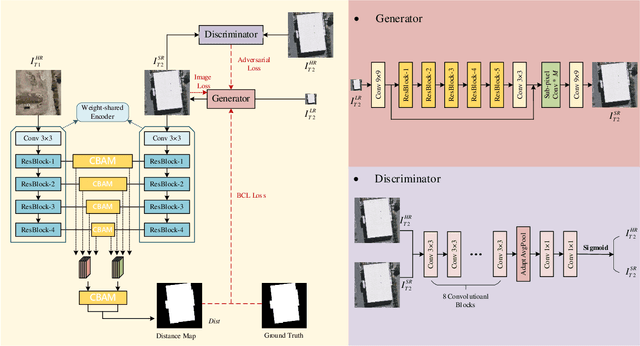

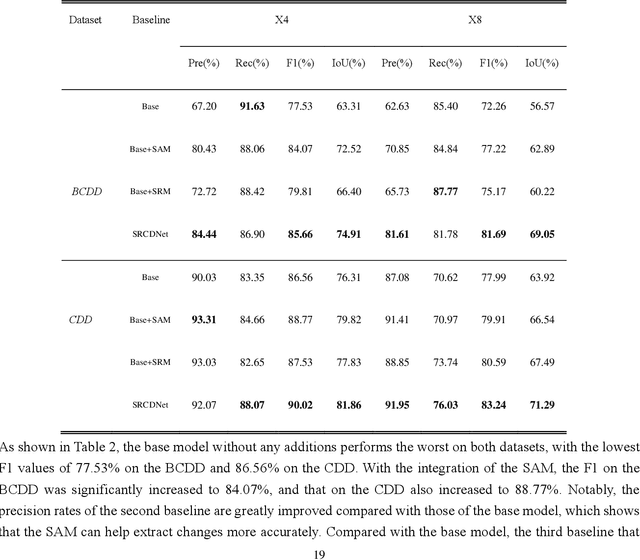

Change detection, which aims to distinguish surface changes based on bi-temporal images, plays a vital role in ecological protection and urban planning. Since high resolution (HR) images cannot be typically acquired continuously over time, bi-temporal images with different resolutions are often adopted for change detection in practical applications. Traditional subpixel-based methods for change detection using images with different resolutions may lead to substantial error accumulation when HR images are employed; this is because of intraclass heterogeneity and interclass similarity. Therefore, it is necessary to develop a novel method for change detection using images with different resolutions, that is more suitable for HR images. To this end, we propose a super-resolution-based change detection network (SRCDNet) with a stacked attention module. The SRCDNet employs a super resolution (SR) module containing a generator and a discriminator to directly learn SR images through adversarial learning and overcome the resolution difference between bi-temporal images. To enhance the useful information in multi-scale features, a stacked attention module consisting of five convolutional block attention modules (CBAMs) is integrated to the feature extractor. The final change map is obtained through a metric learning-based change decision module, wherein a distance map between bi-temporal features is calculated. The experimental results demonstrate the superiority of the proposed method, which not only outperforms all baselines -with the highest F1 scores of 87.40% on the building change detection dataset and 92.94% on the change detection dataset -but also obtains the best accuracies on experiments performed with images having a 4x and 8x resolution difference. The source code of SRCDNet will be available at https://github.com/liumency/SRCDNet.