 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoFree: Towards Ultra Lightweight and Efficient Neural Acoustic Echo Cancellation
Aug 08, 2025In recent years, neural networks (NNs) have been widely applied in acoustic echo cancellation (AEC). However, existing approaches struggle to meet real-world low-latency and computational requirements while maintaining performance. To address this challenge, we propose EchoFree, an ultra lightweight neural AEC framework that combines linear filtering with a neural post filter. Specifically, we design a neural post-filter operating on Bark-scale spectral features. Furthermore, we introduce a two-stage optimization strategy utilizing self-supervised learning (SSL) models to improve model performance. We evaluate our method on the blind test set of the ICASSP 2023 AEC Challenge. The results demonstrate that our model, with only 278K parameters and 30 MMACs computational complexity, outperforms existing low-complexity AEC models and achieves performance comparable to that of state-of-the-art lightweight model DeepVQE-S. The audio examples are available.
FlowSE: Efficient and High-Quality Speech Enhancement via Flow Matching
May 26, 2025Generative models have excelled in audio tasks using approaches such as language models, diffusion, and flow matching. However, existing generative approaches for speech enhancement (SE) face notable challenges: language model-based methods suffer from quantization loss, leading to compromised speaker similarity and intelligibility, while diffusion models require complex training and high inference latency. To address these challenges, we propose FlowSE, a flow-matching-based model for SE. Flow matching learns a continuous transformation between noisy and clean speech distributions in a single pass, significantly reducing inference latency while maintaining high-quality reconstruction. Specifically, FlowSE trains on noisy mel spectrograms and optional character sequences, optimizing a conditional flow matching loss with ground-truth mel spectrograms as supervision. It implicitly learns speech's temporal-spectral structure and text-speech alignment. During inference, FlowSE can operate with or without textual information, achieving impressive results in both scenarios, with further improvements when transcripts are available. Extensive experiments demonstrate that FlowSE significantly outperforms state-of-the-art generative methods, establishing a new paradigm for generative-based SE and demonstrating the potential of flow matching to advance the field. Our code, pre-trained checkpoints, and audio samples are available.
Distil-DCCRN: A Small-footprint DCCRN Leveraging Feature-based Knowledge Distillation in Speech Enhancement
Aug 08, 2024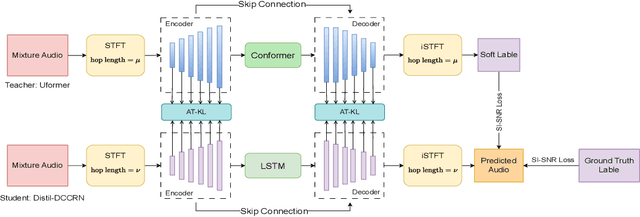
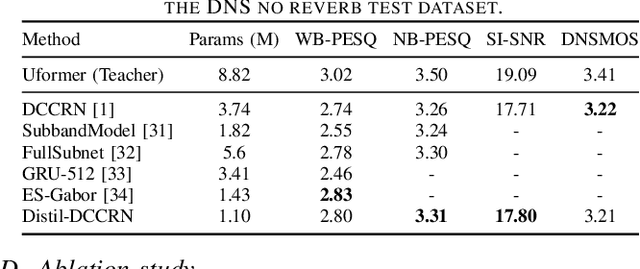

The deep complex convolution recurrent network (DCCRN) achieves excellent speech enhancement performance by utilizing the audio spectrum's complex features. However, it has a large number of model parameters. We propose a smaller model, Distil-DCCRN, which has only 30% of the parameters compared to the DCCRN. To ensure that the performance of Distil-DCCRN matches that of the DCCRN, we employ the knowledge distillation (KD) method to use a larger teacher model to help train a smaller student model. We design a knowledge distillation (KD) method, integrating attention transfer and Kullback-Leibler divergence (AT-KL) to train the student model Distil-DCCRN. Additionally, we use a model with better performance and a more complicated structure, Uformer, as the teacher model. Unlike previous KD approaches that mainly focus on model outputs, our method also leverages the intermediate features from the models' middle layers, facilitating rich knowledge transfer across different structured models despite variations in layer configurations and discrepancies in the channel and time dimensions of intermediate features. Employing our AT-KL approach, Distil-DCCRN outperforms DCCRN as well as several other competitive models in both PESQ and SI-SNR metrics on the DNS test set and achieves comparable results to DCCRN in DNSMOS.
RaD-Net 2: A causal two-stage repairing and denoising speech enhancement network with knowledge distillation and complex axial self-attention
Jun 11, 2024



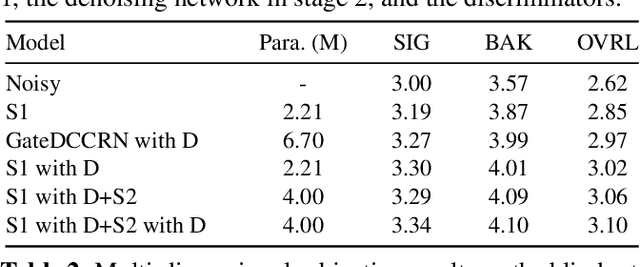
In real-time speech communication systems, speech signals are often degraded by multiple distortions. Recently, a two-stage Repair-and-Denoising network (RaD-Net) was proposed with superior speech quality improvement in the ICASSP 2024 Speech Signal Improvement (SSI) Challenge. However, failure to use future information and constraint receptive field of convolution layers limit the system's performance. To mitigate these problems, we extend RaD-Net to its upgraded version, RaD-Net 2. Specifically, a causality-based knowledge distillation is introduced in the first stage to use future information in a causal way. We use the non-causal repairing network as the teacher to improve the performance of the causal repairing network. In addition, in the second stage, complex axial self-attention is applied in the denoising network's complex feature encoder/decoder. Experimental results on the ICASSP 2024 SSI Challenge blind test set show that RaD-Net 2 brings 0.10 OVRL DNSMOS improvement compared to RaD-Net.
RaD-Net: A Repairing and Denoising Network for Speech Signal Improvement
Jan 09, 2024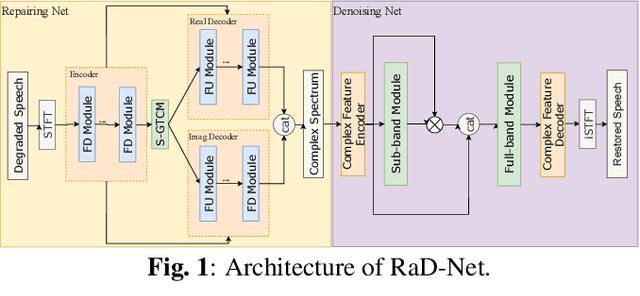
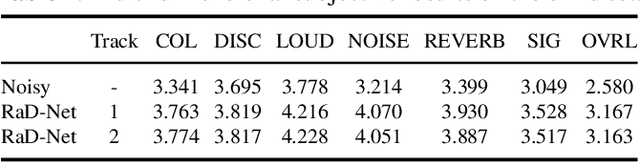
This paper introduces our repairing and denoising network (RaD-Net) for the ICASSP 2024 Speech Signal Improvement (SSI) Challenge. We extend our previous framework based on a two-stage network and propose an upgraded model. Specifically, we replace the repairing network with COM-Net from TEA-PSE. In addition, multi-resolution discriminators and multi-band discriminators are adopted in the training stage. Finally, we use a three-step training strategy to optimize our model. We submit two models with different sets of parameters to meet the RTF requirement of the two tracks. According to the official results, the proposed systems rank 2nd in track 1 and 3rd in track 2.
Two-stage Neural Network for ICASSP 2023 Speech Signal Improvement Challenge
Mar 14, 2023

In ICASSP 2023 speech signal improvement challenge, we developed a dual-stage neural model which improves speech signal quality induced by different distortions in a stage-wise divide-and-conquer fashion. Specifically, in the first stage, the speech improvement network focuses on recovering the missing components of the spectrum, while in the second stage, our model aims to further suppress noise, reverberation, and artifacts introduced by the first-stage model. Achieving 0.446 in the final score and 0.517 in the P.835 score, our system ranks 4th in the non-real-time track.
Two-step Band-split Neural Network Approach for Full-band Residual Echo Suppression
Mar 13, 2023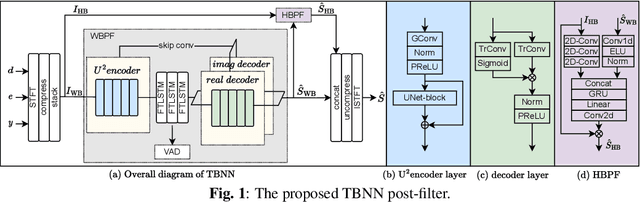

This paper describes a Two-step Band-split Neural Network (TBNN) approach for full-band acoustic echo cancellation. Specifically, after linear filtering, we split the full-band signal into wide-band (16KHz) and high-band (16-48KHz) for residual echo removal with lower modeling difficulty. The wide-band signal is processed by an updated gated convolutional recurrent network (GCRN) with U$^2$ encoder while the high-band signal is processed by a high-band post-filter net with lower complexity. Our approach submitted to ICASSP 2023 AEC Challenge has achieved an overall mean opinion score (MOS) of 4.344 and a word accuracy (WAcc) ratio of 0.795, leading to the 2$^{nd}$ (tied) in the ranking of the non-personalized track.