 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Collaborative Optimization and Expansion Network for Event-assisted Single-eye Expression Recognition
May 17, 2025In this paper, we proposed a Multi-modal Collaborative Optimization and Expansion Network (MCO-E Net), to use event modalities to resist challenges such as low light, high exposure, and high dynamic range in single-eye expression recognition tasks. The MCO-E Net introduces two innovative designs: Multi-modal Collaborative Optimization Mamba (MCO-Mamba) and Heterogeneous Collaborative and Expansion Mixture-of-Experts (HCE-MoE). MCO-Mamba, building upon Mamba, leverages dual-modal information to jointly optimize the model, facilitating collaborative interaction and fusion of modal semantics. This approach encourages the model to balance the learning of both modalities and harness their respective strengths. HCE-MoE, on the other hand, employs a dynamic routing mechanism to distribute structurally varied experts (deep, attention, and focal), fostering collaborative learning of complementary semantics. This heterogeneous architecture systematically integrates diverse feature extraction paradigms to comprehensively capture expression semantics. Extensive experiments demonstrate that our proposed network achieves competitive performance in the task of single-eye expression recognition, especially under poor lighting conditions.
Distil-DCCRN: A Small-footprint DCCRN Leveraging Feature-based Knowledge Distillation in Speech Enhancement
Aug 08, 2024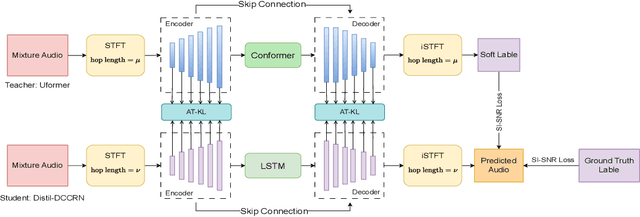
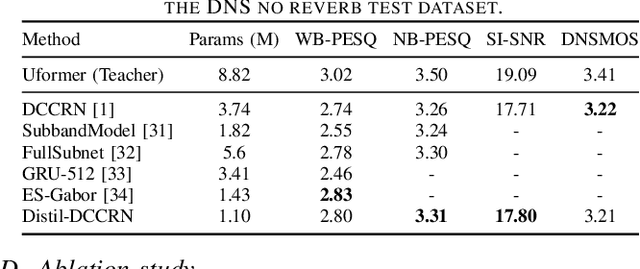

The deep complex convolution recurrent network (DCCRN) achieves excellent speech enhancement performance by utilizing the audio spectrum's complex features. However, it has a large number of model parameters. We propose a smaller model, Distil-DCCRN, which has only 30% of the parameters compared to the DCCRN. To ensure that the performance of Distil-DCCRN matches that of the DCCRN, we employ the knowledge distillation (KD) method to use a larger teacher model to help train a smaller student model. We design a knowledge distillation (KD) method, integrating attention transfer and Kullback-Leibler divergence (AT-KL) to train the student model Distil-DCCRN. Additionally, we use a model with better performance and a more complicated structure, Uformer, as the teacher model. Unlike previous KD approaches that mainly focus on model outputs, our method also leverages the intermediate features from the models' middle layers, facilitating rich knowledge transfer across different structured models despite variations in layer configurations and discrepancies in the channel and time dimensions of intermediate features. Employing our AT-KL approach, Distil-DCCRN outperforms DCCRN as well as several other competitive models in both PESQ and SI-SNR metrics on the DNS test set and achieves comparable results to DCCRN in DNSMOS.
An audio-quality-based multi-strategy approach for target speaker extraction in the MISP 2023 Challenge
Jan 08, 2024This paper describes our audio-quality-based multi-strategy approach for the audio-visual target speaker extraction (AVTSE) task in the Multi-modal Information based Speech Processing (MISP) 2023 Challenge. Specifically, our approach adopts different extraction strategies based on the audio quality, striking a balance between interference removal and speech preservation, which benifits the back-end automatic speech recognition (ASR) systems. Experiments show that our approach achieves a character error rate (CER) of 24.2% and 33.2% on the Dev and Eval set, respectively, obtaining the second place in the challenge.
MBTFNet: Multi-Band Temporal-Frequency Neural Network For Singing Voice Enhancement
Oct 06, 2023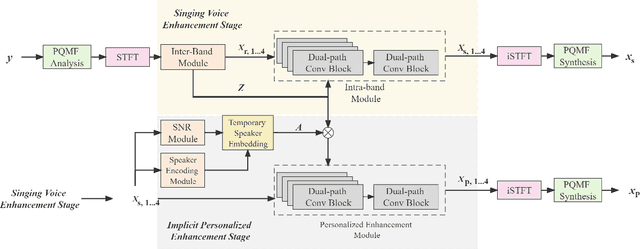
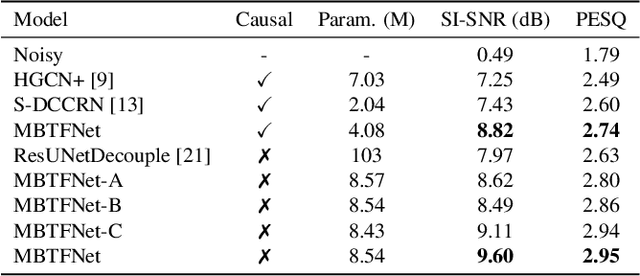
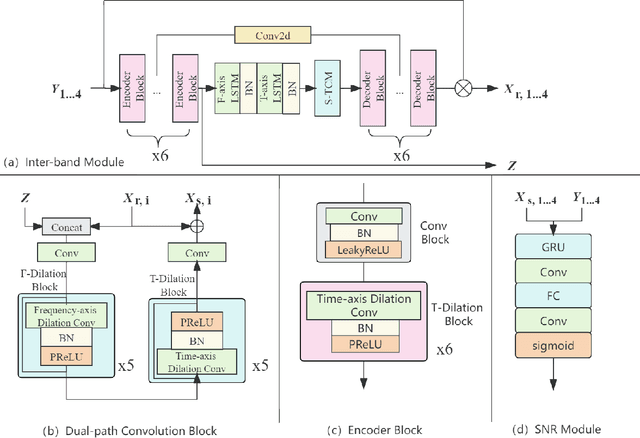
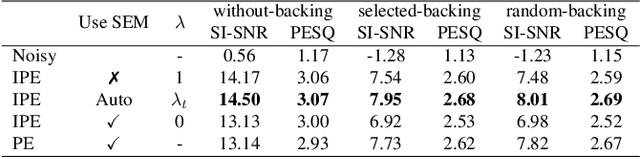
A typical neural speech enhancement (SE) approach mainly handles speech and noise mixtures, which is not optimal for singing voice enhancement scenarios. Music source separation (MSS) models treat vocals and various accompaniment components equally, which may reduce performance compared to the model that only considers vocal enhancement. In this paper, we propose a novel multi-band temporal-frequency neural network (MBTFNet) for singing voice enhancement, which particularly removes background music, noise and even backing vocals from singing recordings. MBTFNet combines inter and intra-band modeling for better processing of full-band signals. Dual-path modeling are introduced to expand the receptive field of the model. We propose an implicit personalized enhancement (IPE) stage based on signal-to-noise ratio (SNR) estimation, which further improves the performance of MBTFNet. Experiments show that our proposed model significantly outperforms several state-of-the-art SE and MSS models.
Two-stage Neural Network for ICASSP 2023 Speech Signal Improvement Challenge
Mar 14, 2023

In ICASSP 2023 speech signal improvement challenge, we developed a dual-stage neural model which improves speech signal quality induced by different distortions in a stage-wise divide-and-conquer fashion. Specifically, in the first stage, the speech improvement network focuses on recovering the missing components of the spectrum, while in the second stage, our model aims to further suppress noise, reverberation, and artifacts introduced by the first-stage model. Achieving 0.446 in the final score and 0.517 in the P.835 score, our system ranks 4th in the non-real-time track.