 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarmonic enhancement using learnable comb filter for light-weight full-band speech enhancement model
Jun 01, 2023



With fewer feature dimensions, filter banks are often used in light-weight full-band speech enhancement models. In order to further enhance the coarse speech in the sub-band domain, it is necessary to apply a post-filtering for harmonic retrieval. The signal processing-based comb filters used in RNNoise and PercepNet have limited performance and may cause speech quality degradation due to inaccurate fundamental frequency estimation. To tackle this problem, we propose a learnable comb filter to enhance harmonics. Based on the sub-band model, we design a DNN-based fundamental frequency estimator to estimate the discrete fundamental frequencies and a comb filter for harmonic enhancement, which are trained via an end-to-end pattern. The experiments show the advantages of our proposed method over PecepNet and DeepFilterNet.
Personalized speech enhancement combining band-split RNN and speaker attentive module
Feb 20, 2023
Target speaker information can be utilized in speech enhancement (SE) models to more effectively extract the desired speech. Previous works introduce the speaker embedding into speech enhancement models by means of concatenation or affine transformation. In this paper, we propose a speaker attentive module to calculate the attention scores between the speaker embedding and the intermediate features, which are used to rescale the features. By merging this module in the state-of-the-art SE model, we construct the personalized SE model for ICASSP Signal Processing Grand Challenge: DNS Challenge 5 (2023). Our system achieves a final score of 0.529 on the blind test set of track1 and 0.549 on track2.
Inference skipping for more efficient real-time speech enhancement with parallel RNNs
Jul 22, 2022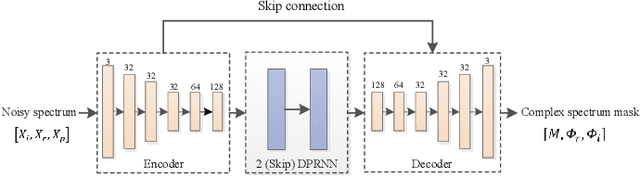
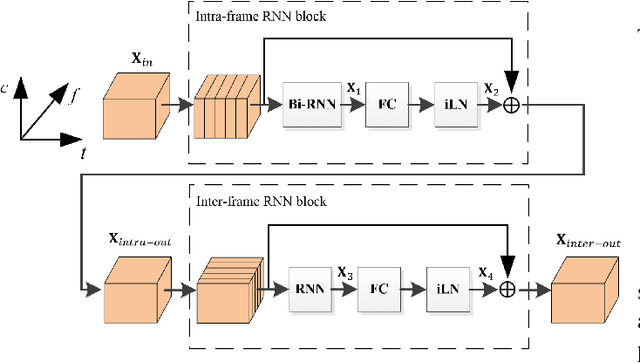
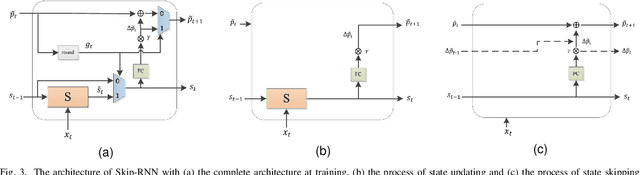
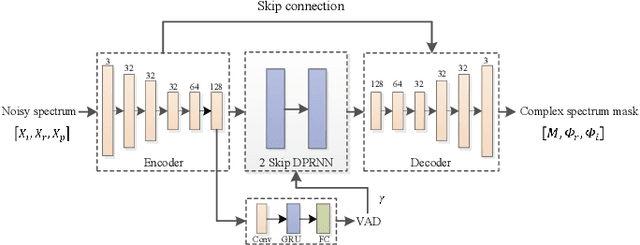
Deep neural network (DNN) based speech enhancement models have attracted extensive attention due to their promising performance. However, it is difficult to deploy a powerful DNN in real-time applications because of its high computational cost. Typical compression methods such as pruning and quantization do not make good use of the data characteristics. In this paper, we introduce the Skip-RNN strategy into speech enhancement models with parallel RNNs. The states of the RNNs update intermittently without interrupting the update of the output mask, which leads to significant reduction of computational load without evident audio artifacts. To better leverage the difference between the voice and the noise, we further regularize the skipping strategy with voice activity detection (VAD) guidance, saving more computational load. Experiments on a high-performance speech enhancement model, dual-path convolutional recurrent network (DPCRN), show the superiority of our strategy over strategies like network pruning or directly training a smaller model. We also validate the generalization of the proposed strategy on two other competitive speech enhancement models.
A light-weight full-band speech enhancement model
Jul 03, 2022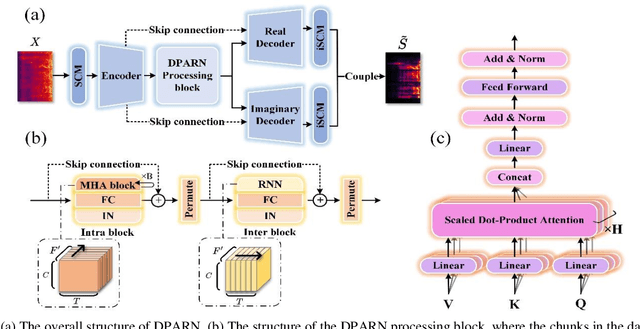
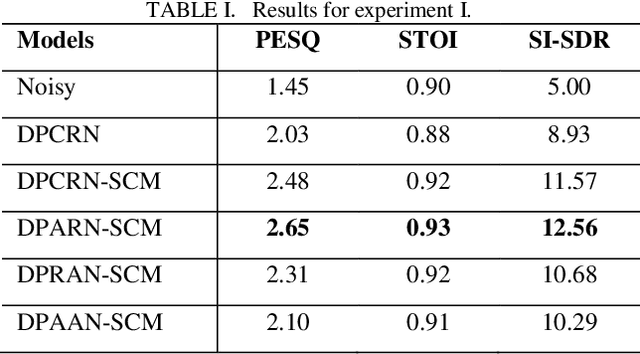
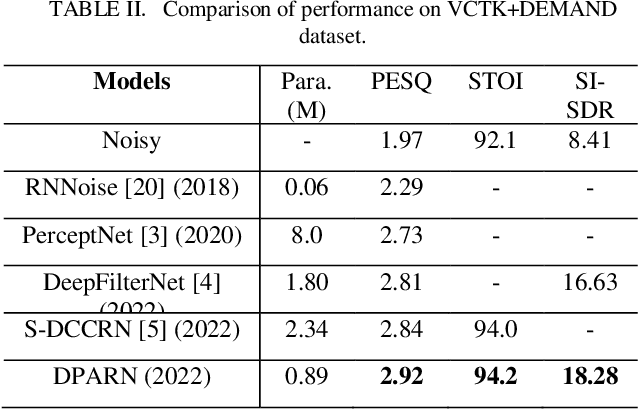
Deep neural network based full-band speech enhancement systems face challenges of high demand of computational resources and imbalanced frequency distribution. In this paper, a light-weight full-band model is proposed with two dedicated strategies, i.e., a learnable spectral compression mapping for more effective high-band spectral information compression, and the utilization of the multi-head attention mechanism for more effective modeling of the global spectral pattern. Experiments validate the efficacy of the proposed strategies and show that the proposed model achieves competitive performance with only 0.89M parameters.
DPCRN: Dual-Path Convolution Recurrent Network for Single Channel Speech Enhancement
Jul 12, 2021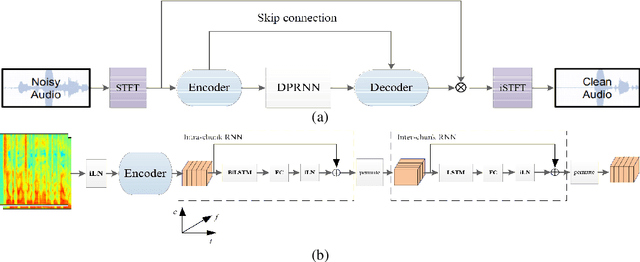
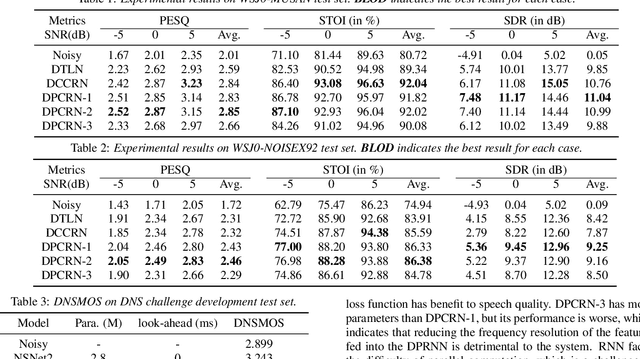
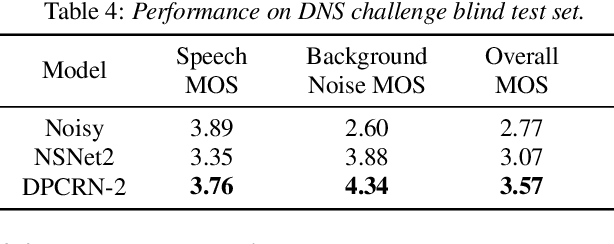
The dual-path RNN (DPRNN) was proposed to more effectively model extremely long sequences for speech separation in the time domain. By splitting long sequences to smaller chunks and applying intra-chunk and inter-chunk RNNs, the DPRNN reached promising performance in speech separation with a limited model size. In this paper, we combine the DPRNN module with Convolution Recurrent Network (CRN) and design a model called Dual-Path Convolution Recurrent Network (DPCRN) for speech enhancement in the time-frequency domain. We replace the RNNs in the CRN with DPRNN modules, where the intra-chunk RNNs are used to model the spectrum pattern in a single frame and the inter-chunk RNNs are used to model the dependence between consecutive frames. With only 0.8M parameters, the submitted DPCRN model achieves an overall mean opinion score (MOS) of 3.57 in the wide band scenario track of the Interspeech 2021 Deep Noise Suppression (DNS) challenge. Evaluations on some other test sets also show the efficacy of our model.