 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS$^2$Voice: Style-Aware Autoregressive Modeling with Enhanced Conditioning for Singing Style Conversion
Jan 20, 2026We present S$^2$Voice, the winning system of the Singing Voice Conversion Challenge (SVCC) 2025 for both the in-domain and zero-shot singing style conversion tracks. Built on the strong two-stage Vevo baseline, S$^2$Voice advances style control and robustness through several contributions. First, we integrate style embeddings into the autoregressive large language model (AR LLM) via a FiLM-style layer-norm conditioning and a style-aware cross-attention for enhanced fine-grained style modeling. Second, we introduce a global speaker embedding into the flow-matching transformer to improve timbre similarity. Third, we curate a large, high-quality singing corpus via an automated pipeline for web harvesting, vocal separation, and transcript refinement. Finally, we employ a multi-stage training strategy combining supervised fine-tuning (SFT) and direct preference optimization (DPO). Subjective listening tests confirm our system's superior performance: leading in style similarity and singer similarity for Task 1, and across naturalness, style similarity, and singer similarity for Task 2. Ablation studies demonstrate the effectiveness of our contributions in enhancing style fidelity, timbre preservation, and generalization. Audio samples are available~\footnote{https://honee-w.github.io/SVC-Challenge-Demo/}.
UniFlow: Unifying Speech Front-End Tasks via Continuous Generative Modeling
Aug 11, 2025Generative modeling has recently achieved remarkable success across image, video, and audio domains, demonstrating powerful capabilities for unified representation learning. Yet speech front-end tasks such as speech enhancement (SE), target speaker extraction (TSE), acoustic echo cancellation (AEC), and language-queried source separation (LASS) remain largely tackled by disparate, task-specific solutions. This fragmentation leads to redundant engineering effort, inconsistent performance, and limited extensibility. To address this gap, we introduce UniFlow, a unified framework that employs continuous generative modeling to tackle diverse speech front-end tasks in a shared latent space. Specifically, UniFlow utilizes a waveform variational autoencoder (VAE) to learn a compact latent representation of raw audio, coupled with a Diffusion Transformer (DiT) that predicts latent updates. To differentiate the speech processing task during the training, learnable condition embeddings indexed by a task ID are employed to enable maximal parameter sharing while preserving task-specific adaptability. To balance model performance and computational efficiency, we investigate and compare three generative objectives: denoising diffusion, flow matching, and mean flow within the latent domain. We validate UniFlow on multiple public benchmarks, demonstrating consistent gains over state-of-the-art baselines. UniFlow's unified latent formulation and conditional design make it readily extensible to new tasks, providing an integrated foundation for building and scaling generative speech processing pipelines. To foster future research, we will open-source our codebase.
U-SAM: An audio language Model for Unified Speech, Audio, and Music Understanding
May 20, 2025The text generation paradigm for audio tasks has opened new possibilities for unified audio understanding. However, existing models face significant challenges in achieving a comprehensive understanding across diverse audio types, such as speech, general audio events, and music. Furthermore, their exclusive reliance on cross-entropy loss for alignment often falls short, as it treats all tokens equally and fails to account for redundant audio features, leading to weaker cross-modal alignment. To deal with the above challenges, this paper introduces U-SAM, an advanced audio language model that integrates specialized encoders for speech, audio, and music with a pre-trained large language model (LLM). U-SAM employs a Mixture of Experts (MoE) projector for task-aware feature fusion, dynamically routing and integrating the domain-specific encoder outputs. Additionally, U-SAM incorporates a Semantic-Aware Contrastive Loss Module, which explicitly identifies redundant audio features under language supervision and rectifies their semantic and spectral representations to enhance cross-modal alignment. Extensive experiments demonstrate that U-SAM consistently outperforms both specialized models and existing audio language models across multiple benchmarks. Moreover, it exhibits emergent capabilities on unseen tasks, showcasing its generalization potential. Code is available (https://github.com/Honee-W/U-SAM/).
RaD-Net 2: A causal two-stage repairing and denoising speech enhancement network with knowledge distillation and complex axial self-attention
Jun 11, 2024



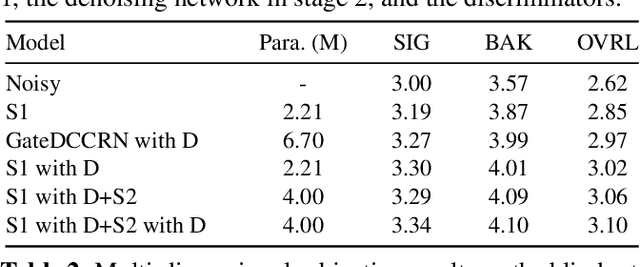
In real-time speech communication systems, speech signals are often degraded by multiple distortions. Recently, a two-stage Repair-and-Denoising network (RaD-Net) was proposed with superior speech quality improvement in the ICASSP 2024 Speech Signal Improvement (SSI) Challenge. However, failure to use future information and constraint receptive field of convolution layers limit the system's performance. To mitigate these problems, we extend RaD-Net to its upgraded version, RaD-Net 2. Specifically, a causality-based knowledge distillation is introduced in the first stage to use future information in a causal way. We use the non-causal repairing network as the teacher to improve the performance of the causal repairing network. In addition, in the second stage, complex axial self-attention is applied in the denoising network's complex feature encoder/decoder. Experimental results on the ICASSP 2024 SSI Challenge blind test set show that RaD-Net 2 brings 0.10 OVRL DNSMOS improvement compared to RaD-Net.
BS-PLCNet 2: Two-stage Band-split Packet Loss Concealment Network with Intra-model Knowledge Distillation
Jun 10, 2024



Audio packet loss is an inevitable problem in real-time speech communication. A band-split packet loss concealment network (BS-PLCNet) targeting full-band signals was recently proposed. Although it performs superiorly in the ICASSP 2024 PLC Challenge, BS-PLCNet is a large model with high computational complexity of 8.95G FLOPS. This paper presents its updated version, BS-PLCNet 2, to reduce computational complexity and improve performance further. Specifically, to compensate for the missing future information, in the wide-band module, we design a dual-path encoder structure (with non-causal and causal path) and leverage an intra-model knowledge distillation strategy to distill the future information from the non-causal teacher to the casual student. Moreover, we introduce a lightweight post-processing module after packet loss restoration to recover speech distortions and remove residual noise in the audio signal. With only 40% of original parameters in BS-PLCNet, BS-PLCNet 2 brings 0.18 PLCMOS improvement on the ICASSP 2024 PLC challenge blind set, achieving state-of-the-art performance on this dataset.
An Intra-BRNN and GB-RVQ Based END-TO-END Neural Audio Codec
Feb 02, 2024



Recently, neural networks have proven to be effective in performing speech coding task at low bitrates. However, under-utilization of intra-frame correlations and the error of quantizer specifically degrade the reconstructed audio quality. To improve the coding quality, we present an end-to-end neural speech codec, namely CBRC (Convolutional and Bidirectional Recurrent neural Codec). An interleaved structure using 1D-CNN and Intra-BRNN is designed to exploit the intra-frame correlations more efficiently. Furthermore, Group-wise and Beam-search Residual Vector Quantizer (GB-RVQ) is used to reduce the quantization noise. CBRC encodes audio every 20ms with no additional latency, which is suitable for real-time communication. Experimental results demonstrate the superiority of the proposed codec when comparing CBRC at 3kbps with Opus at 12kbps.
RaD-Net: A Repairing and Denoising Network for Speech Signal Improvement
Jan 09, 2024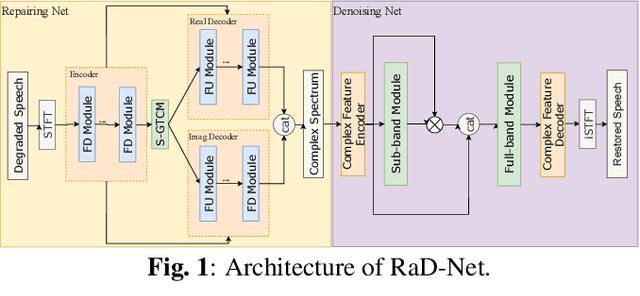
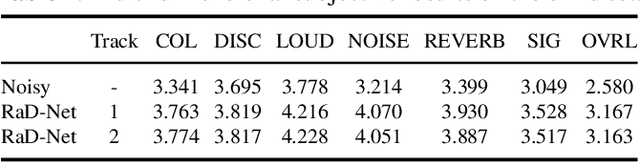
This paper introduces our repairing and denoising network (RaD-Net) for the ICASSP 2024 Speech Signal Improvement (SSI) Challenge. We extend our previous framework based on a two-stage network and propose an upgraded model. Specifically, we replace the repairing network with COM-Net from TEA-PSE. In addition, multi-resolution discriminators and multi-band discriminators are adopted in the training stage. Finally, we use a three-step training strategy to optimize our model. We submit two models with different sets of parameters to meet the RTF requirement of the two tracks. According to the official results, the proposed systems rank 2nd in track 1 and 3rd in track 2.
BS-PLCNet: Band-split Packet Loss Concealment Network with Multi-task Learning Framework and Multi-discriminators
Jan 08, 2024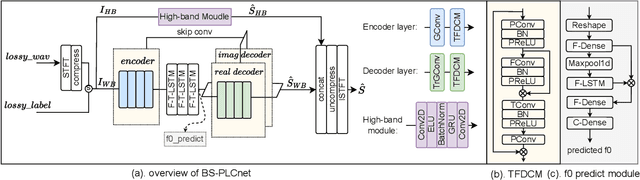

Packet loss is a common and unavoidable problem in voice over internet phone (VoIP) systems. To deal with the problem, we propose a band-split packet loss concealment network (BS-PLCNet). Specifically, we split the full-band signal into wide-band (0-8kHz) and high-band (8-24kHz). The wide-band signals are processed by a gated convolutional recurrent network (GCRN), while the high-band counterpart is processed by a simple GRU network. To ensure high speech quality and automatic speech recognition (ASR) compatibility, multi-task learning (MTL) framework including fundamental frequency (f0) prediction, linguistic awareness, and multi-discriminators are used. The proposed approach tied for 1st place in the ICASSP 2024 PLC Challenge.
An Exploration of Task-decoupling on Two-stage Neural Post Filter for Real-time Personalized Acoustic Echo Cancellation
Oct 07, 2023Deep learning based techniques have been popularly adopted in acoustic echo cancellation (AEC). Utilization of speaker representation has extended the frontier of AEC, thus attracting many researchers' interest in personalized acoustic echo cancellation (PAEC). Meanwhile, task-decoupling strategies are widely adopted in speech enhancement. To further explore the task-decoupling approach, we propose to use a two-stage task-decoupling post-filter (TDPF) in PAEC. Furthermore, a multi-scale local-global speaker representation is applied to improve speaker extraction in PAEC. Experimental results indicate that the task-decoupling model can yield better performance than a single joint network. The optimal approach is to decouple the echo cancellation from noise and interference speech suppression. Based on the task-decoupling sequence, optimal training strategies for the two-stage model are explored afterwards.
Harmonic enhancement using learnable comb filter for light-weight full-band speech enhancement model
Jun 01, 2023



With fewer feature dimensions, filter banks are often used in light-weight full-band speech enhancement models. In order to further enhance the coarse speech in the sub-band domain, it is necessary to apply a post-filtering for harmonic retrieval. The signal processing-based comb filters used in RNNoise and PercepNet have limited performance and may cause speech quality degradation due to inaccurate fundamental frequency estimation. To tackle this problem, we propose a learnable comb filter to enhance harmonics. Based on the sub-band model, we design a DNN-based fundamental frequency estimator to estimate the discrete fundamental frequencies and a comb filter for harmonic enhancement, which are trained via an end-to-end pattern. The experiments show the advantages of our proposed method over PecepNet and DeepFilterNet.