 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGloPath: An Entity-Centric Foundation Model for Glomerular Lesion Assessment and Clinicopathological Insights
Mar 03, 2026Glomerular pathology is central to the diagnosis and prognosis of renal diseases, yet the heterogeneity of glomerular morphology and fine-grained lesion patterns remain challenging for current AI approaches. We present GloPath, an entity-centric foundation model trained on over one million glomeruli extracted from 14,049 renal biopsy specimens using multi-scale and multi-view self-supervised learning. GloPath addresses two major challenges in nephropathology: glomerular lesion assessment and clinicopathological insights discovery. For lesion assessment, GloPath was benchmarked across three independent cohorts on 52 tasks, including lesion recognition, grading, few-shot classification, and cross-modality diagnosis-outperforming state-of-the-art methods in 42 tasks (80.8%). In the large-scale real-world study, it achieved an ROC-AUC of 91.51% for lesion recognition, demonstrating strong robustness in routine clinical settings. For clinicopathological insights, GloPath systematically revealed statistically significant associations between glomerular morphological parameters and clinical indicators across 224 morphology-clinical variable pairs, demonstrating its capacity to connect tissue-level pathology with patient-level outcomes. Together, these results position GloPath as a scalable and interpretable platform for glomerular lesion assessment and clinicopathological discovery, representing a step toward clinically translatable AI in renal pathology.
Topology-aware Pathological Consistency Matching for Weakly-Paired IHC Virtual Staining
Jan 06, 2026Immunohistochemical (IHC) staining provides crucial molecular characterization of tissue samples and plays an indispensable role in the clinical examination and diagnosis of cancers. However, compared with the commonly used Hematoxylin and Eosin (H&E) staining, IHC staining involves complex procedures and is both time-consuming and expensive, which limits its widespread clinical use. Virtual staining converts H&E images to IHC images, offering a cost-effective alternative to clinical IHC staining. Nevertheless, using adjacent slides as ground truth often results in weakly-paired data with spatial misalignment and local deformations, hindering effective supervised learning. To address these challenges, we propose a novel topology-aware framework for H&E-to-IHC virtual staining. Specifically, we introduce a Topology-aware Consistency Matching (TACM) mechanism that employs graph contrastive learning and topological perturbations to learn robust matching patterns despite spatial misalignments, ensuring structural consistency. Furthermore, we propose a Topology-constrained Pathological Matching (TCPM) mechanism that aligns pathological positive regions based on node importance to enhance pathological consistency. Extensive experiments on two benchmarks across four staining tasks demonstrate that our method outperforms state-of-the-art approaches, achieving superior generation quality with higher clinical relevance.
NL2Repo-Bench: Towards Long-Horizon Repository Generation Evaluation of Coding Agents
Dec 14, 2025Recent advances in coding agents suggest rapid progress toward autonomous software development, yet existing benchmarks fail to rigorously evaluate the long-horizon capabilities required to build complete software systems. Most prior evaluations focus on localized code generation, scaffolded completion, or short-term repair tasks, leaving open the question of whether agents can sustain coherent reasoning, planning, and execution over the extended horizons demanded by real-world repository construction. To address this gap, we present NL2Repo Bench, a benchmark explicitly designed to evaluate the long-horizon repository generation ability of coding agents. Given only a single natural-language requirements document and an empty workspace, agents must autonomously design the architecture, manage dependencies, implement multi-module logic, and produce a fully installable Python library. Our experiments across state-of-the-art open- and closed-source models reveal that long-horizon repository generation remains largely unsolved: even the strongest agents achieve below 40% average test pass rates and rarely complete an entire repository correctly. Detailed analysis uncovers fundamental long-horizon failure modes, including premature termination, loss of global coherence, fragile cross-file dependencies, and inadequate planning over hundreds of interaction steps. NL2Repo Bench establishes a rigorous, verifiable testbed for measuring sustained agentic competence and highlights long-horizon reasoning as a central bottleneck for the next generation of autonomous coding agents.
MSMT-FN: Multi-segment Multi-task Fusion Network for Marketing Audio Classification
Nov 14, 2025Audio classification plays an essential role in sentiment analysis and emotion recognition, especially for analyzing customer attitudes in marketing phone calls. Efficiently categorizing customer purchasing propensity from large volumes of audio data remains challenging. In this work, we propose a novel Multi-Segment Multi-Task Fusion Network (MSMT-FN) that is uniquely designed for addressing this business demand. Evaluations conducted on our proprietary MarketCalls dataset, as well as established benchmarks (CMU-MOSI, CMU-MOSEI, and MELD), show MSMT-FN consistently outperforms or matches state-of-the-art methods. Additionally, our newly curated MarketCalls dataset will be available upon request, and the code base is made accessible at GitHub Repository MSMT-FN, to facilitate further research and advancements in audio classification domain.
CartoonAlive: Towards Expressive Live2D Modeling from Single Portraits
Jul 23, 2025With the rapid advancement of large foundation models, AIGC, cloud rendering, and real-time motion capture technologies, digital humans are now capable of achieving synchronized facial expressions and body movements, engaging in intelligent dialogues driven by natural language, and enabling the fast creation of personalized avatars. While current mainstream approaches to digital humans primarily focus on 3D models and 2D video-based representations, interactive 2D cartoon-style digital humans have received relatively less attention. Compared to 3D digital humans that require complex modeling and high rendering costs, and 2D video-based solutions that lack flexibility and real-time interactivity, 2D cartoon-style Live2D models offer a more efficient and expressive alternative. By simulating 3D-like motion through layered segmentation without the need for traditional 3D modeling, Live2D enables dynamic and real-time manipulation. In this technical report, we present CartoonAlive, an innovative method for generating high-quality Live2D digital humans from a single input portrait image. CartoonAlive leverages the shape basis concept commonly used in 3D face modeling to construct facial blendshapes suitable for Live2D. It then infers the corresponding blendshape weights based on facial keypoints detected from the input image. This approach allows for the rapid generation of a highly expressive and visually accurate Live2D model that closely resembles the input portrait, within less than half a minute. Our work provides a practical and scalable solution for creating interactive 2D cartoon characters, opening new possibilities in digital content creation and virtual character animation. The project homepage is https://human3daigc.github.io/CartoonAlive_webpage/.
Diffusion-based Virtual Staining from Polarimetric Mueller Matrix Imaging
Mar 03, 2025


Polarization, as a new optical imaging tool, has been explored to assist in the diagnosis of pathology. Moreover, converting the polarimetric Mueller Matrix (MM) to standardized stained images becomes a promising approach to help pathologists interpret the results. However, existing methods for polarization-based virtual staining are still in the early stage, and the diffusion-based model, which has shown great potential in enhancing the fidelity of the generated images, has not been studied yet. In this paper, a Regulated Bridge Diffusion Model (RBDM) for polarization-based virtual staining is proposed. RBDM utilizes the bidirectional bridge diffusion process to learn the mapping from polarization images to other modalities such as H\&E and fluorescence. And to demonstrate the effectiveness of our model, we conduct the experiment on our manually collected dataset, which consists of 18,000 paired polarization, fluorescence and H\&E images, due to the unavailability of the public dataset. The experiment results show that our model greatly outperforms other benchmark methods. Our dataset and code will be released upon acceptance.
Can We Simplify Slide-level Fine-tuning of Pathology Foundation Models?
Feb 28, 2025The emergence of foundation models in computational pathology has transformed histopathological image analysis, with whole slide imaging (WSI) diagnosis being a core application. Traditionally, weakly supervised fine-tuning via multiple instance learning (MIL) has been the primary method for adapting foundation models to WSIs. However, in this work we present a key experimental finding: a simple nonlinear mapping strategy combining mean pooling and a multilayer perceptron, called SiMLP, can effectively adapt patch-level foundation models to slide-level tasks without complex MIL-based learning. Through extensive experiments across diverse downstream tasks, we demonstrate the superior performance of SiMLP with state-of-the-art methods. For instance, on a large-scale pan-cancer classification task, SiMLP surpasses popular MIL-based methods by 3.52%. Furthermore, SiMLP shows strong learning ability in few-shot classification and remaining highly competitive with slide-level foundation models pretrained on tens of thousands of slides. Finally, SiMLP exhibits remarkable robustness and transferability in lung cancer subtyping. Overall, our findings challenge the conventional MIL-based fine-tuning paradigm, demonstrating that a task-agnostic representation strategy alone can effectively adapt foundation models to WSI analysis. These insights offer a unique and meaningful perspective for future research in digital pathology, paving the way for more efficient and broadly applicable methodologies.
Textoon: Generating Vivid 2D Cartoon Characters from Text Descriptions
Jan 17, 2025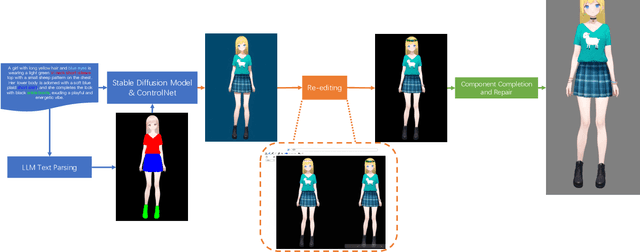
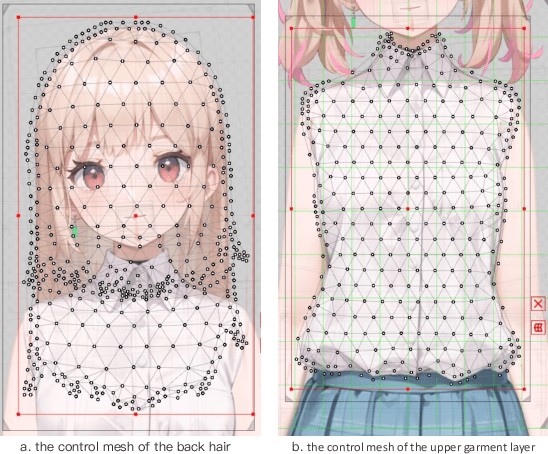
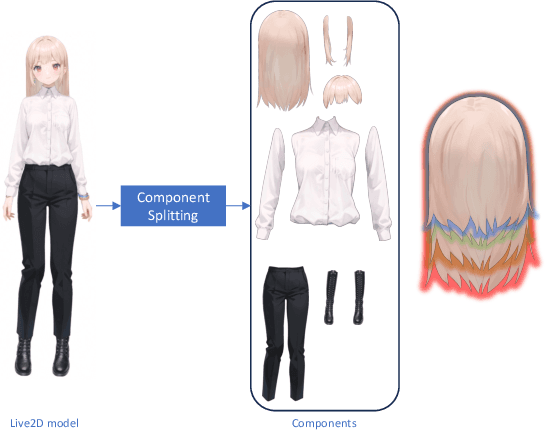

The 2D cartoon style is a prominent art form in digital character creation, particularly popular among younger audiences. While advancements in digital human technology have spurred extensive research into photorealistic digital humans and 3D characters, interactive 2D cartoon characters have received comparatively less attention. Unlike 3D counterparts, which require sophisticated construction and resource-intensive rendering, Live2D, a widely-used format for 2D cartoon characters, offers a more efficient alternative, which allows to animate 2D characters in a manner that simulates 3D movement without the necessity of building a complete 3D model. Furthermore, Live2D employs lightweight HTML5 (H5) rendering, improving both accessibility and efficiency. In this technical report, we introduce Textoon, an innovative method for generating diverse 2D cartoon characters in the Live2D format based on text descriptions. The Textoon leverages cutting-edge language and vision models to comprehend textual intentions and generate 2D appearance, capable of creating a wide variety of stunning and interactive 2D characters within one minute. The project homepage is https://human3daigc.github.io/Textoon_webpage/.
Unlocking adaptive digital pathology through dynamic feature learning
Dec 29, 2024



Foundation models have revolutionized the paradigm of digital pathology, as they leverage general-purpose features to emulate real-world pathological practices, enabling the quantitative analysis of critical histological patterns and the dissection of cancer-specific signals. However, these static general features constrain the flexibility and pathological relevance in the ever-evolving needs of clinical applications, hindering the broad use of the current models. Here we introduce PathFiT, a dynamic feature learning method that can be effortlessly plugged into various pathology foundation models to unlock their adaptability. Meanwhile, PathFiT performs seamless implementation across diverse pathology applications regardless of downstream specificity. To validate PathFiT, we construct a digital pathology benchmark with over 20 terabytes of Internet and real-world data comprising 28 H\&E-stained tasks and 7 specialized imaging tasks including Masson's Trichrome staining and immunofluorescence images. By applying PathFiT to the representative pathology foundation models, we demonstrate state-of-the-art performance on 34 out of 35 tasks, with significant improvements on 23 tasks and outperforming by 10.20% on specialized imaging tasks. The superior performance and versatility of PathFiT open up new avenues in computational pathology.
Interpretable modulated differentiable STFT and physics-informed balanced spectrum metric for freight train wheelset bearing cross-machine transfer fault diagnosis under speed fluctuations
Jun 17, 2024



The service conditions of wheelset bearings has a direct impact on the safe operation of railway heavy haul freight trains as the key components. However, speed fluctuation of the trains and few fault samples are the two main problems that restrict the accuracy of bearing fault diagnosis. Therefore, a cross-machine transfer diagnosis (pyDSN) network coupled with interpretable modulated differentiable short-time Fourier transform (STFT) and physics-informed balanced spectrum quality metric is proposed to learn domain-invariant and discriminative features under time-varying speeds. Firstly, due to insufficiency in extracting extract frequency components of time-varying speed signals using fixed windows, a modulated differentiable STFT (MDSTFT) that is interpretable with STFT-informed theoretical support, is proposed to extract the robust time-frequency spectrum (TFS). During training process, multiple windows with different lengths dynamically change. Also, in addition to the classification metric and domain discrepancy metric, we creatively introduce a third kind of metric, referred to as the physics-informed metric, to enhance transferable TFS. A physics-informed balanced spectrum quality (BSQ) regularization loss is devised to guide an optimization direction for MDSTFT and model. With it, not only can model acquire high-quality TFS, but also a physics-restricted domain adaptation network can be also acquired, making it learn real-world physics knowledge, ultimately diminish the domain discrepancy across different datasets. The experiment is conducted in the scenario of migrating from the laboratory datasets to the freight train dataset, indicating that the hybrid-driven pyDSN outperforms existing methods and has practical value.