 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo What Extent Do Token-Level Representations from Pathology Foundation Models Improve Dense Prediction?
Feb 03, 2026Pathology foundation models (PFMs) have rapidly advanced and are becoming a common backbone for downstream clinical tasks, offering strong transferability across tissues and institutions. However, for dense prediction (e.g., segmentation), practical deployment still lacks a clear, reproducible understanding of how different PFMs behave across datasets and how adaptation choices affect performance and stability. We present PFM-DenseBench, a large-scale benchmark for dense pathology prediction, evaluating 17 PFMs across 18 public segmentation datasets. Under a unified protocol, we systematically assess PFMs with multiple adaptation and fine-tuning strategies, and derive insightful, practice-oriented findings on when and why different PFMs and tuning choices succeed or fail across heterogeneous datasets. We release containers, configs, and dataset cards to enable reproducible evaluation and informed PFM selection for real-world dense pathology tasks. Project Website: https://m4a1tastegood.github.io/PFM-DenseBench
HookMIL: Revisiting Context Modeling in Multiple Instance Learning for Computational Pathology
Dec 20, 2025Multiple Instance Learning (MIL) has enabled weakly supervised analysis of whole-slide images (WSIs) in computational pathology. However, traditional MIL approaches often lose crucial contextual information, while transformer-based variants, though more expressive, suffer from quadratic complexity and redundant computations. To address these limitations, we propose HookMIL, a context-aware and computationally efficient MIL framework that leverages compact, learnable hook tokens for structured contextual aggregation. These tokens can be initialized from (i) key-patch visual features, (ii) text embeddings from vision-language pathology models, and (iii) spatially grounded features from spatial transcriptomics-vision models. This multimodal initialization enables Hook Tokens to incorporate rich textual and spatial priors, accelerating convergence and enhancing representation quality. During training, Hook tokens interact with instances through bidirectional attention with linear complexity. To further promote specialization, we introduce a Hook Diversity Loss that encourages each token to focus on distinct histopathological patterns. Additionally, a hook-to-hook communication mechanism refines contextual interactions while minimizing redundancy. Extensive experiments on four public pathology datasets demonstrate that HookMIL achieves state-of-the-art performance, with improved computational efficiency and interpretability. Codes are available at https://github.com/lingxitong/HookMIL.
Subspecialty-Specific Foundation Model for Intelligent Gastrointestinal Pathology
May 28, 2025Gastrointestinal (GI) diseases represent a clinically significant burden, necessitating precise diagnostic approaches to optimize patient outcomes. Conventional histopathological diagnosis, heavily reliant on the subjective interpretation of pathologists, suffers from limited reproducibility and diagnostic variability. To overcome these limitations and address the lack of pathology-specific foundation models for GI diseases, we develop Digepath, a specialized foundation model for GI pathology. Our framework introduces a dual-phase iterative optimization strategy combining pretraining with fine-screening, specifically designed to address the detection of sparsely distributed lesion areas in whole-slide images. Digepath is pretrained on more than 353 million image patches from over 200,000 hematoxylin and eosin-stained slides of GI diseases. It attains state-of-the-art performance on 33 out of 34 tasks related to GI pathology, including pathological diagnosis, molecular prediction, gene mutation prediction, and prognosis evaluation, particularly in diagnostically ambiguous cases and resolution-agnostic tissue classification.We further translate the intelligent screening module for early GI cancer and achieve near-perfect 99.6% sensitivity across 9 independent medical institutions nationwide. The outstanding performance of Digepath highlights its potential to bridge critical gaps in histopathological practice. This work not only advances AI-driven precision pathology for GI diseases but also establishes a transferable paradigm for other pathology subspecialties.
Multimodal Distillation-Driven Ensemble Learning for Long-Tailed Histopathology Whole Slide Images Analysis
Mar 02, 2025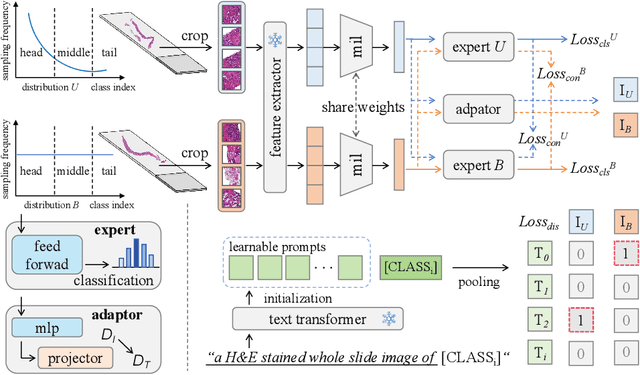


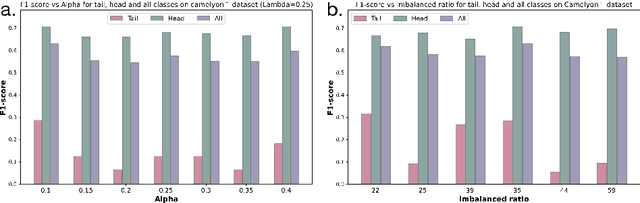
Multiple Instance Learning (MIL) plays a significant role in computational pathology, enabling weakly supervised analysis of Whole Slide Image (WSI) datasets. The field of WSI analysis is confronted with a severe long-tailed distribution problem, which significantly impacts the performance of classifiers. Long-tailed distributions lead to class imbalance, where some classes have sparse samples while others are abundant, making it difficult for classifiers to accurately identify minority class samples. To address this issue, we propose an ensemble learning method based on MIL, which employs expert decoders with shared aggregators and consistency constraints to learn diverse distributions and reduce the impact of class imbalance on classifier performance. Moreover, we introduce a multimodal distillation framework that leverages text encoders pre-trained on pathology-text pairs to distill knowledge and guide the MIL aggregator in capturing stronger semantic features relevant to class information. To ensure flexibility, we use learnable prompts to guide the distillation process of the pre-trained text encoder, avoiding limitations imposed by specific prompts. Our method, MDE-MIL, integrates multiple expert branches focusing on specific data distributions to address long-tailed issues. Consistency control ensures generalization across classes. Multimodal distillation enhances feature extraction. Experiments on Camelyon+-LT and PANDA-LT datasets show it outperforms state-of-the-art methods.
Can We Simplify Slide-level Fine-tuning of Pathology Foundation Models?
Feb 28, 2025The emergence of foundation models in computational pathology has transformed histopathological image analysis, with whole slide imaging (WSI) diagnosis being a core application. Traditionally, weakly supervised fine-tuning via multiple instance learning (MIL) has been the primary method for adapting foundation models to WSIs. However, in this work we present a key experimental finding: a simple nonlinear mapping strategy combining mean pooling and a multilayer perceptron, called SiMLP, can effectively adapt patch-level foundation models to slide-level tasks without complex MIL-based learning. Through extensive experiments across diverse downstream tasks, we demonstrate the superior performance of SiMLP with state-of-the-art methods. For instance, on a large-scale pan-cancer classification task, SiMLP surpasses popular MIL-based methods by 3.52%. Furthermore, SiMLP shows strong learning ability in few-shot classification and remaining highly competitive with slide-level foundation models pretrained on tens of thousands of slides. Finally, SiMLP exhibits remarkable robustness and transferability in lung cancer subtyping. Overall, our findings challenge the conventional MIL-based fine-tuning paradigm, demonstrating that a task-agnostic representation strategy alone can effectively adapt foundation models to WSI analysis. These insights offer a unique and meaningful perspective for future research in digital pathology, paving the way for more efficient and broadly applicable methodologies.
Agent Aggregator with Mask Denoise Mechanism for Histopathology Whole Slide Image Analysis
Sep 18, 2024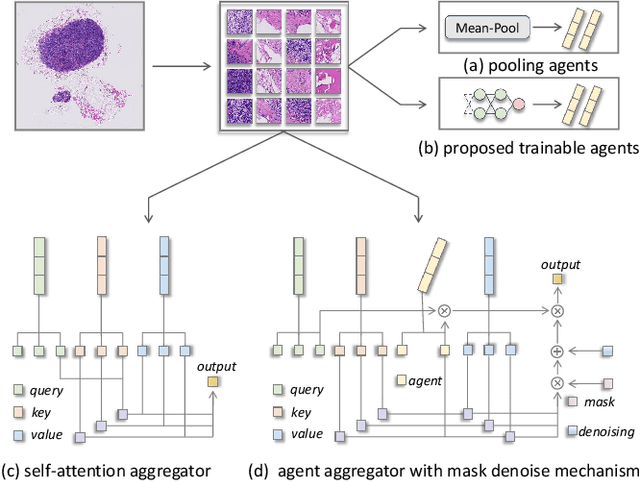
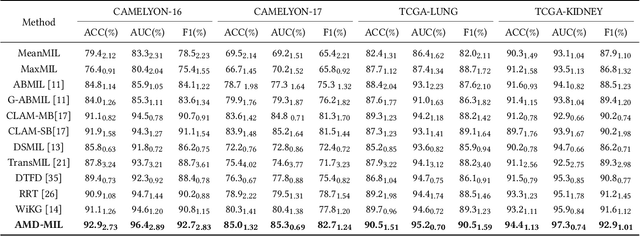
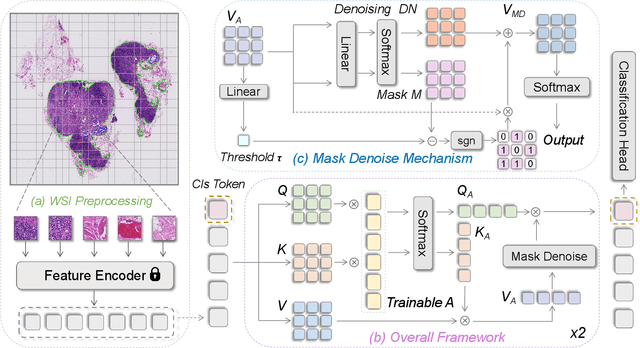
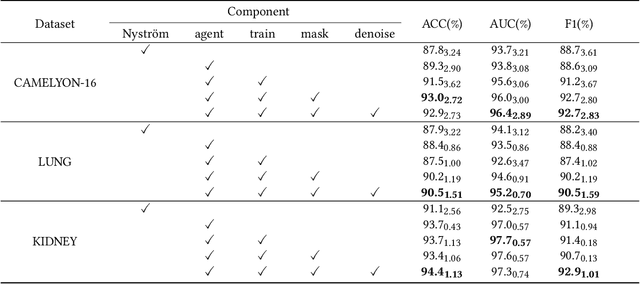
Histopathology analysis is the gold standard for medical diagnosis. Accurate classification of whole slide images (WSIs) and region-of-interests (ROIs) localization can assist pathologists in diagnosis. The gigapixel resolution of WSI and the absence of fine-grained annotations make direct classification and analysis challenging. In weakly supervised learning, multiple instance learning (MIL) presents a promising approach for WSI classification. The prevailing strategy is to use attention mechanisms to measure instance importance for classification. However, attention mechanisms fail to capture inter-instance information, and self-attention causes quadratic computational complexity. To address these challenges, we propose AMD-MIL, an agent aggregator with a mask denoise mechanism. The agent token acts as an intermediate variable between the query and key for computing instance importance. Mask and denoising matrices, mapped from agents-aggregated value, dynamically mask low-contribution representations and eliminate noise. AMD-MIL achieves better attention allocation by adjusting feature representations, capturing micro-metastases in cancer, and improving interpretability. Extensive experiments on CAMELYON-16, CAMELYON-17, TCGA-KIDNEY, and TCGA-LUNG show AMD-MIL's superiority over state-of-the-art methods.